WARNING
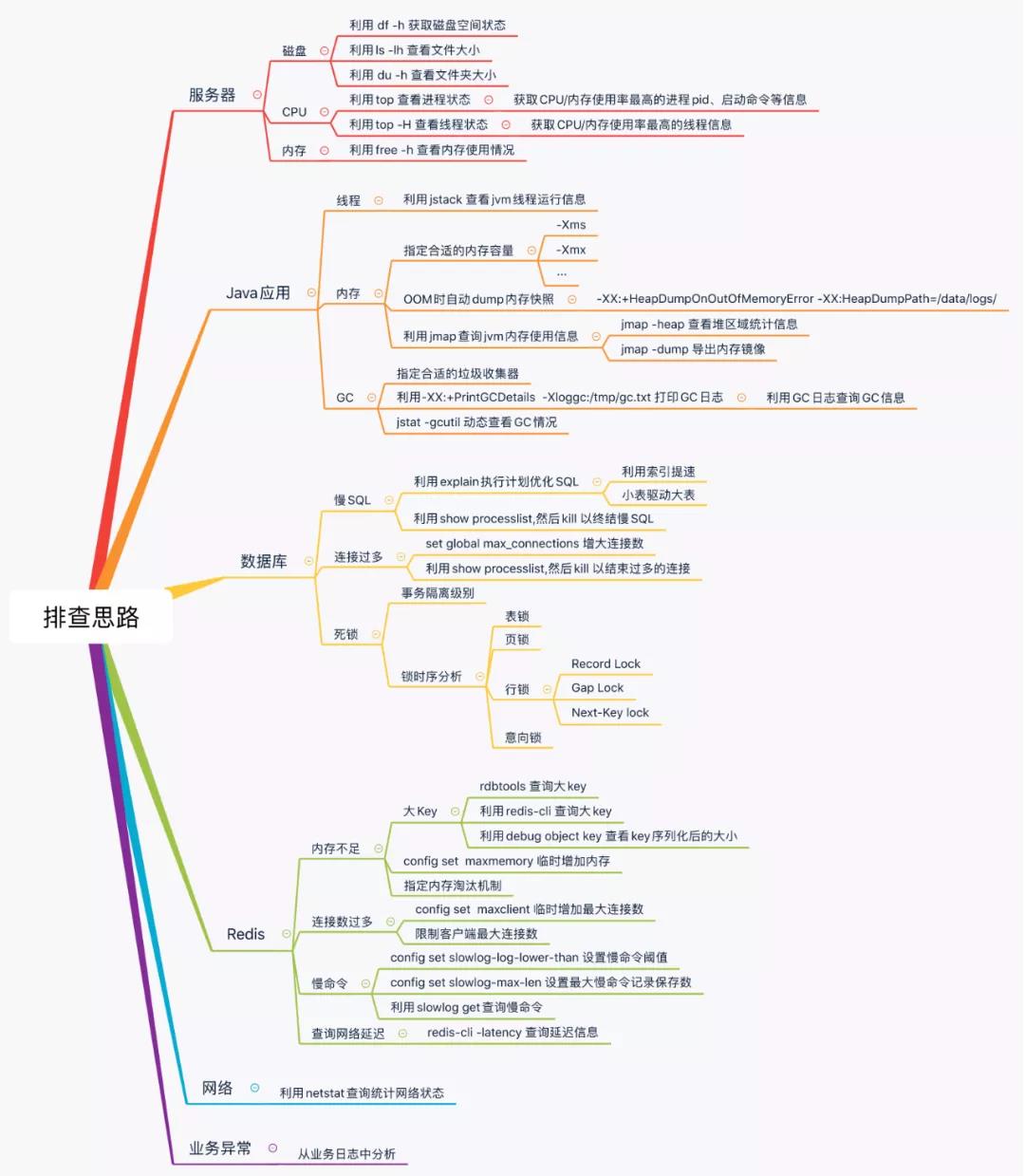
简介:有哪些常见的线上故障?如何快速定位问题?本文详细总结工作中的经验,从服务器、Java应用、数据库、Redis、网络和业务六个层面分享线上故障排查的思路和技巧。较长,同学们可收藏后再看。
线上定位问题时,主要靠监控和日志。一旦超出监控的范围,则排查思路很重要,按照流程化的思路来定位问题,能够让我们在定位问题时从容、淡定,快速的定位到线上的问题
# 一、服务器
# 1、磁盘
问题现象: 当磁盘容量不足的时候,应用时常会抛出如下的异常信息:
java.io.IOException: 磁盘空间不足
或者类似如下警告信息:

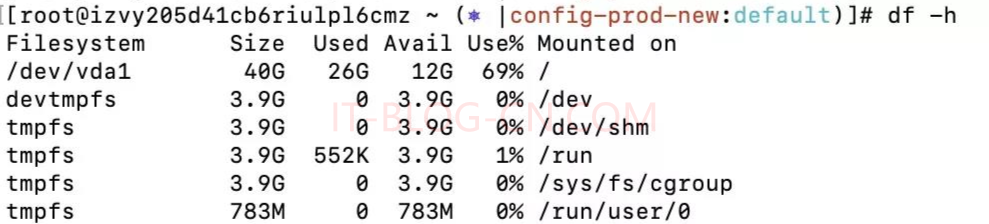
排查思路:【1】利用df -h查询磁盘状态: 可知/路径下占用量最大。
| 参数 | 说明 |
|---|---|
| -a | 列出所有文件系统 |
| -h | 使用人类可读的样式,按照1024的进制 |
| -H | 和-h一致,按照 1000的进制 |
| 参数 | 说明 |
|---|---|
| Filesystem | 文件系统 |
| Size | 容量 |
| Used | 使用量 |
| Avail | 可用量 |
| Use% | 使用率 |
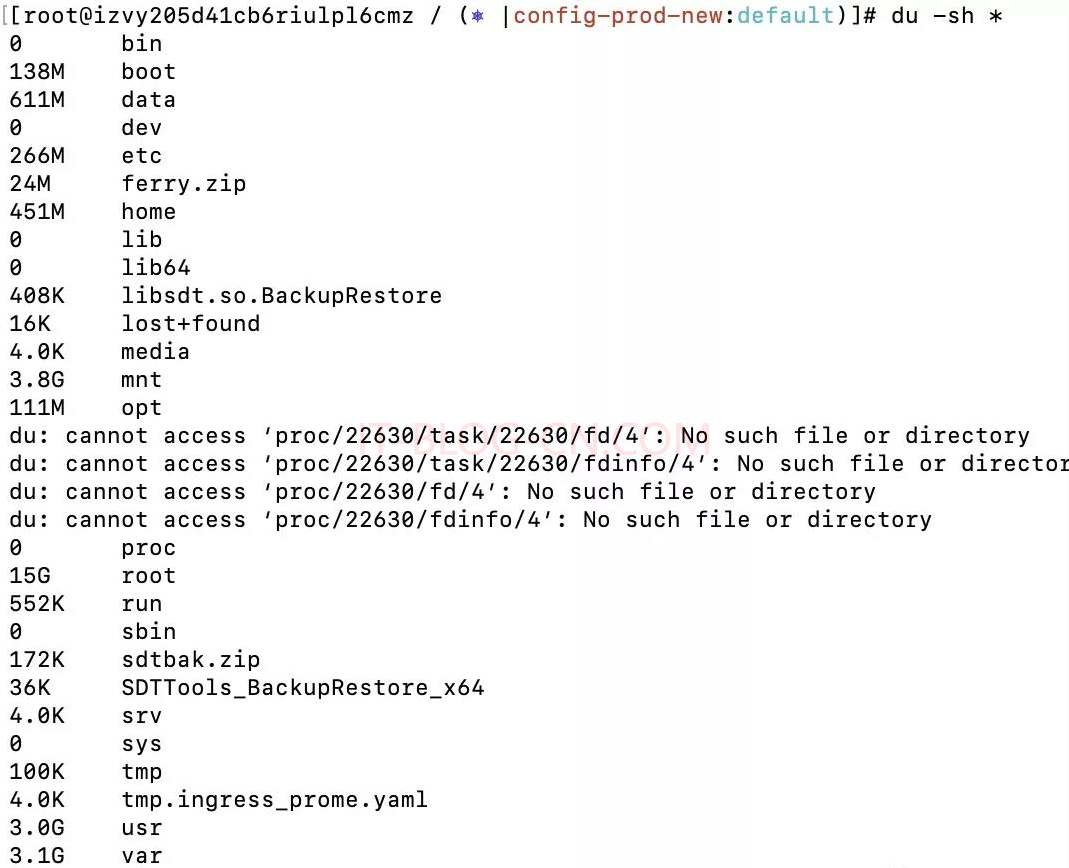
【2】利用du -sh *查看文件夹大小: 可知root文件夹占用空间最大,然后层层递推找到对应的最大的一个或数个文件夹。
| 参数 | 说明 |
|---|---|
| -s | 仅显示总值 |
| -h | 使用人类可读的样式,按照1024的进制 |
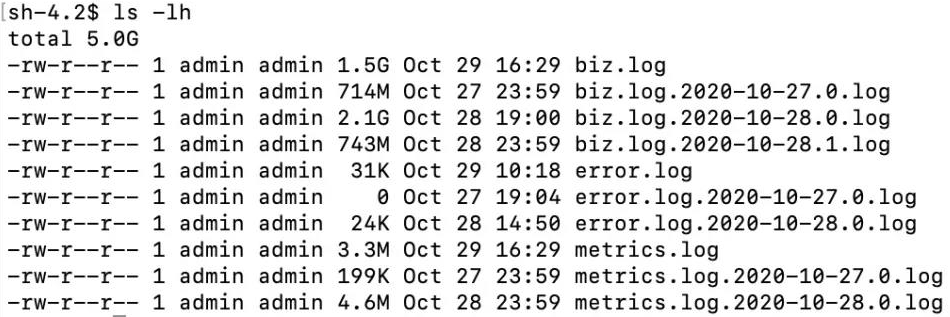
【3】利用ls -lh查看文件大小: 可以找到最大的文件是日志文件,然后使用rm指令进行移除以释放磁盘。
| 启动参数 | 说明 |
|---|---|
| -l | 仅显示总值 |
| -h | 使用人类可读的样式,按照1024的进制 |
| 进程内指令参数 | 说明 |
|---|---|
| H | 以线程的维度进行查看 |
| N | 按照pid进行排序 |
| M | 按照内存使用率进行排序 |
| P | 按照CPU使用率进行排序 |
# 2、CPU 过高
问题现象: 当CPU过高的时候,接口性能会快速下降,同时监控也会开始报警。
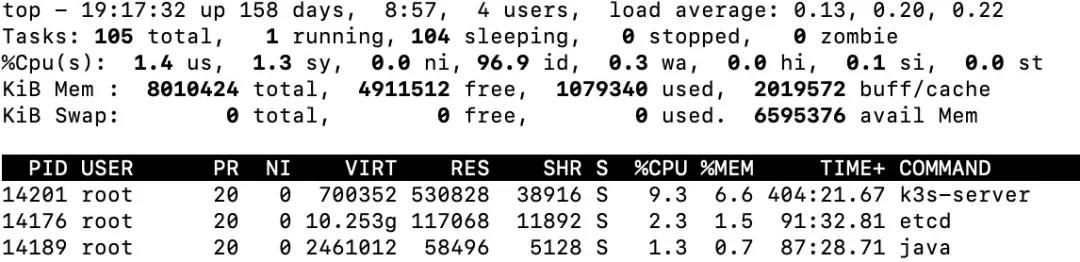
