# 一、为什么要用 ZGC
# 问题
我们有个“智慧园区”的项目,我们的下游系统“交叉带”[硬件系统]要求我们服务 60ms内返回结果,并且可用性要达到 99.99%。当时使用的是 G1垃圾回收器,单次 Young GC 40ms,一分钟10次,接口平均响应时间30ms。通过计算可知,有(40ms + 30ms) * 10次 / 60000ms = 1.12%的请求的响应时间会增加0 ~ 40ms不等,其中30ms * 10次 / 60000ms = 0.5%的请求响应时间会增加40ms。结论,GC停顿对响应时间的影响较大。为了降低 GC停顿对系统可用性的影响,我们从降低单次GC时间和降低GC频率两个角度出发进行了调优。

# G1停顿时间瓶颈
标记阶段停顿分析
- 初始标记阶段:初始标记阶段是指从 GC Roots出发标记全部直接子节点的过程,该阶段是 STW的。由于 GC Roots数量不多,通常该阶段耗时非常短。
- 并发标记阶段:并发标记阶段是指从 GC Roots开始对堆中对象进行可达性分析,找出存活对象。该阶段是并发的,即应用线程和 GC线程可以同时运行。并发标记耗时相对长很多,但因为不是STW,所以我们不太关心该阶段耗时的长短。
- 再标记阶段:重新标记那些在并发标记阶段发生变化的对象。该阶段是 STW的。
清点阶段停顿分析:清理阶段清点出有存活对象的分区和没有存活对象的分区以及GC回收比例,并进行排序,识别可以混合回收的区域。该阶段不会清理垃圾对象,也不会执行存活对象的复制。该阶段是 STW的。
复制阶段停顿分析:复制算法中的转移阶段需要分配新内存和复制对象的成员变量。转移阶段是 STW的,其中内存分配通常耗时非常短,但对象成员变量的复制耗时有可能较长,这是因为复制耗时与存活对象数量与对象复杂度成正比。对象越复杂,复制耗时越长。
4G以下可以用parallel,4-8G可以用ParNew+CMS,8G以上可以用G1,几百G以上用ZGC
四个 STW过程中,初始标记因为只标记 GC Roots,耗时较短。再标记因为对象数少,耗时也较短。清理阶段因为内存分区数量少,耗时也较短。转移阶段要处理所有存活的对象,耗时会较长。因此,G1停顿时间的瓶颈主要是标记-复制中的转移阶段 STW。为什么转移阶段不能和标记阶段一样并发执行呢?主要是 G1未能解决转移过程中准确定位对象地址的问题。
