# 一、业务场景
场景一: 应用出海,数据库是否需要出海,不出海的情况下,由于数据数据合规要求,数据不允许直接跨region访问DB,只能依靠DRC的单向/双向的同步数据,上海到新加坡的延迟在90ms,也就是说这段时间内,两个region之间的数据是不一致的。对于一些海外不需要的功能,其实直接Mock掉,数据库就不需要出海。存在延迟,适合用户延迟不敏感的应用
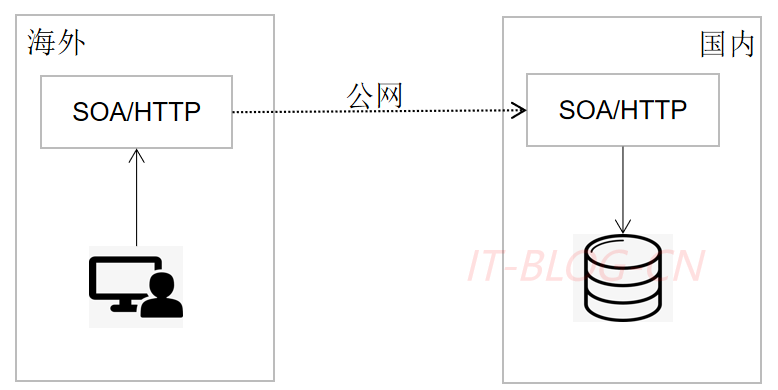
场景二: 数据库出海,海外应用只读,国内数据复制到海外。海外代码改造Mock写操作。
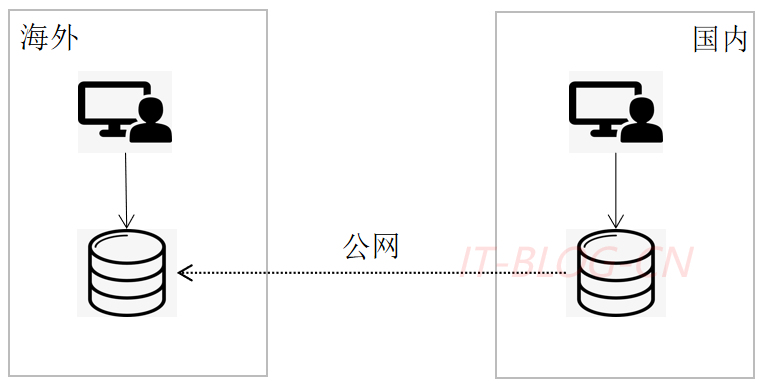
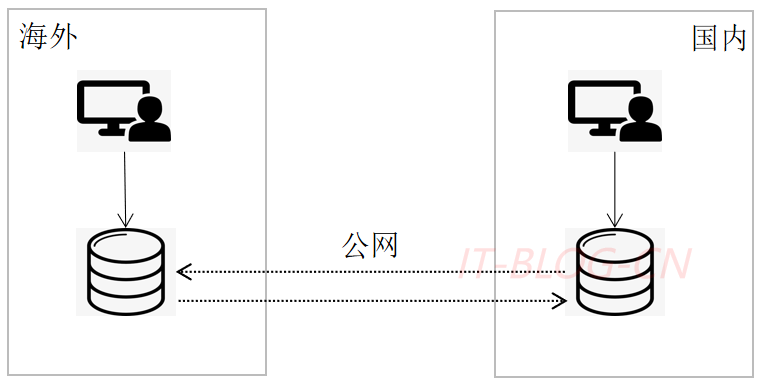
场景三: 海外应用读写,国内和国外数据双向复制,间接实现灾备,代码无需改造。
成本对比
| AWS出口流量 | 数据库成本 | DRC机器(共享) | 代码改造 | |
|---|---|---|---|---|
| 应用出海 | 业务请求流量(从Internet到公网会收0.09$/GC的费用,从国内到AWS是不收费的,只有出收费 | 无 | 无 | 无 |
| 数据库出海,只读 | 无 | RSD机器 + 服务费用(RDS 1004元/核/月,目前为低配4核16G集群,多个应用根据流量占比分摊,目前DRC复制费用比较低) | 单向复制 | 改造写请求 |
| 数据库出海,读写 | 海外到国内复制流量,出Internet费用是0.09$/GC | RSD机器 + 服务费用(RDS 1004元/核/月,目前为低配4核16G集群,多个应用根据流量占比分摊,目前DRC复制费用比较低) | 双向复制 | 无 |