排查思路:【1】利用top查询CPU使用率最高的进程: 从而可以得知pid为14201的进程使用CPU最高。
| 参数 | 说明 |
|---|---|
| -n | 指定top结果输出的次数 |
| -p | 指定需要查看的进程pid |
| 参数 | 说明 |
|---|---|
| PID | 进程ID |
| USER | 进程所有者的用户名称 |
| PR | 进程的动态优先级 |
| NI | 进程的静态优先级 |
| VIRT | 使用的虚拟内存数量 |
| RES | 使用的物理内存数量 |
| SHR | 使用的共享内存数量 |
| S | 进程状态:D:不可中断的睡眠状态 R:运行 S:睡眠 T:跟踪/停止 Z:僵尸进程 |
| %CPU | 使用的cpu使用率 |
| %MEM | 使用的内存使用率 |
| TIME+ | 进程使用的cpu累计时长 |
| COMMAND | 启动进程使用的命令行 |
# 二、应用层面
# 1、Tomcat 假死案例
发现问题: 监控平台发现某个Tomcat节点已经无法采集到数据,连上服务器查看服务器进程还在,netstat -anop|grep 8001端口也有监听,查看日志打印时断时续。
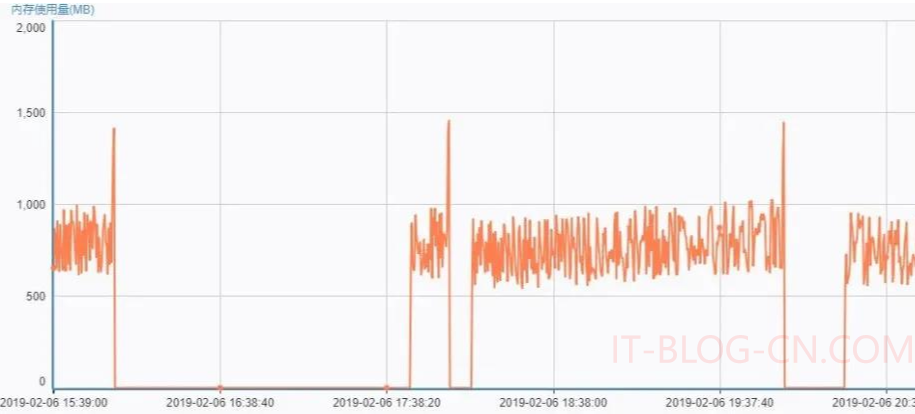
查询日志: 查看NG日志,发现有数据进入到当前服务器(有8001和8002两个Tomcat),NG显示8002节点访问正常,8001节点有404错误打印,说明Tomcat已经处于假死状态,这个Tomcat已经不能正常工作了。
过滤Tomcat节点的日志,发现有OOM的异常,但是重启后,有时候Tomcat挂掉后,又不会打印如下OOM的异常:
TopicNewController.getTopicSoftList() error="Java heap space
From class java.lang.OutOfMemoryError"appstore_apitomcat
2
获取内存快照: 在一次OOM发生后立刻抓取内存快照,需要执行命令的用户与JAVA进程启动用户是同一个,否则会有异常:
/data/program/jdk/bin/jmap -dump:live,format=b,file=/home/www/jmaplogs/jmap-8001-2.bin 18760
ps -ef|grep store.cn.xml|grep -v grep|awk '{print $2}'|xargs /data/program/jdk-1.8.0_11/bin/jmap -dump:live,format=b,file=api.bin