官方两者比较:G1的吞吐量是稍稍领先一点。黄色关键性能表现ZGC要更领先,这当然要归功于他的停顿时间短。
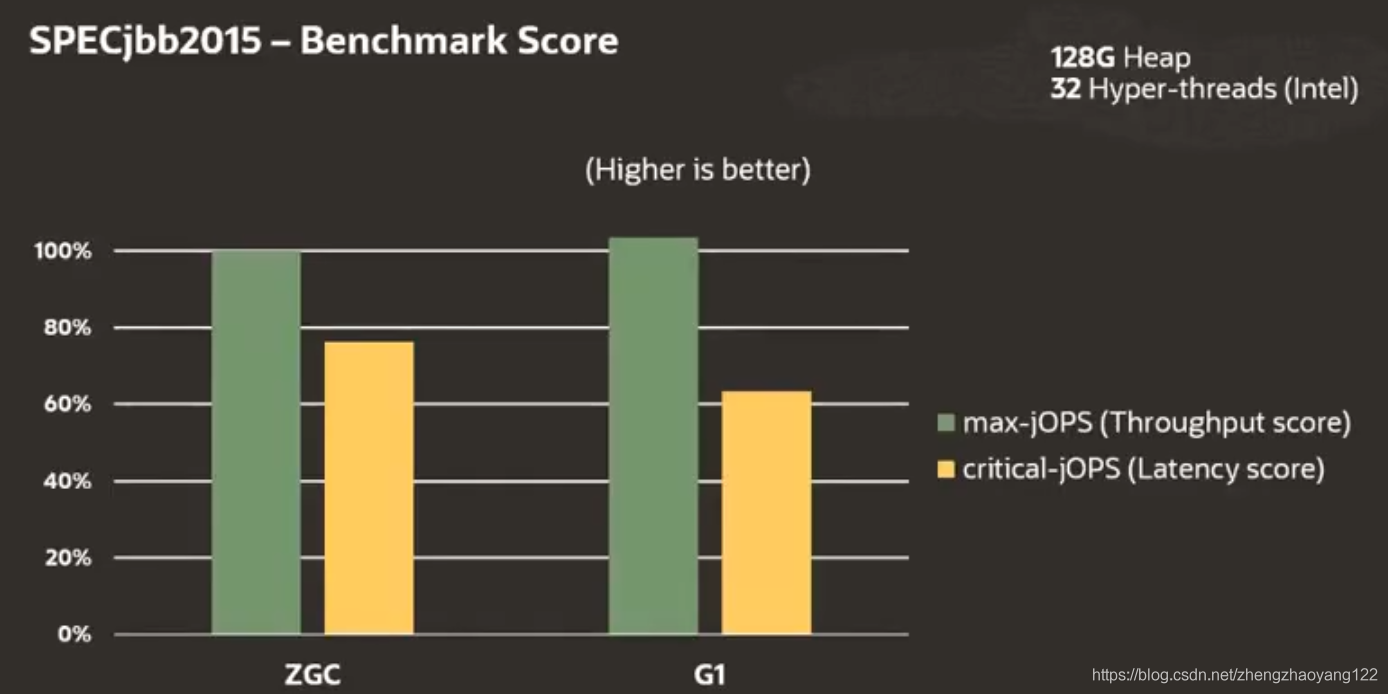
谈论停顿时间,基于UM,这种情况下,G1和ZGC的表现情况如下:G1平均脉冲时间约为 150ms,最大脉冲时间约为 470ms。
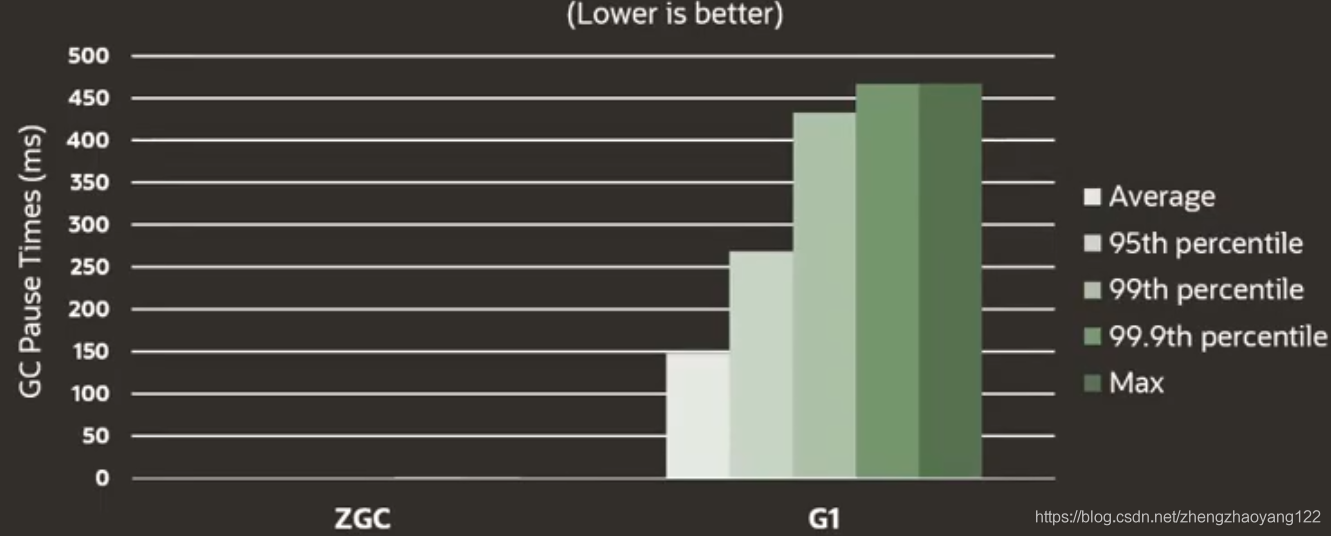
当使用 ZGC的 UM,上图实际上并没有删除。暂停时间太短,以至于它们没有在此注册,缩放比例之后,就可以看到如下所示:换句话说,放大100倍看起来像这样。从图中看ZGC平均时间约半毫秒,最大脉冲时间刚好超过一毫秒。所以就可以看出时间上的巨大差距,但付出只有一点吞吐量的降低。包括我们对大内存的基本测试,也会得到基本相似的结果。
# 二、什么是 ZGC
ZGC(The Z Garbage Collector)是JDK 11中推出的一款低延迟垃圾回收器,ZGC可以说源自于 Azul System 公司开发的C4收集器[基本不用调优]它的设计目标包括:
【1】停顿时间不超过10ms(STW减少了)之所以能做到这一点是因为它的停顿时间主要跟 GCRoot扫描有关,而 GCRoot数量和堆大小是没有任何关系的(停顿时间不会随着堆的大小,或者活跃对象的大小而增加,影响它的是 GCRoot对象);
GC Roots有这些:A garbage collection root is an object that is accessible from outside the heap. The following reasons make an object a GC root:
1.System Class
----------Class loaded by bootstrap/system class loader. For example, everything from the rt.jar like java.util.* .