# 二、数据库出海方案 DRC
DRC提供了跨公网MySQL数据库复制服务,公网加密传输Binlog,下面是一个单向的复制链路,双向链路会同时包含一个反向的链路,从海外同步回国内。
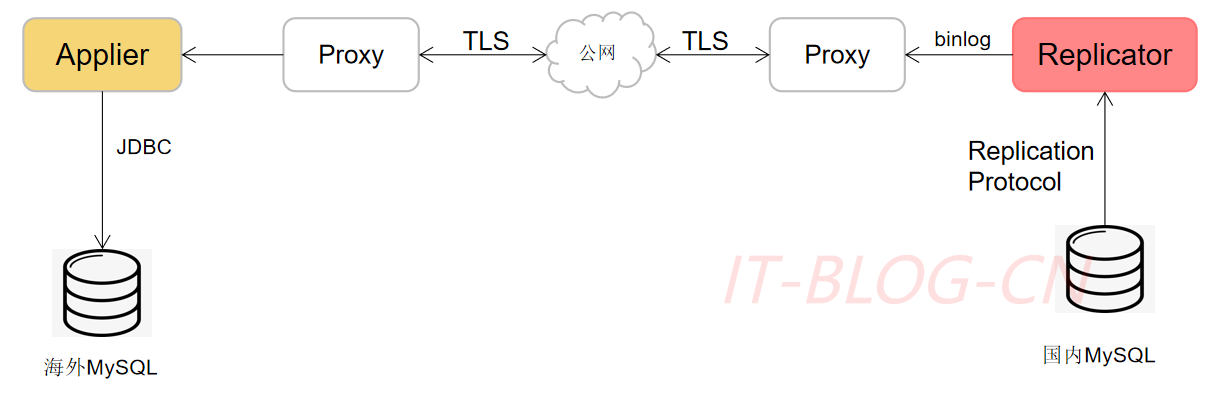
【1】Replicator:部署在国内,实现了MySQL复制协议,伪装成MySQL服务,向国内的MySQL请求binlog,将请求的binlog保存到本地磁盘。
【2】Applier:部署在海外,向国内的Replicator请求binlog,根据原生的JDBC协议,写入目标MySQL,从Proxy拿到的是二级制数据,并将其转化为SQL语句。
【3】Proxy:代理MySQL、Redis等服务,使用TCP层进行公网数据传输。
关键指标:复制延迟与物理距离成正比,延迟正常情况下相对稳定,极端情况下回到分钟级。VPC私有网络,业务自运维。
| 上海 - 阿里云 | 上海 - 新加坡 | 上海 - 法兰克福 | 上海 - SIN VPC | |
|---|---|---|---|---|
| 平均延迟 | 15ms | 90ms | 280ms | 90ms |
稳定性保障: 网络异常处理
【1】发送接收皆有流控,通过Netty实现。当发送的buffer到达高水位的时候,写就会关闭。当消息有积压的时候Applier就会关闭读操作;
【2】应用层心跳检测,Applier与Replicator每10s发送一次心跳包,30s未收到就会断开连接。2条供应商链路互为主备,外网的出口配置了两个供应商;
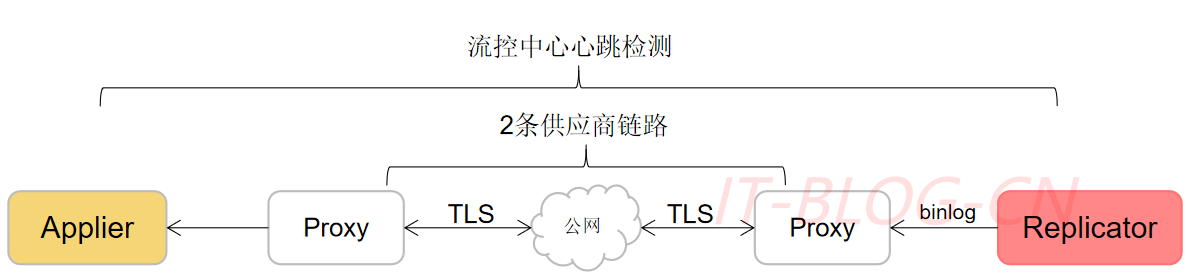
稳定性保障: 循环复制处理
【1】业务数据库初始化新建事务表gtid_executed;