2
3
内存dump文件比较大,有1.4G,先压缩,然后拉取到本地用7ZIP解压。linux压缩dump为.tgz。在windows下用7zip需要经过2步解压:
.bin.tgz---.bin.tar--.bin
分析内存快照文件: 使用Memory Analyzer解析dump文件,发现有很明显的内存泄漏提示。
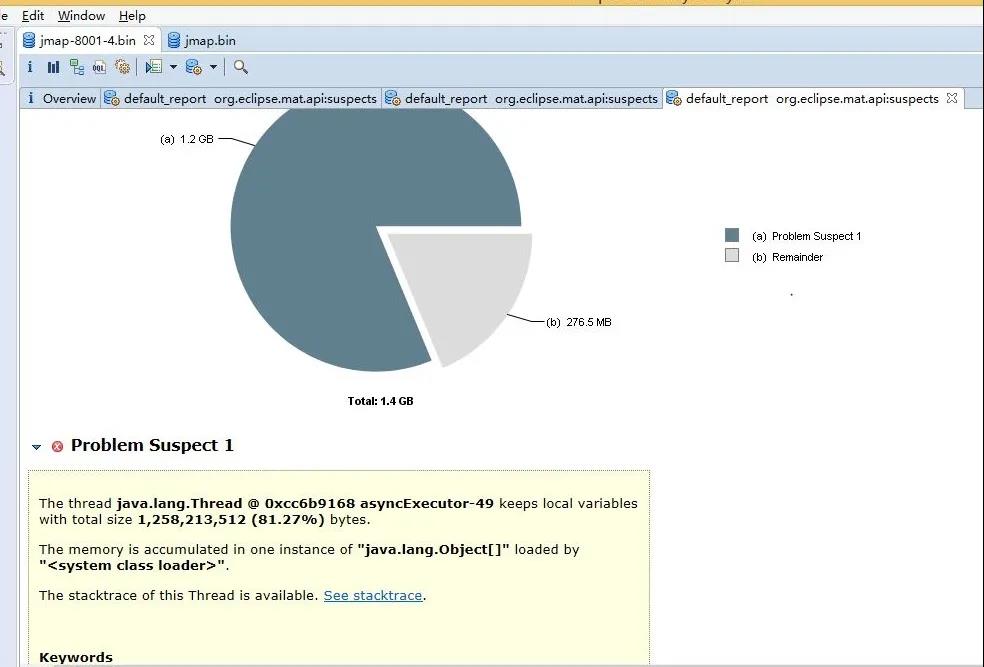
点击查看详情,发现定位到了代码的具体某行,一目了然:
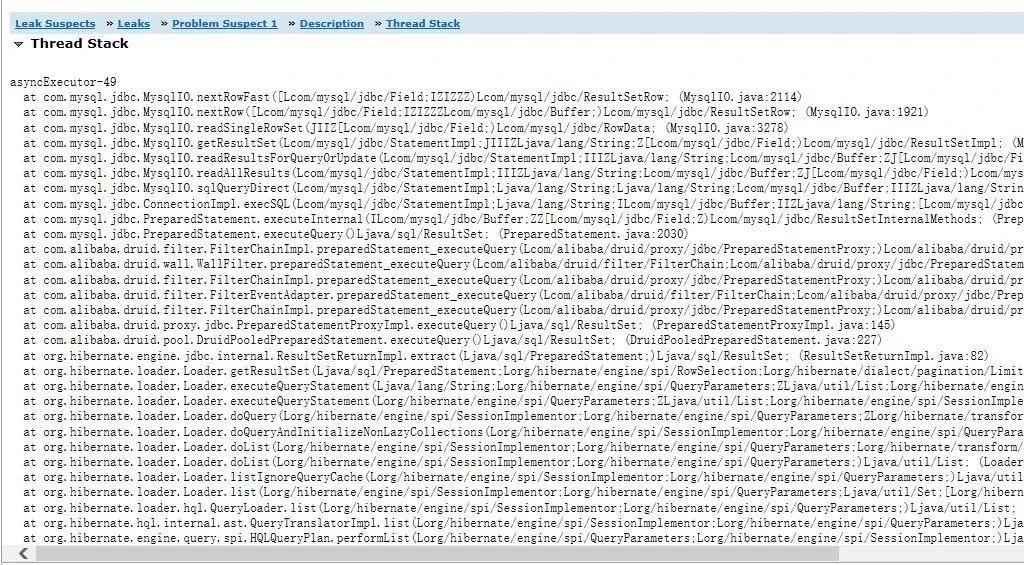
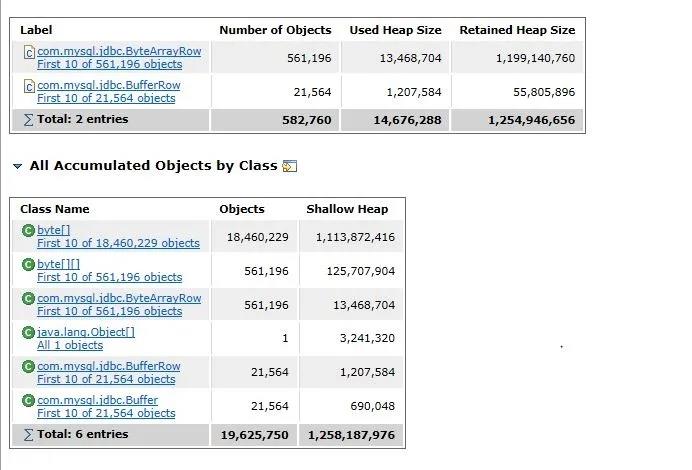
查看shallow heap与retained heap能发现生成了大量的Object(810325个对象),后面分析代码发现是上报softItem对象超过300多万个对象,在循环的时候,所有的数据全部保存在某个方法中无法释放,导致内存堆积到1.5G,从而超过了JVM分配的最大数,从而出现OOM。
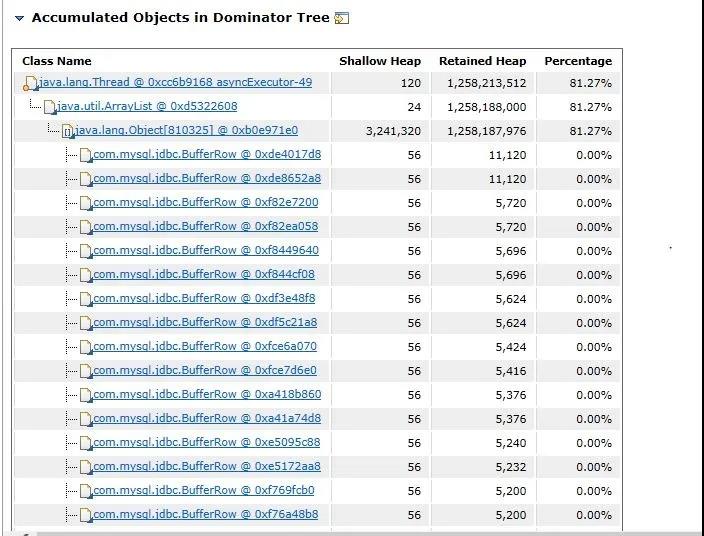
java.lang.Object[810325] @ 0xb0e971e0
不要在线上使用jmap手动抓取内存快照,其一系统OOM时手工触发已经来不及,另外在生成dump文件时会占用系统内存资源,导致系统崩溃。只需要在JVM启动参数中提取设置如下参数,一旦OOM触发会自动生成对应的文件,用MAT分析即可。
# 内存OOM时,自动生成dump文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/logs/
2
如果Young GC比较频繁,5S内有打印一条,或者有Old GC的打印,代表内存设置过小或者有内存泄漏,此时需要抓取内存快照进行分享。
# 2、应用 CPU过高
问题发现: 监控告警提示
查找问题进程: 利用top查到占用cpu最高的进程pid为14,结果图如下:

查找问题线程: 利用top -H -p查看进程内占用cpu最高线程,从下图可知,问题线程主要是activeCpu Thread,其pid为417。

查询线程详细信息:
● 首先利用printf "%x n"将tid换为十六进制:xid。
● 再利用jstack | grep nid=0x -A 10查询线程信息(若进程无响应,则使用jstack -f),信息如下:

分析代码: 由上一步可知该问题是由CpuThread.java类引发的,故查询项目代码,获得如下信息:根据代码和日志分析,可知是由于限制值max太大,致使线程长时间循环执行,从而导致问题出现。