2.JNI Local
----------Local variable in native code, such as user defined JNI code or JVM internal code.
3.JNI Global
----------Global variable in native code, such as user defined JNI code or JVM internal code.
4.Thread Block
----------Object referred to from a currently active thread block.
Thread
----------A started, but not stopped, thread.
5.Busy Monitor
----------Everything that has called wait() or notify() or that is synchronized. For example, by calling synchronized(Object) or by entering a synchronized method. Static method means class, non-static method means object.
6.Java Local
----------Local variable. For example, input parameters or locally created objects of methods that are still in the stack of a thread.
7.Native Stack
----------In or out parameters in native code, such as user defined JNI code or JVM internal code. This is often the case as many methods have native parts and the objects handled as method parameters become GC roots. For example, parameters used for file/network I/O methods or reflection.
7.Finalizable
----------An object which is in a queue awaiting its finalizer to be run.
8.Unfinalized
----------An object which has a finalize method, but has not been finalized and is not yet on the finalizer queue.
9.Unreachable
----------An object which is unreachable from any other root, but has been marked as a root by MAT to retain objects which otherwise would not be included in the analysis.
10.Java Stack Frame
----------A Java stack frame, holding local variables. Only generated when the dump is parsed with the preference set to treat Java stack frames as objects.
11.Unknown
----------An object of unknown root type. Some dumps, such as IBM Portable Heap Dump files, do not have root information. For these dumps the MAT parser marks objects which are have no inbound references or are unreachable from any other root as roots of this type. This ensures that MAT retains all the objects in the dump.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
【2】支持 8MB~4TB级别的堆(JDK13支持16TB),我们生产环境的硬盘还没有上TB的,这应该可以满足未来十年内,所有 Java应用的需求了吧;
【3】最糟糕的情况下吞吐量会降低15%。停顿时间足够优秀。至于吞吐量,通过扩容分分钟解决。

ZGC 支持的版本:最初是作为实验性功能发布的,在 jdk11中,当时它仅支持在 x86和以上版本的 Linux。截止目前在稳定性改进和性能改进添加了很多新功能,添加了对所有平台的支持。JDK15不再是实验性功能,建议在生产中使用。但是JDK15不是长期支持的版本。目前发布的最新版本是 JDK16,版本太新使用的用户比较少。如果遇到问题,甲骨文都会很乐意支持你。
# 三、ZGC 内存分布
不分代(暂时):单代,即ZGC没有分代。我们知道以前垃圾回收器之所以分代,是因为源于“大部分对象朝生夕死",那为什么 ZGC就不分代,因为分代实现起来麻烦,作者就先实现出一个比较简单可用的单代版本,后续优化。
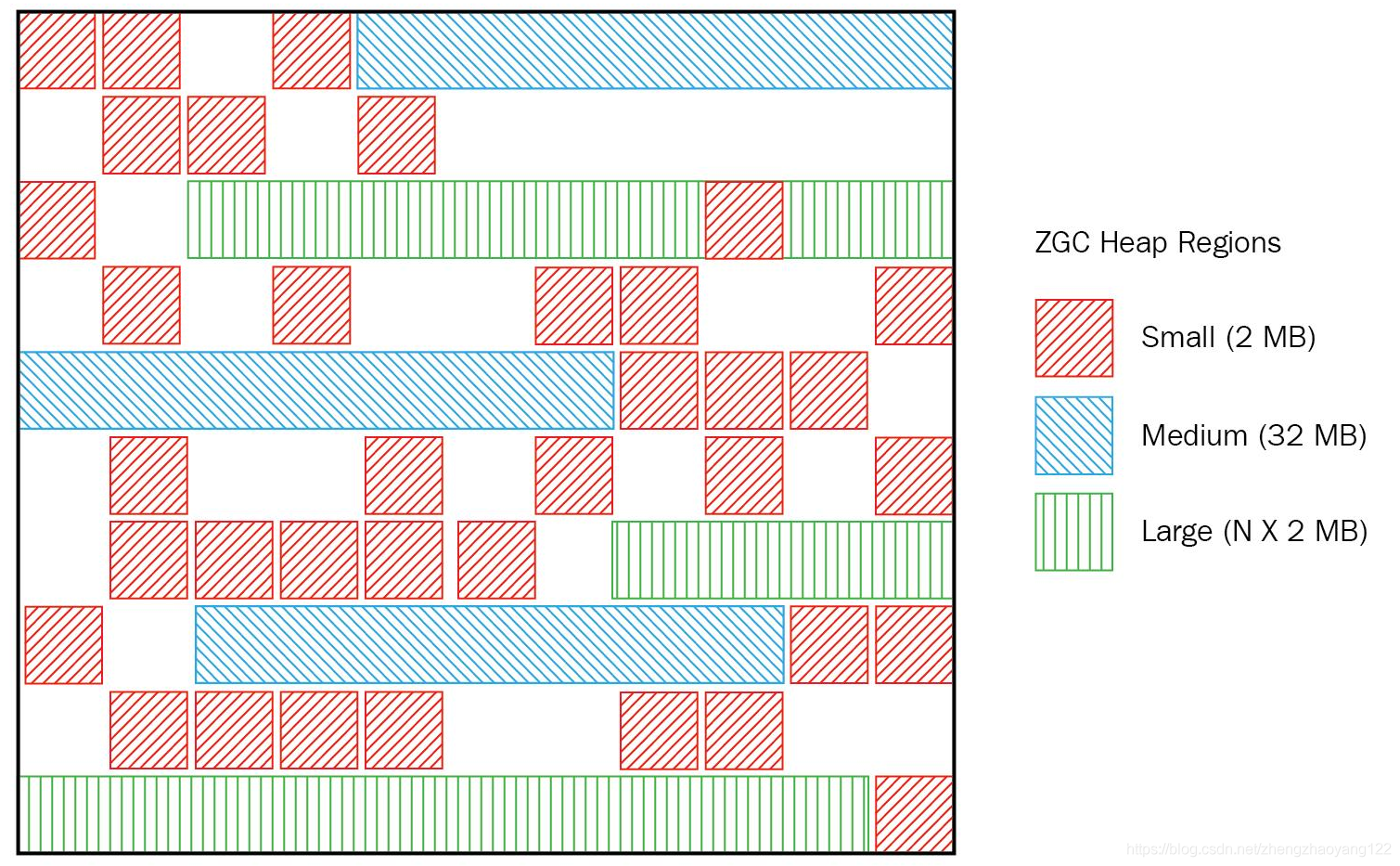