【2】DRC复制先写事务表,反向复制链路过滤事务表开头事务;
将海外数据复制到国内,如果国内的Replicator区分不出该数据是否为海外复制数据,就会将该数据重复复制到海外,就会造成数据冲突。如下通过gtid_executed事务表模拟slave操作,解决循环复制问题。同时,也记录的未点信息,记录已经写入的事务ID。
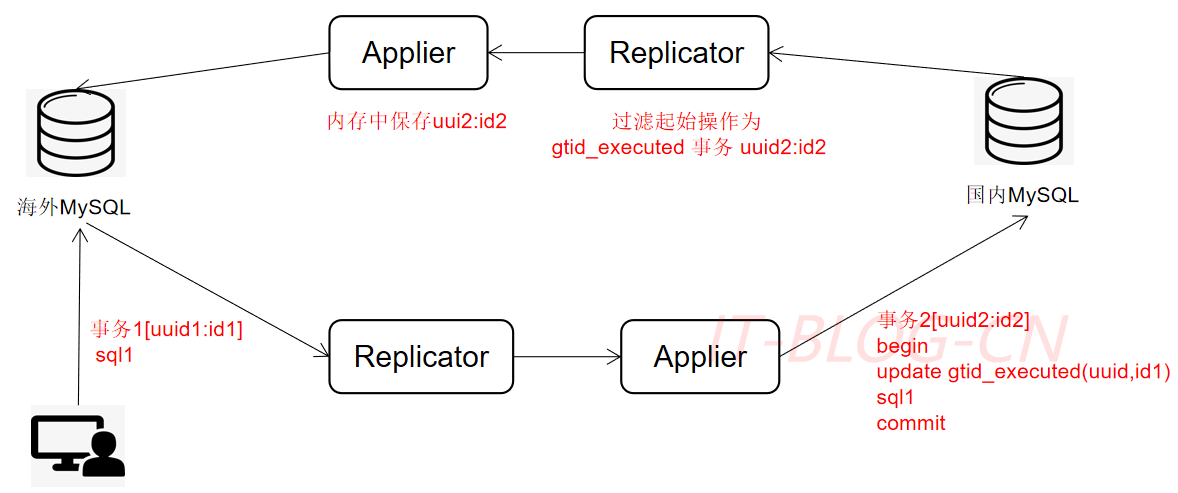
稳定性保障: 双向复制ID数据冲突处理
【1】自增ID避免冲突:第一种是引入分布式唯一ID,第二种是自增固定步长的ID。
auto_increment_increment=2^N(N=1,2,3...)
auto_increment_offset=M(M=[1,2^N])
2
【2】产生冲突:多个机房同时修改同一条数据,目前是以时间戳新的数据为准或者用户手动处理。
# 三、表结构变更
【1】根据DRC复制关系,公有云关联到国内DB,并行变更,还是存在先后顺序,海外的binlog存在新增的字段,在国内binlog回放的sql时候,国内的数据表结构还没有该字段,如果不处理的话,会报该字段不存在的错误。目前我们国内执行该binlog的时候,会将该字段去掉,去掉的前提是新增字段的值与默认值相等,如果不相等就需要业务介入,否则会造成数据不一致,因为当国内同步新增了该列后,会用默认值填充。
【2】表结构变更完成,为了保证数据一致,应用发布新代码。

# 四、一对多复制
【1】公有云单集群部署(分库),节省成本。
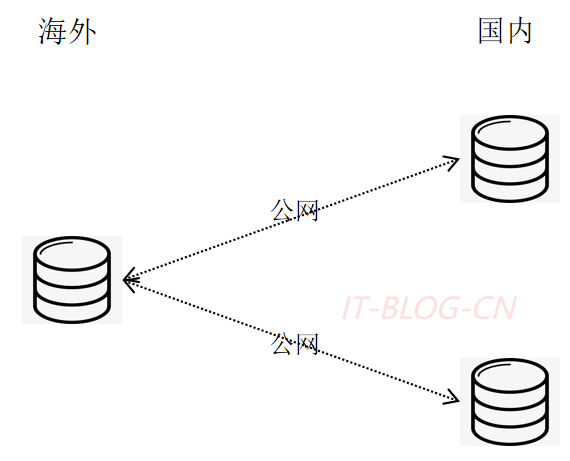
【2】公有云多机房复制。
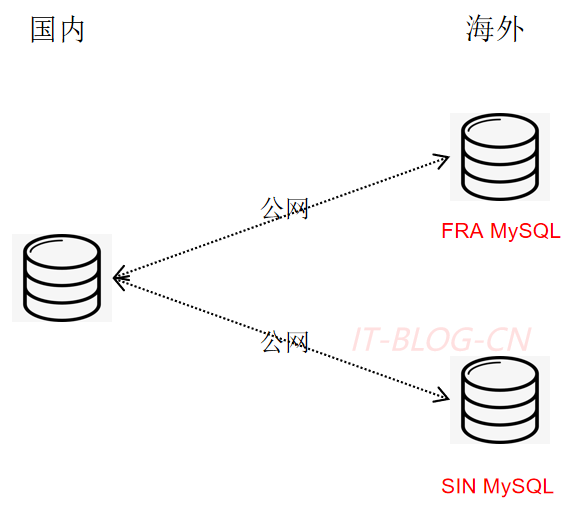