public class CpuThread extends Thread {
private int max = Integer.MAX_VALUE;
private long sleepTime;
public CpuThread(String name, long sleepTime){
setName(name);
this.sleepTime = sleepTime;
}
@Override
public void run() {
int i = 0;
while(true) {
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
i = i++;
if (i >= max) {
return
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 三、MySql
# 1、死锁
发现问题: 最近线上随着流量变大,突然开始报如下异常,即发生了死锁问题:
Deadlock found when trying to get lock; try restarting transaction ;
问题分析:【1】查询事务隔离级别: 利用select @@tx_isolation命令获取到数据库隔离级别信息:
MySQL [(none)]> select @@tx_isolation
+-------------------+
| @@tx_isolation |
+-------------------+
| READ-COMMITTED |
+-------------------+
2
3
4
5
6
【2】查询数据库死锁日志: 利用show engine innodb status命令获取到如下死锁信息:
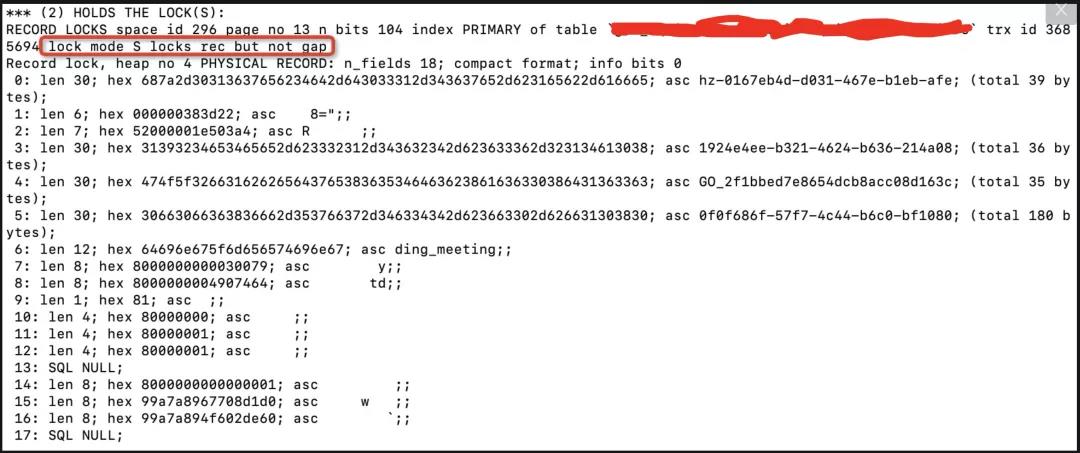
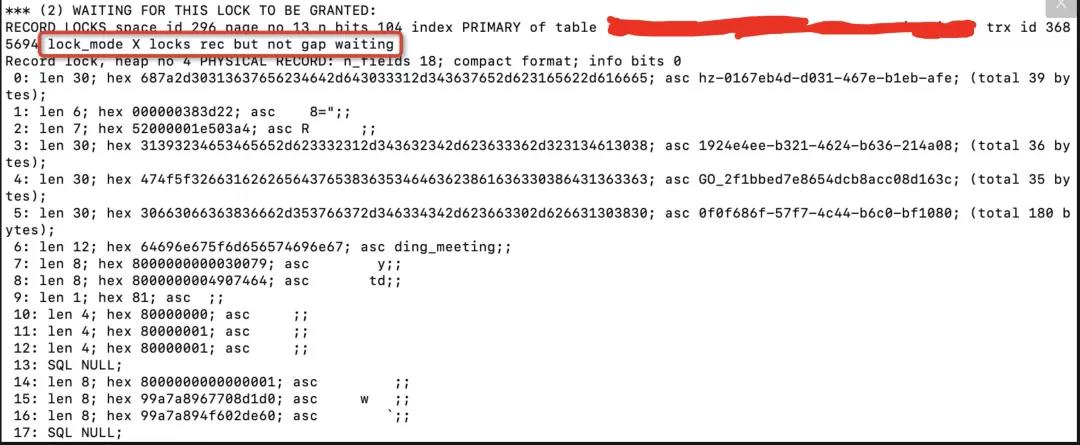
由上可知,是由于两个事物对这条记录同时持有S锁(共享锁)的情况下,再次尝试获取该条记录的X锁(排它锁),从而导致互相等待引发死锁。
【3】分析代码: 根据死锁日志的SQL语句,定位获取到如下伪代码逻辑:
@Transactional(rollbackFor = Exception.class)
void saveOrUpdate(MeetingInfo info) {
// insert ignore into table values (...)