ZGC 的 Region可以具有如下图所示的大中下三类容量:
- 小型 Region(Small Region):容量固定为2MB,用于放置小于 256KB的小对象。
- 中型 Region(Medium Region):容量固定为 32MB,用于放置大于 256KB但是小于 4MB的对象。
- 大型 Region(Large Region):容量不固定,可以动态变化,但必须为 2MB的整数倍,用于放置 4MB或以上的大对象。每个大型 Region中会存放一个大对象,这也预示着虽然名字叫“大型 Region”,但它的实际容量完全有可能小于中型Region,最小容量可低至4MB.大型 Region在ZGC的实现中是不会被重分配的(重分配是ZGC的一种处理动作,用于复制对象的收集器阶段)因为复制大对象的代价非常高。
# 四、NUMA-aware
NUMA 对应的有 UMA,UMA即 Uniform Memory Access Architecture(统一内存访问架构),NUMA 就是 Non Uniform Memory Access Architecture。UMA表示内存只有一块,所有 CPU都去访问这一块内存,那么就会存在竞争问题(争夺内存总线访问权),有竞争就会有锁,有锁效率就会受到影响。而且CPU核心数越多,竞争就越激烈。NUMA的话每个CPU对应有一块内存,且这块内存在主板上离这个CPU是最近的,每个CPU优先访问这块内存,那么效率自然就提高了。
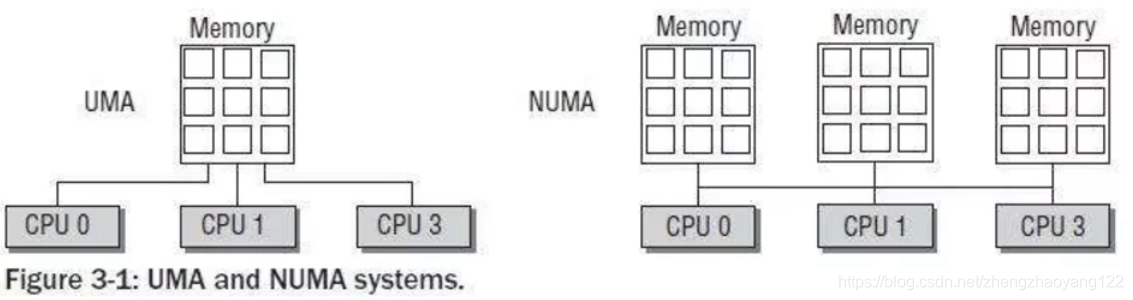
服务器的 NUMA架构在中大型系统上一直非常盛行,也是高性能的解决方案,尤其在系统延迟方面表现都很优秀。ZGC是自动感知 NUMA架构并充分利用 NUMA架构特性。
# 五、ZGC运作过程
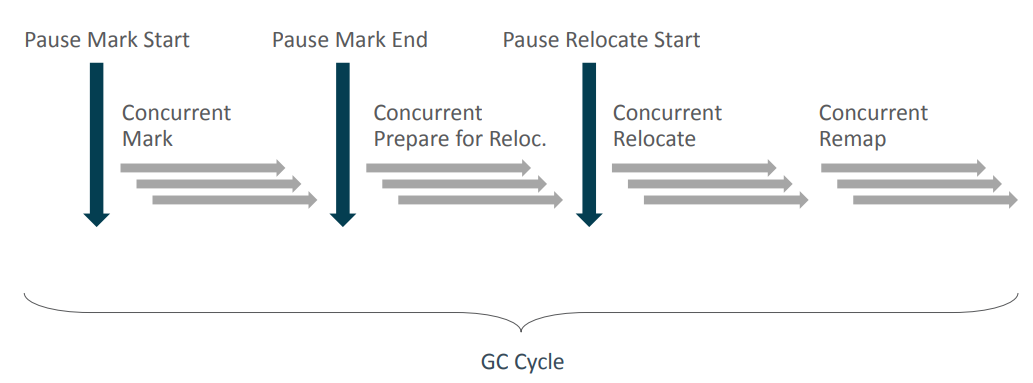
ZGC也采用标记-复制算法,不过 ZGC对该算法做了重大改进:ZGC在标记、转移和重定位阶段几乎都是并发的,这是 ZGC实现停顿时间小于10ms目标的最关键原因。ZGC 垃圾回收周期如下图所示:ZGC 的运作过程大致分为以下四个阶段:两张图,你看那个好理解
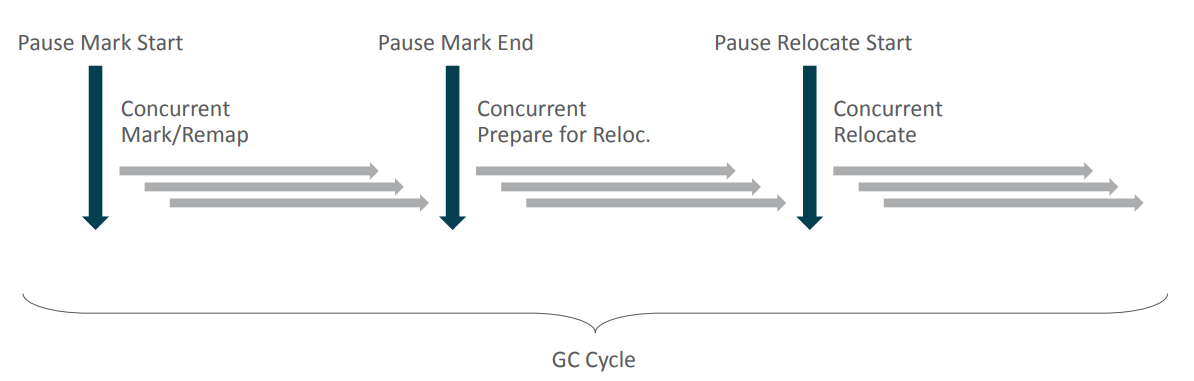
在这里,我们进行线程堆栈扫描以找到GRoot和GRoot指向 Java堆的指针。这将作为我们提供标记的起点。我们使用刚刚发现的GRoot来标记整个堆,我们找到的对象将被标记为非垃圾,我们不标记的对象将被隐式地认为是垃圾,然后我们来到结束标记阶段,标记和暂停这只是一个同步点。然后我们在并发模式下继续由类加载器决定不再使用这些类,然后将占用的资源释放和对非垃圾对象进行重定位。再一次STW继续进行迁移,这次我们扫描线程堆栈想要找到指向在其中设置的重定位的根。然后再次并发工作,实际上是在压缩堆,那结束了GC循环。每个 gc周期有三个短脉冲,我们要说的是这些停顿永远不会超过10个毫秒。