高阶功能支持:上海到公有云单/双向复制支持针对性出海:支持表过滤、行过滤、列过滤,因为数据合规的要求,所以比较敏感的数据,列入UID等数据可以通过行过滤实现。如果通过UID判断数据是否出海,效率不高。因为Replicator接收到的是二进制数据,需要将二进制数据转换后获取UID,在通过UID调用远程IDC判断用户属性效率比较低,TPS超过200延迟就比较严重,所以推荐UDL。
# 五、数据库访问组件 Dal Cluster
如何保证海外的数据库访问,不会访问的国内。
【1】国内/海外下发不同配置(链接串)
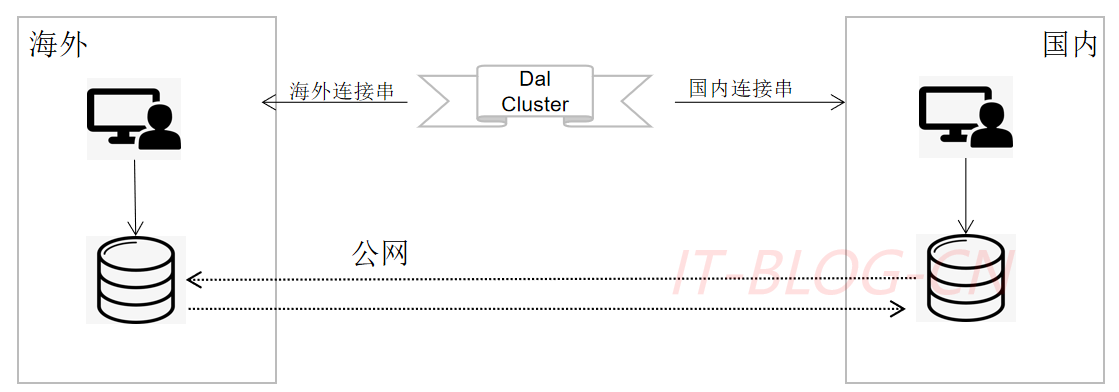
【2】中心化配置管理:中心化配置,业务无感知。数据库禁止跨海访问,否则应用启动报错。发布完成之后,可以去 Dal Cluster 管理端确认配置是否发布。
业务申请海外数据库 --> DBA部署海外数据库 --> Dal Cluster 新建海外配置 --> Dal Cluster 发布海外配置 --> Dal 客户端获取海外配置
# 六、数据库出海流程
【1】业务出海:1)数据库出海;2)应用出海;3)流量分发;
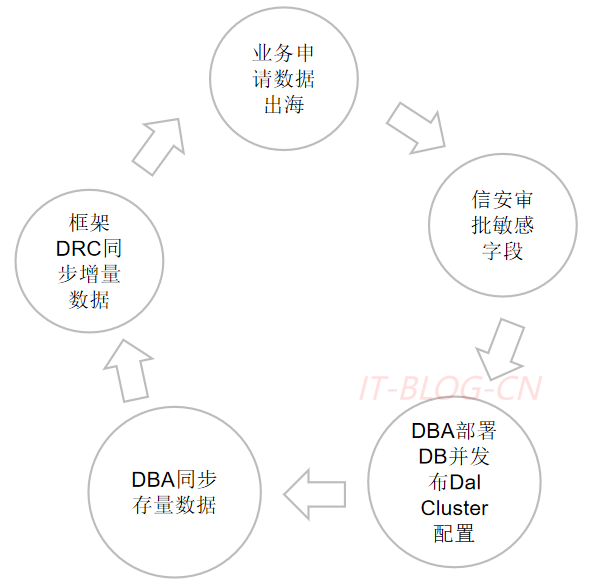
【2】数据库出海:涉及业务方、信安、DBA和框架组。
数据库出海,流量在国内 --> 应用出海,流量在国内 --> 公有云,灰度流量[GateWay] --> 完成灰度,流量切分完成
注意事项:
【1】若出海的数据分散在多个库,先汇总到一个集群,统一出海;
【2】双向复制时,需要做好流量切分,避免数据复制出现冲突;
【3】保留流量切分到上海的能力,防止复制中断影响业务;
【4】如果相同的数据存在多个更新场景,在并发的情况下还容易产生数据冲突的问题,也需要通过单元化部署避免;