int result = mapper.insertIgnore(info);
if (result>0) {
return;
}
// update table set xx=xx where id = xx
mapper.update(info);
}
2
3
4
5
6
7
8
9
10
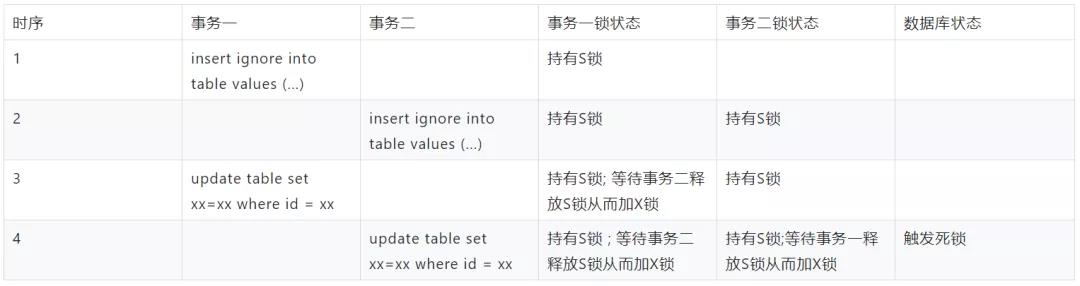
【4】获得结论: 分析获得产生问题的加锁时序如下,然后修改代码实现以解决该问题。
# 2、慢 SQL
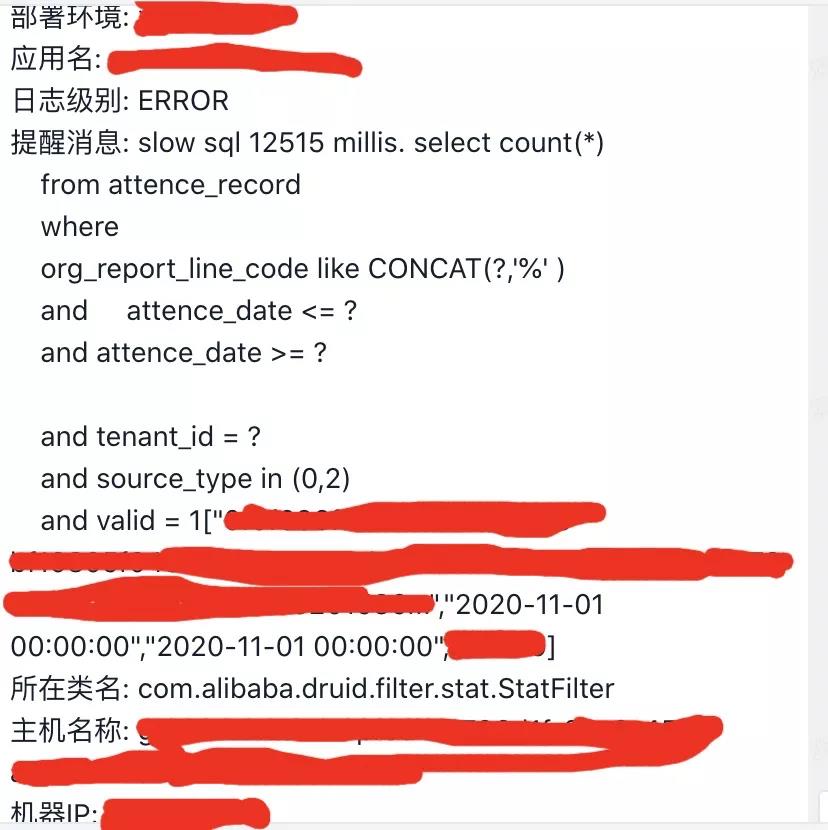
发现问题: 应用TPS下降,并出现SQL执行超时异常或者出现了类似如下的告警信息,则常常意味着出现了慢SQL。
问题分析:分析执行计划: 利用explain指令获得该SQL语句的执行计划,根据该执行计划,可能有两种场景。
■ SQL不走索引或扫描行数过多等致使执行时长过长。
■ SQL没问题,只是因为事务并发导致等待锁,致使执行时长过长。
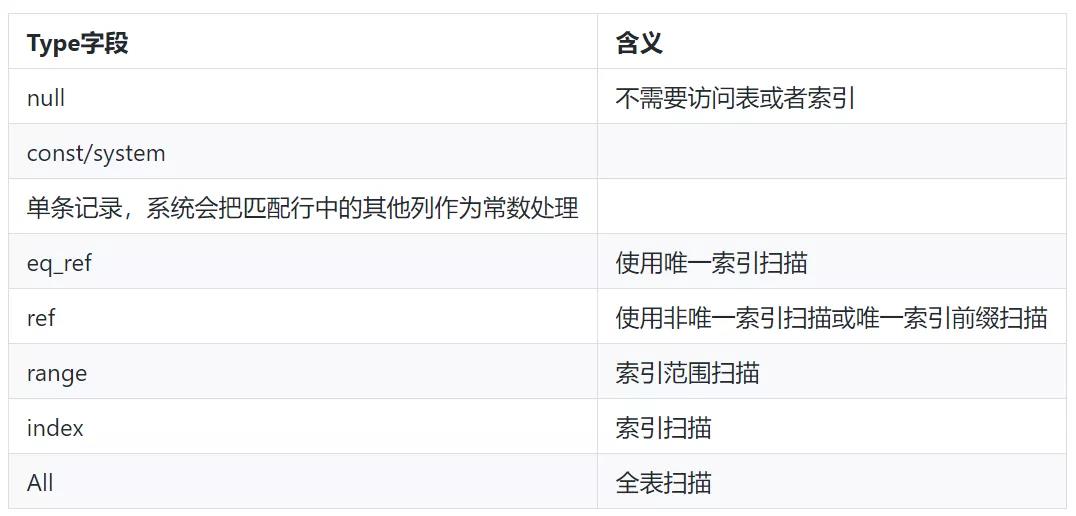
【1】场景一:优化SQL: 通过增加索引,调整SQL语句的方式优化执行时长, 例如下的执行计划:

该SQL的执行计划的type为ALL,同时根据以下type语义,可知无索引的全表查询,故可为其检索列增加索引进而解决。
【2】场景二:查询当前使用情况: 可以通过查看如下3张表做相应的处理
-- 当前运行的所有事务
select * from information_schema.innodb_trx;
-- 当前出现的锁
SELECT * FROM information_schema.INNODB_LOCKS;
-- 锁等待的对应关系
select * from information_schema.INNODB_LOCK_WAITS;
2
3
4
5
6
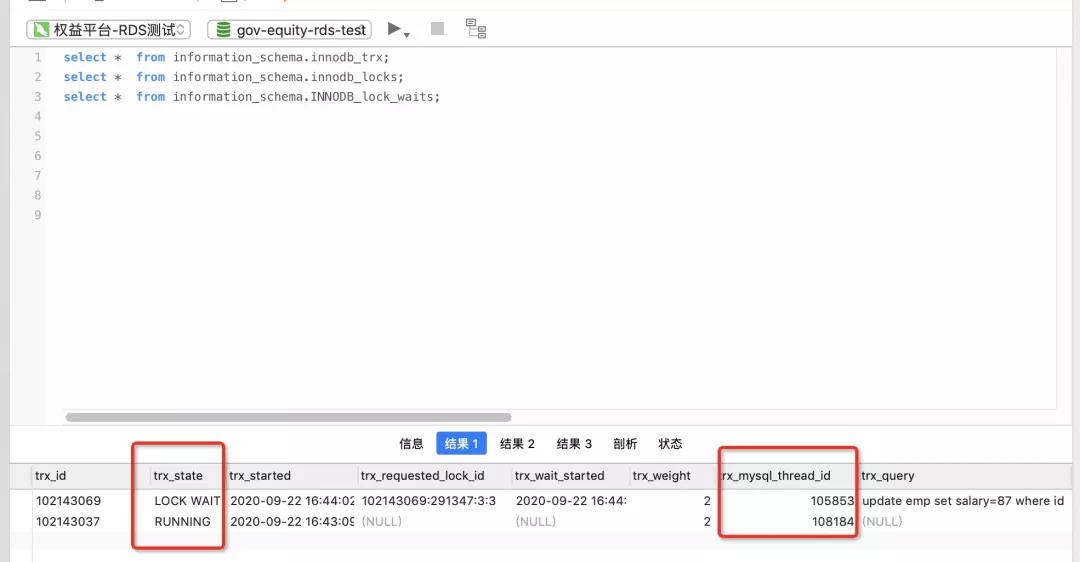
查看事务锁类型索引的详细信息:lock_table字段能看到被锁的索引的表名,lock_mode可以看到锁类型是X锁,lock_type可以看到是行锁record。

分析: 根据事务情况,得到表信息,和相关的事务时序信息:
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`salary` int(10) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`(191)) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4;
2
