随着每个公司国际业务的发展,为了数据符合各国家安全要求和提高用户体验,上云志在必得。而海外公有云环境与国内私有云环境有一定差异。所以主要内容包括公有云与私有云的差距、双边数据互通、网关、内网错综复杂的微服务和各种持久化存储等。
# 一、主要差异
【1】网络延迟: 海外AWS与国内私有云之间有明显的网络延迟,根据不同区域延迟不同,比如新加坡到上海的延迟基本为80ms左右。
【2】框架组件支持: 海外AWS上部署和使用框架与国内私有云有一些差异,主要包含:Redis/QMQ/MySQL/SOA等。
【3】网络流量: 海外AWS与国内私有云之间的宽带有限,尽量减少/减小两者之间传输的数据。
【4】成本费用: 海外AWS的费用大概是国内的10倍左右,根据不同的框架这个差距不同,开发人员需要进行代码重构,减少资源的使用。
# 二、上云的挑战
通常一个大型项目会依赖/牵扯到成百上千个应用。如果将所有的应用都迁移到云上,从开发成本和硬件成本考量都不太合理。所以需要先部署依赖就少的服务,比如某个活动服务【只包含一个API】等。
# 三、GateWay 的挑战
目前GateWay只能按照服务的维度转发流量,而无法基于API转发。当流量从AWS的IDC A进入GateWay时,无法支持只转发API到IDC A,其余API转发到IDC B。
应用发布时会依赖多个Redis、MySQL等服务,但是AWS IDC之间的存储由于安全问题,是无法直接相互访问的,最终导致应用启动失败。当然我们也可以请各个框架组件排期支持点火动态配置,根据当前IDC的配置,判断哪些组件需要点火。但是这无疑会让框架和应用本身都变得很笨重,合理性值得探讨。反之如果把这些存储依赖在每个IDC都重复部署一次,势必会导致硬件和开发成本的浪费。
# 四、云上数据的持久化【Redis/MySQL】
Redis在AWS上的使用,采用框架CRedis客户端接入,代码API方法使用上与在携程私有云上无差别。在AWS和私有云的主要差异是环境部署和数据同步: 云上服务依赖的Redis根据业务情况可以有以下解决方案:
# 方案一:访问国内Redis服务
直接通过在IDC之间架设专线,通常Redis响应都是几毫秒,而网络延迟都具有不稳定的特点,极端可能要几百毫秒,所以专线的网络延迟对实时业务来说是不可接受的。退一步,即使部分业务能够接受网络延迟,整个公司业务都以这种方法进行数据访问,这条专线未来会变成一个瓶颈。
# 方案二:海外部署Redis集群
将依赖的Redis部署到多个AWS IDC。很多公司都有自研的持久化KV存储来代替Redis达到降低硬件成本的目的。接下来就是数据同步的问题:根据业务决定是否需要同步,是进行单向同步还是双向同步
# 不需要同步
例如Redis负责基于Http请求的Cache不需要同步,框架代码无需做改变,默认访问IDC本地机房Redis。换言之,IDC A的应用读写IDC A的Redis实例,IDC B的应用读写IDC B的Redis实例,保证各个国家数据安全性的同时提高用户体验。
# 单向同步
某项目的业务特点只读不写,实时从国内IDC同步数据,所以只需单向同步,并且对延迟性要求低。
多个机房部署,其中一个机房为master,支持读写功能,master只能选择上海机房。master会将数据同步到其他机房。其他机房为slave,只支持读取功能。此模式下,AWS公有云上只能读取本机房的数据,无法进行写操作
# 双向同步
多个机房部署时,每个都是master,支持读写功能,master之间做双向的数据同步。
WARNING
申请新集群时的重名检查,是不区分机房的,即使两个集群部署在完全不同的机房,也会被认为是重名。
扩展Redis集群: 指已经在私有云部署的集群,需要在AWS上部署同名的实例来使用。也就是Redis集群实例扩容或者缩容。
# 五、云上文件的存储与共享
大型项目常常会用到读写本地文件的技术。应用会在IDC内网传输共享这些文件,而这些文件有些很大,可达10个G。
# 方案一:国外访问国内服务
基于KISS原则,我们首先尝试让AWS IDC A的服务通过专线直接访问IDC B的文件。但是由于网络不知名的原因,文件可以传输,却始终无法成功。但是即使成功,仍然带来很多隐患,例如:如此大的文件会瞬间把专线带宽长期占满,而真正有实时需求的通讯会卡顿受阻。
# 方案二:各AWS都部署
但是迁移上去后,背后依赖的数据库是否需要部署,甚至是数据库后面庞大的Hadoop集群也一并重复部署一次?