- 初始标记(Mark Start):先STW,并记录下gc roots直接引用的对象。
- 并发标记(Concurrent Mark):与G1一样,并发标记是遍历对象图可达性分析的阶段,它的初始化标记(Mark Start)和最终标记(Mark End)也会出现短暂的停顿,与G1不同的是,ZGC的标记是在指针上而不是在对象上进行的,标记阶段会更新颜色指针(见下面详解)中的 Marked0、Marked1标志位。记录在指针的好处就是对象回收之后,这块内存就可以立即使用。存在对象上的时候就不能马上使用,因为它上面还存放着一些垃圾回收的信息,需要清理完成之后才能使用。
- 再标记和非强根并行标记,在并发标记结束后尝试终结标记动作,理论上并发标记结束后所有待标记的对象会全部完成,但是因为GC工作线程和应用程序线程是并发运行,所以可能存在GC工作线程执行结束标记时,应用程序线程又有新的引用关系变化导致漏标记,所以这一步先判断是否真的结束了对象的标记,如果没有结束就还会启动并行标记,所以这一步需要STW。另外,在该步中,还会对非强根(软引用,虚引用等)进行并行标记。
- 并发预备重分配(Concurrent Prepare for Relocate):这个阶段需要根据特定的查询条件统计得出本次收集过程要清理那些 Region,将这些 Region组成重分配集(Relocation Set)。ZGC 每次回收都会扫描所有的 Region,用范围更大的扫描成本换取G1中记忆集和维护成本。
- 初始转移:转移根对象引用的对象,该步需要STW。
- 并发重分配(Concurrent Relocate):重分配是 ZGC执行过程中的核心阶段,这个过程要把重分配集中的存活对象复制到新的 Region上,并为重分配集中的每个 Region维护了一个转发表(Forward Table),记录从旧对象到新对象的转换关系。ZGC收集器能仅从引用上就明确得知一个对象是否处于重分配集中,如果用户线程此时并发访问了位于重分配集中的对象,这次访问将会被预置的内存屏障所截获,然后立即根据 Region上的转发表记录将访问转到新复制的对象上,并同时修正更新该引用的值,使其直接指向新对象,ZGC将这种行为称为指针的“自愈”(Self-Healing)能力。
ZGC的颜色指针因为“自愈”(self-Healing) 能力,所以只有第一次访问旧对象会变慢,一旦重分配集中某个 Region的存活对象都复制完毕后,这个 Region就可以立即释放用于新对象的分配,但是转发表还得留着不释放掉,因为可能还有访问在使用这个转发表。