3
4
5
6
7
8
A事物锁住一条记录,不提交,B事物需要更新此条记录,此时会阻塞,如下图是执行顺序:
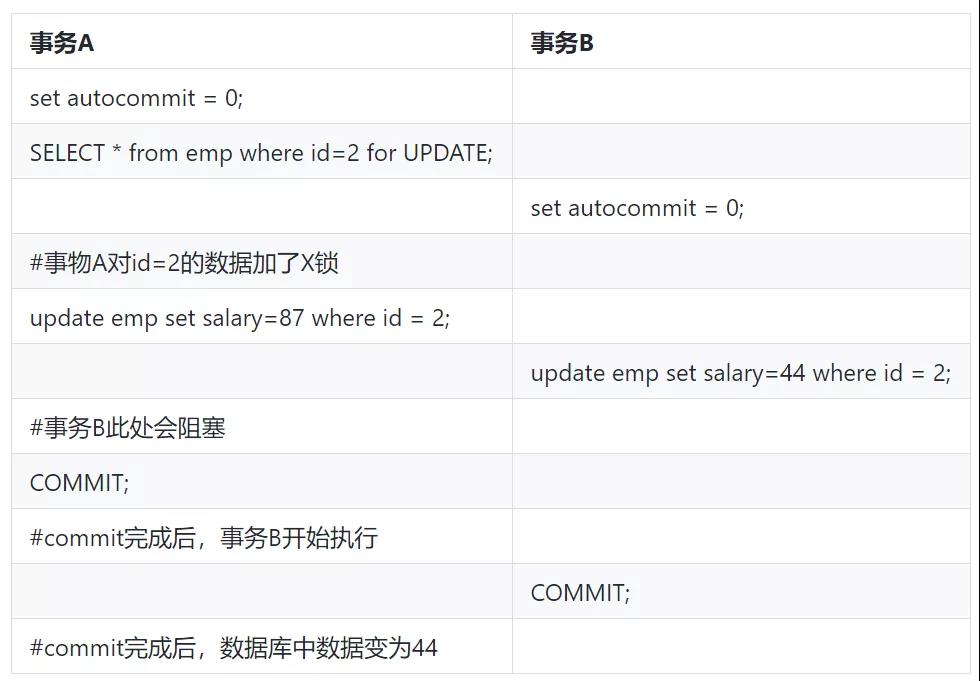
解决方案:
【1】修改方案: 由前一步的结果,分析事务间加锁时序,例如可以通过tx_query字段得知被阻塞的事务SQL,trx_state得知事务状态等,找到对应代码逻辑,进行优化修改。
【2】临时修改方案: trx_mysql_thread_id是对应的事务sessionId,可以通过以下命令杀死长时间执行的事务,从而避免阻塞其他事务执行。
kill 105853
# 3、连接数过多
发现问题: 常出现too many connections异常,数据库连接到达最大连接数。
解决方案: 通过set global max_connections=XXX增大最大连接数。先利用show processlist获取连接信息,然后利用kill杀死过多的连。常用脚本如下:
#排序数据库连接的数目
mysql -h127.0.0.0.1 -uabc_test -pXXXXX -P3306 -A -e 'show processlist'| awk '{print $4}'|sort|uniq -c|sort -rn|head -10
2
# 四、Redis
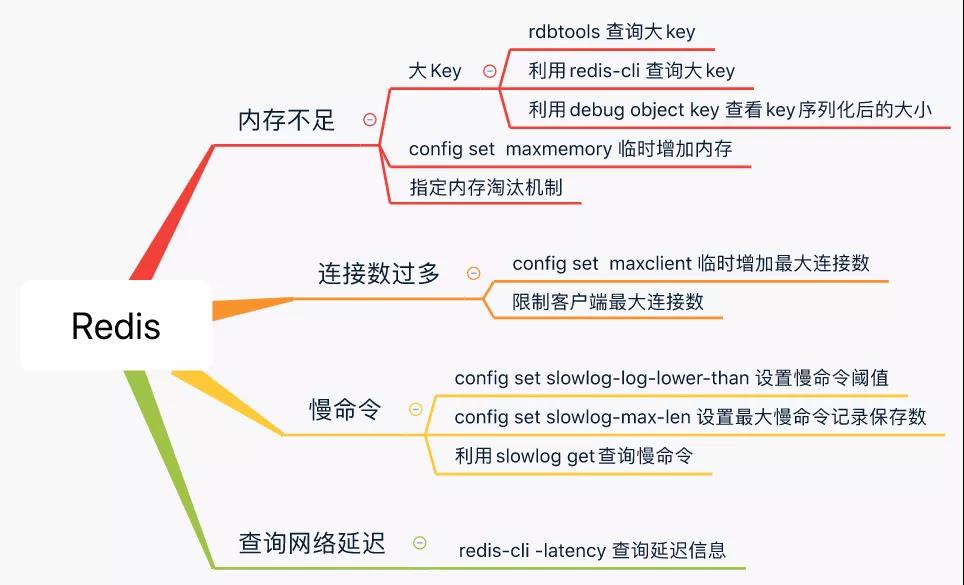
# 1、内存告警
时常会出现下述异常提示信息:
OOM command not allowed when used memory
设置合理的内存大小: 设置maxmemory和相对应的回收策略算法,设置最好为物理内存的3/4,或者比例更小,因为redis复制数据等其他服务时,也是需要缓存的。以防缓存数据过大致使redis崩溃,造成系统出错不可用。
【1】通过redis.conf配置文件指定
maxmemory xxxxxx
【2】通过命令修改
config set maxmemory xxxxx
设置合理的内存淘汰策略:
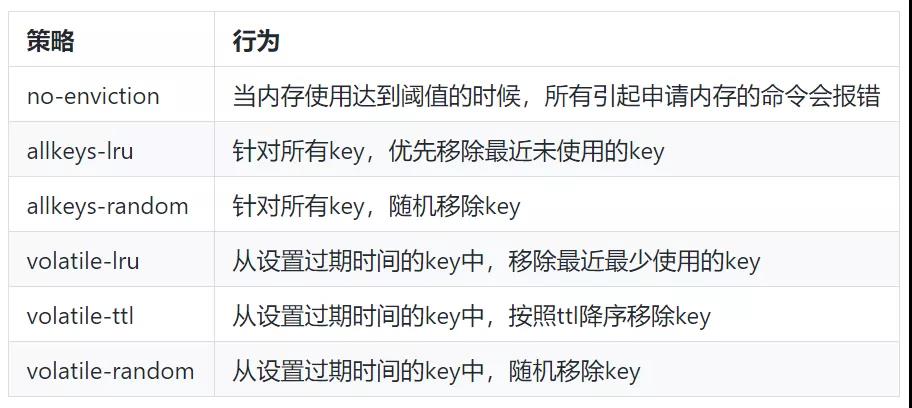
通过redis.conf配置文件指定
maxmemory-policy allkeys-lru
【3】查看大key:有工具的情况下:安装工具dbatools redisTools,列出最大的前N个key
/data/program/dbatools-master/redisTools/redis-cli-new -h <ip> -p <port> --bigkeys --bigkey-numb 3
得到如下结果:
Sampled 122114 keys in the keyspace!