# 方案三:添加中间件
通过AWS S3的服务在不同IDC之间共享文件,发现性能满足业务要求。
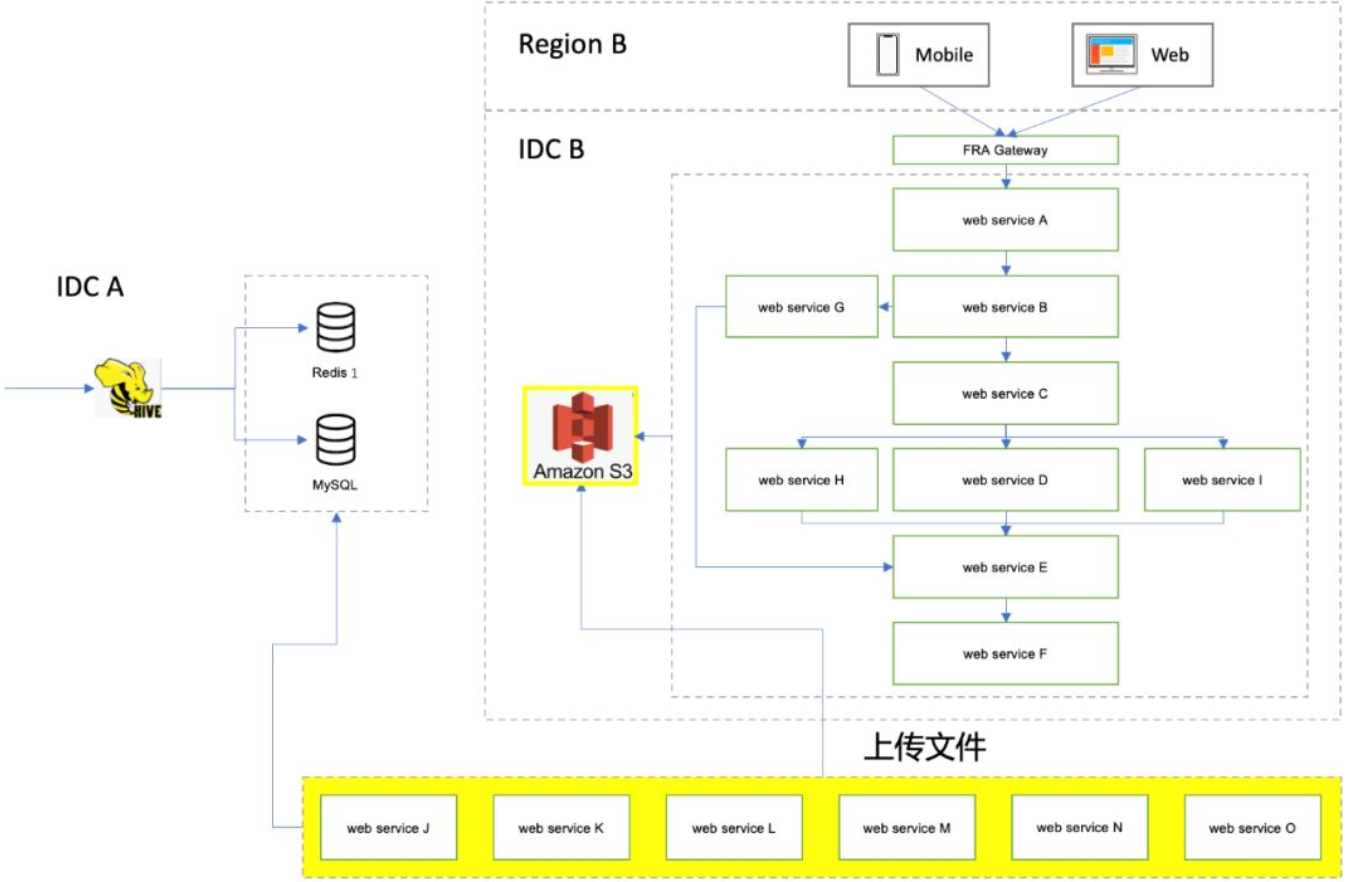
从方案的选择上来看,AWS S3的使用场景是值得商讨的。用云上产品一般都会有一个顾虑,就是太过依赖某种云的一个具体产品,当后期如果要换成其他云时,会有大量的迁移成本。例如AWS的S3 API就是定制化的:
使用AmazonS3客户端的listBucket方法,如果成功,会返回存储桶列表。
// 导入
import com.amazonaws.regions.Regions;
import com.amazonaws.services.s3.AmazonS3;
import com.amazonaws.services.s3.AmazonS3ClientBuilder;
import com.amazonaws.services.s3.model.Bucket;
List<Bucket> bucket = s3.listBuckets();
for (Bucket b: bucket) {
// xxxx
}
2
3
4
5
6
7
8
9
10
← DDD[领域驱动模型] 上云流程 →