- 并发重映射(Concurrent Remap):重映射所做的就是修正整个堆中指向重分配集中旧对象的所有引用,但是ZGC中对象引用存在“自愈”功能,所以这个重映射操作并不是很迫切。ZGC很巧妙地把并发重映射阶段要做的工作,合并到了下一次垃圾收集循环中的并发标记阶段里去完成,反正他们都是要遍历所有对象,这样合并就节省了一次遍历对象图的开销。一旦所有指针都被修正之后,原来记录新旧对象关系的转发表就可以释放掉了。
ZGC只有三个 STW阶段:初始标记,再标记,初始转移。其中,初始标记和初始转移分别都只需要扫描所有 GC Roots,其处理时间和 GC Roots的数量成正比,一般情况耗时非常短;再标记阶段 STW时间很短,最多1ms,超过1ms则再次进入并发标记阶段。即,ZGC几乎所有暂停都只依赖于 GCRoots集合大小,停顿时间不会随着堆的大小或者活跃对象的大小而增加。与 ZGC对比,G1的转移阶段完全 STW的,且停顿时间随存活对象的大小增加而增加。
ZGC参照操作系统中的虚拟地址和物理地址,设计了一套内存和地址的多重映射关系。ZGC为了能高效、灵活地管理内存,实现了两级内存管理:虚拟内存和物理内存,并且实现了物理内存和虚拟内存的映射关系。当应用程序创建对象时,首先在堆空间申请一个虚拟地址,ZGC同时会为该对象在Marked0、Marked1和 Remapped三个视图空间分别申请一个虚拟地址,且这三个虚拟地址对应同一个物理地址。ZGC与传统GC不同,标记阶段标记的是指针(colored pointer),而非传统GC算法中的标记对象。ZGC借助内存映射,将多个地址映射到同一个内存文件描述符上,使得ZGC回收周期各阶段能够使用不同的地址访问同一对象
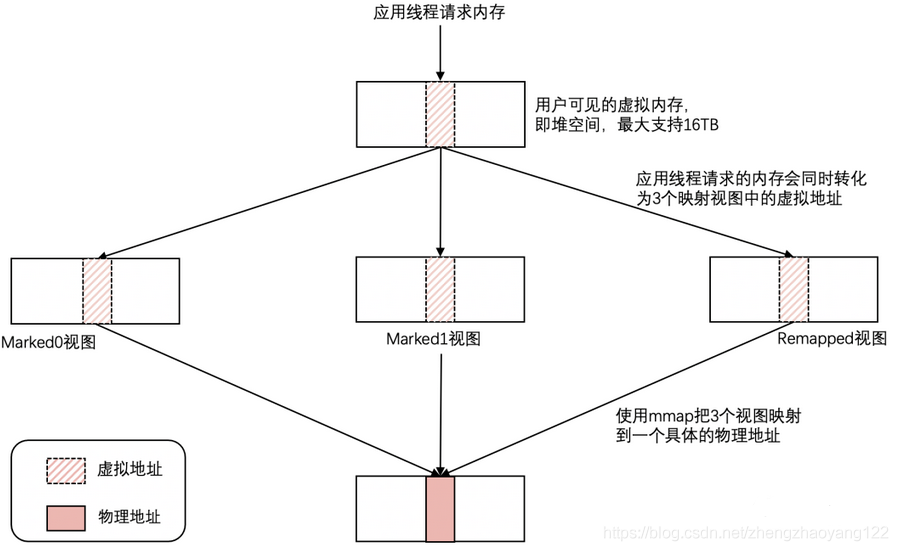
这是ZGC的三个视图空间,在ZGC中这三个空间在同一时间点有且仅有一个空间有效。而三个视图里面的地址,都是虚拟地址。最后,这些虚地址都能映射到同一个物理地址。ZGC为什么这么设计呢?这就是ZGC的高明之处,利用虚拟空间换时间,这三个空间的切换是由垃圾回收的不同阶段触发的,通过限定三个空间在同一时间点有且仅有一个空间有效,高效的完成了GC过程的并发操作。ZGC并发处理算法利用全局空间视图的切换和对象地址视图的切换,结合STAB算法实现了高效的并发。以上所有的铺垫,都是为了讲清楚ZGC的并发处理算法,在一些博文上,都说染色指针和读屏障是ZGC的核心,但都没有讲清楚两者是如何在算法里面被利用的,我认为,ZGC的并发处理算法才是ZGC的核心,染色指针和读屏障只不过是为算法服务而已。
ZGC仅支持 64位系统,它把 64位虚拟地址空间划分为多个子空间,如下图所示:
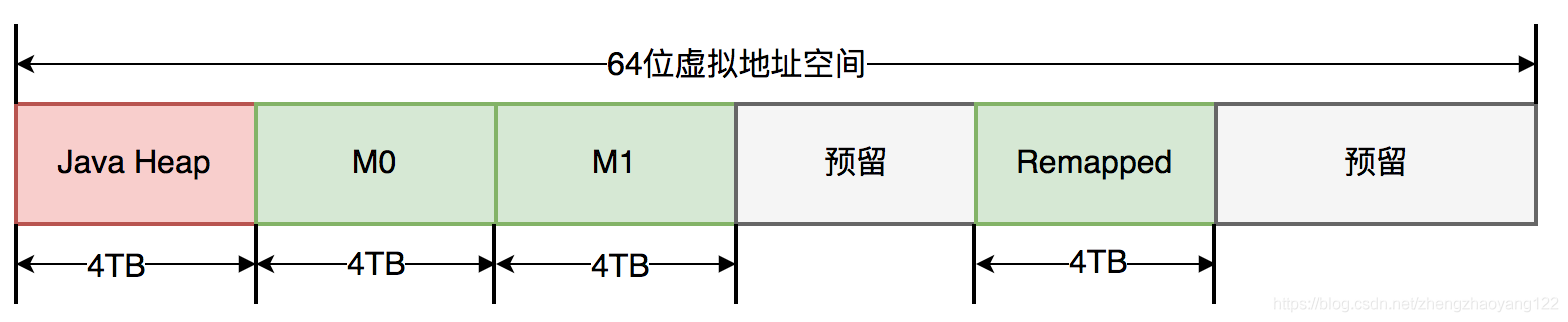
其中,[0~4TB) 对应 Java堆,[4TB ~ 8TB) 称为M0地址空间,[8TB ~ 12TB) 称为M1地址空间,[12TB ~ 16TB) 预留未使用,[16TB ~ 20TB) 称为 Remapped空间。