Total key length in bytes is 3923725 (avg len 32.13)
Biggest string Key Top 1 found 'xx1' has 36316 bytes
Biggest string Key Top 2 found 'xx2' has 1191 bytes
Biggest string Key Top 3 found 'xx3' has 234 bytes
Biggest list Key Top 1 found 'x4' has 204480 items
Biggest list Key Top 2 found 'x5' has 119999 items
Biggest list Key Top 3 found 'x6' has 60000 items
Biggest set Key Top 1 found 'x7' has 14205 members
Biggest set Key Top 2 found 'x8' has 292 members
Biggest set Key Top 3 found 'x,7' has 21 members
Biggest hash Key Top 1 found 'x' has 302939 fields
Biggest hash Key Top 2 found 'xc' has 92029 fields
Biggest hash Key Top 3 found 'xd' has 39634 fields
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
原生命令为:
/usr/local/redis-3.0.5/src/redis-cli -c -h <ip> -p <port> --bigkeys
分析rdb文件中的全部key/某种类型的占用量:
rdb -c memory dump.rdb -t list -f dump-formal-list.csv
查看某个key的内存占用量:
[root@iZbp16umm14vm5kssepfdpZ redisTools]# redis-memory-for-key -s <ip> -p <port> x
Key x
Bytes 4274388.0
Type hash
Encoding hashtable
Number of Elements 39634
Length of Largest Element 29
2
3
4
5
6
7
无工具的情况下可利用以下指令评估key大小:
debug object key
# 2、Redis的慢命令
设置Redis的慢命令的时间阈值(单位:微妙)
【1】通过redis.conf配置文件方式
# 执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。
slowlog-log-lower-than 1000
# 最多能保存多少条日志
slowlog-max-len 200
2
3
4
5
【2】通过命令方式
slowlog get
查看Redis的慢命令
slowlog get
# 3、连接过多
【1】通过redis.conf配置文件指定最大连接数
maxclients 10000
【2】通过命令修改
config set maxclients xxx
# 4、线上Redis节点挂掉一个之后的处理流程
【1】查看节点状态: 执行cluster nodes后发现会有一个节点dead
[rgp@iZ23rjcqbczZ ~]$ /data/program/redis-3.0.3/bin/redis-cli -c -h <ip> -p <port>
ip:port> cluster nodes
9f194f671cee4a76ce3b7ff14d3bda190e0695d5 m1 master - 0 1550322872543 65 connected 10923-16383
a38c6f957f2706f269cf5d9b628586a9372265e9 s1 slave 9f194f671cee4a76ce3b7ff14d3bda190e0695d5 0 1550322872943 65 connected
77ce43ec23f25f77ec68fe71ae3cb799e7300c6d s2 slave 03d72a3a5050c85e280e0bbeb687056b84f10077 0 1550322873543 63 connected
03d72a3a5050c85e280e0bbeb687056b84f10077 m2 master - 0 1550322873343 63 connected 5461-10922
5799070c6a63314296f3661b315b95c6328779f7 :0 slave,fail,noaddr 6147bf416ef216b6a1ef2f100d15de4f439b7352 1550320811474 1550320808793 49 disconnected
6147bf416ef216b6a1ef2f100d15de4f439b7352 m3 myself,master - 0 0 49 connected 0-5460
2
3
4
5
6
7
8
【2】移除错误节点:
(1)一开始执行如下的删除操作失败,需要针对于每一个节点都执行cluster forget:
ip:port> cluster forget 61c70a61ad91bbac231e33352f5bdb9eb0be6289
CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点
2
(2)删除挂掉的节点:
[rgp@iZ23rjcqbczZ ~]$ /data/program/redis-3.0.3/bin/redis-trib.rb del-node m3 b643d7baa69922b3fdbd1e25ccbe6ed73587b948
>>> Removing node b643d7baa69922b3fdbd1e25ccbe6ed73587b948 from cluster m3
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
2
3
4
(3)清理掉节点配置目录下的rdb aof nodes.conf等文件,否则节点的启动会有如下异常:
[ERR] Node s3 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
【3】恢复节点:
(1)后台启动Redis某个节点:
/data/program/redis-3.0.3/bin/redis-server /data/program/redis-3.0.3/etc/7001/redis.conf &
(2)将该节点添加进集群:
[root@iZ23rjcqbczZ rgp]# /data/program/redis-3.0.3/bin/redis-trib.rb add-node --slave --master-id 6147bf416ef216b6a1ef2f100d15de4f439b7352 s3 m3
>>> Adding node s3 to cluster m3
>>> Performing Cluster Check (using node m3)
M: 6147bf416ef216b6a1ef2f100d15de4f439b7352 m3
slots:0-5460 (5461 slots) master
0 additional replica(s)
M: 9f194f671cee4a76ce3b7ff14d3bda190e0695d5 m1
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: a38c6f957f2706f269cf5d9b628586a9372265e9 s1
slots: (0 slots) slave
replicates 9f194f671cee4a76ce3b7ff14d3bda190e0695d5
S: 77ce43ec23f25f77ec68fe71ae3cb799e7300c6d s2
slots: (0 slots) slave
replicates 03d72a3a5050c85e280e0bbeb687056b84f10077
M: 03d72a3a5050c85e280e0bbeb687056b84f10077 m2
slots:5461-10922 (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node s3 to make it join the cluster.
Waiting for the cluster to join..
>>> Configure node as replica of m3.
[OK] New node added correctly.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
● s3:本次待添加的从节点ip:port
● m3:主节点的ip:port
● 6147bf416ef216b6a1ef2f100d15de4f439b7352:主节点编号
# 五、网络
# 排查流程
现象出现: 在非压测或者高峰期的情况下,突然出现大量的503等错误码,页面无法打开。
查看是否遭受了DOS攻击: 当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行。
netstat -n|grep SYN_RECV
查看TCP连接状态:
【1】首先利用以下查看tcp总连接数,判断连接数是否正常:
【2】然后利用如下命令判断各个状态的连接数是否正常:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
【3】根据上述信息,如果TIME_WAIT状态数量过多,可利用如下命令查看连接CLOSE_WAIT最多的IP地址,再结合业务分析问题:
netstat -n|grep TIME_WAIT|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -10
# 六、业务异常日志
出现问题: 主要是通过业务日志监控主动报警或者是查看错误日志被动发现:
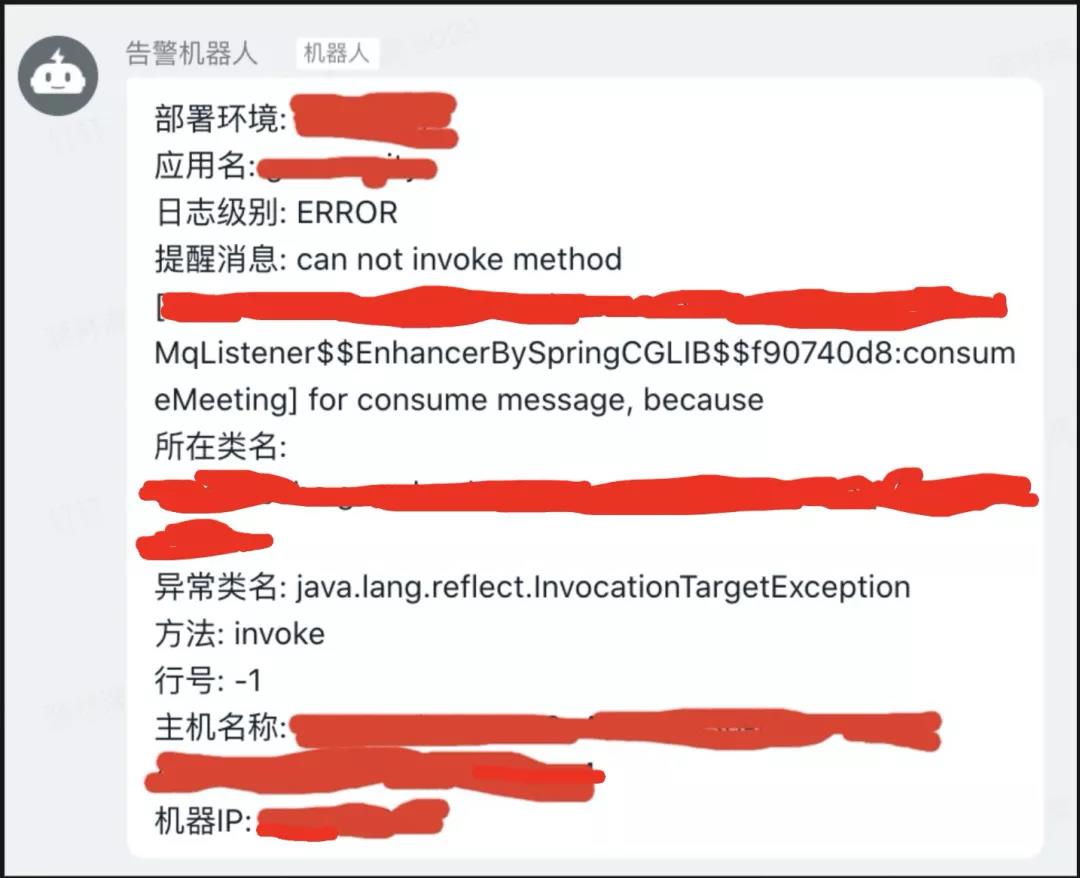
日志分析: 日志格式如下:
<property name="METRICS_LOG_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS}|${APP_NAME}|%X{className}|%X{methodName}|%X{responseStatus}|%X{timeConsume}|%X{traceId}|%X{errorCode}|%msg%n"/>
<property name="ERROR_LOG_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS}|%-5level|%X{traceId}|${APP_NAME}|%serverIp|%X{tenantId}|%X{accountId}|%thread|%logger{30}|%msg%n"/>
<!--日志格式 时间|级别|链路id|应用名|服务器ip|租户id|用户id|线程名称|logger名称|业务消息 -->
<property name="BIZ_LOG_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS}|%-5level|%X{traceId}|${APP_NAME}|%serverIp|%X{tenantId}|%X{accountId}|%thread|%logger{30}|%msg%n"/>
2
3
4
5
6
7
8
9
10
11
在日志文件中检索异常: 利用如下命令可获得异常的详细信息
cat error.log|grep -n " java.lang.reflect.InvocationTargetException"
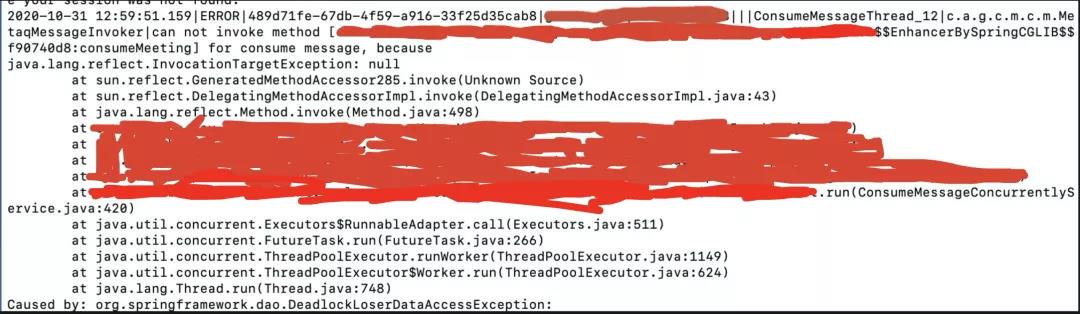
根据日志格式和日志信息,可获得traceId为489d71fe-67db-4f59-a916-33f25d35cab8,然后利用以下指令获取整个流程的日志信息:
cat biz.log |grep -n '489d71fe-67db-4f59-a916-33f25d35cab8'
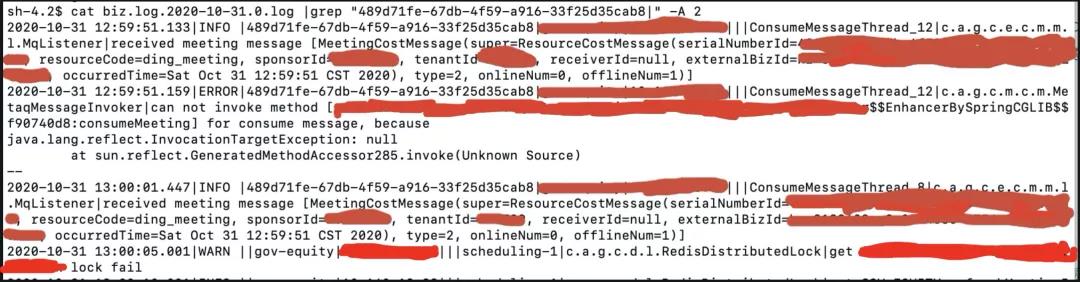
代码分析: 然后根据上述流程日志找到对应的代码实现,然后进行具体的业务分析。
← 网站的性能优化 HickWall 详解 →