当应用程序创建对象时,首先在堆空间申请一个虚拟地址,但该虚拟地址并不会映射到真正的物理地址。ZGC同时会为该对象在M0、M1和Remapped地址空间分别申请一个虚拟地址,且这三个虚拟地址对应同一个物理地址,但这三个空间在同一时间有且只有一个空间有效。ZGC之所以设置三个虚拟地址空间,是因为它使用“空间换时间”思想,去降低 GC停顿时间。“空间换时间”中的空间是虚拟空间,而不是真正的物理空间。后续章节将详细介绍这三个空间的切换过程。
与上述地址空间划分相对应,ZGC实际仅使用64位地址空间的第0~41位,而第42~45位存储元数据,第47~63位固定为0。
ZGC 将对象存活信息存储在42~45位中,并将对象存活信息放在对象头中,与传统的垃圾回收完全不同。
接下来详细介绍 ZGC一次垃圾回收周期中地址视图的切换过程:
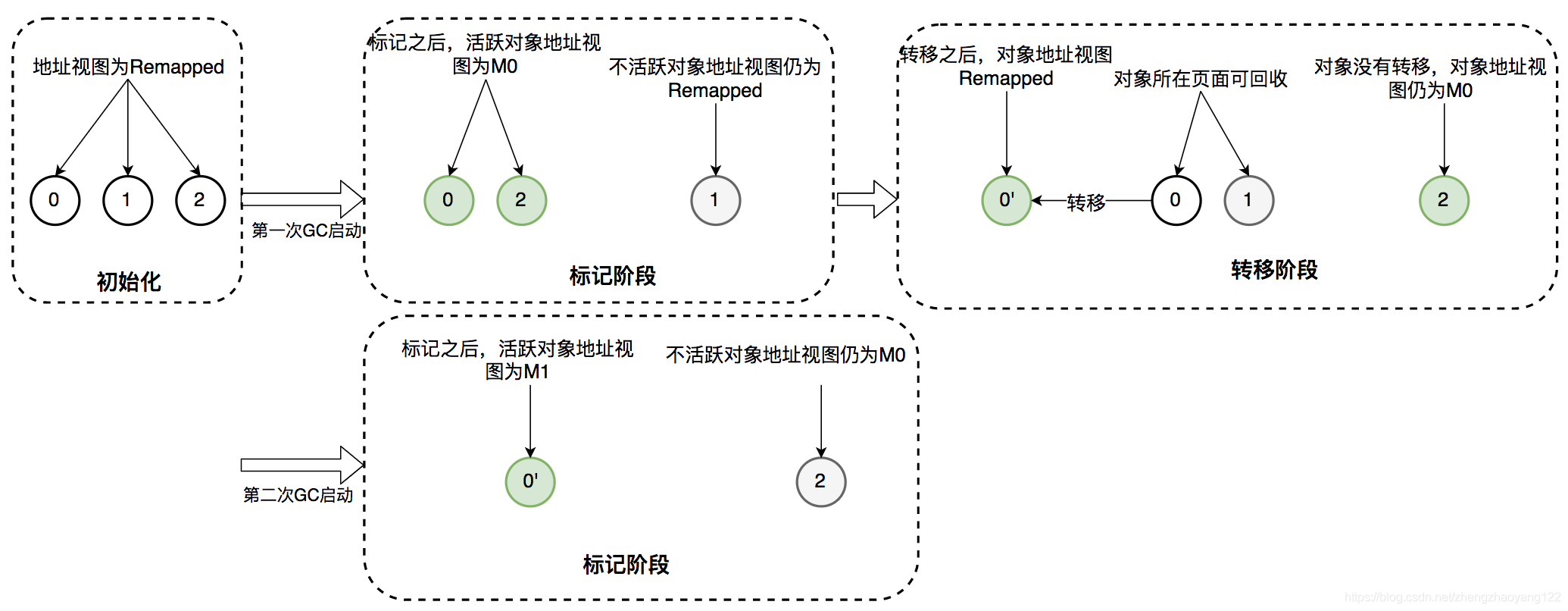
- 初始化:ZGC初始化之后,整个内存空间的地址视图被设置为 Remapped。程序正常运行,在内存中分配对象,满足一定条件后垃圾回收启动,此时进入标记阶段。
- 并发标记阶段:第一次进入标记阶段时视图为M0,如果对象被 GC标记线程或者应用线程访问过,那么就将对象的地址视图从 Remapped调整为M0。所以,在标记阶段结束之后,对象的地址要么是 M0视图,要么是 Remapped。如果对象的地址是 M0视图,那么说明对象是活跃的;如果对象的地址是 Remapped视图,说明对象是不活跃的。
- 并发转移阶段:标记结束后就进入转移阶段,此时地址视图再次被设置为 Remapped。如果对象被 GC转移线程或者应用线程访问过,那么就将对象的地址视图从M0调整为Remapped。
着色指针和读屏障技术不仅应用在并发转移阶段,还应用在并发标记阶段:将对象设置为已标记,传统的垃圾回收器需要进行一次内存访问,并将对象存活信息放在对象头中;而在 ZGC中,只需要设置指针地址的第42~45位即可,并且因为是寄存器访问,所以速度比访问内存更快。
标记阶段:标记阶段全局视图切换到M0视图。因为应用程序和标记线程并发执行,那么对象的访问可能来自标记线程和应用程序线程。

在标记阶段结束之后,对象的地址视图要么是M0,要么是Remapped。
- 如果对象的地址视图是M0,说明对象是活跃的;
- 如果对象的地址视图是Remapped,说明对象是不活跃的,即对象所使用的内存可以被回收。
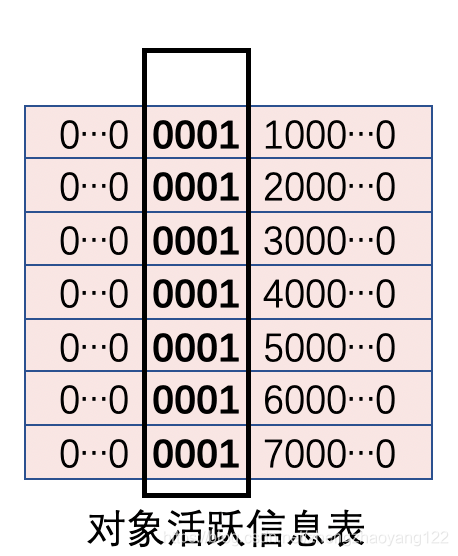
当标记阶段结束后,ZGC会把所有活跃对象的地址存到对象活跃信息表,活跃对象的地址视图都是M0。
转移阶段:转移阶段切换到 Remapped视图。因为应用程序和转移线程也是并发执行,那么对象的访问可能来自转移线程和应用程序线程。
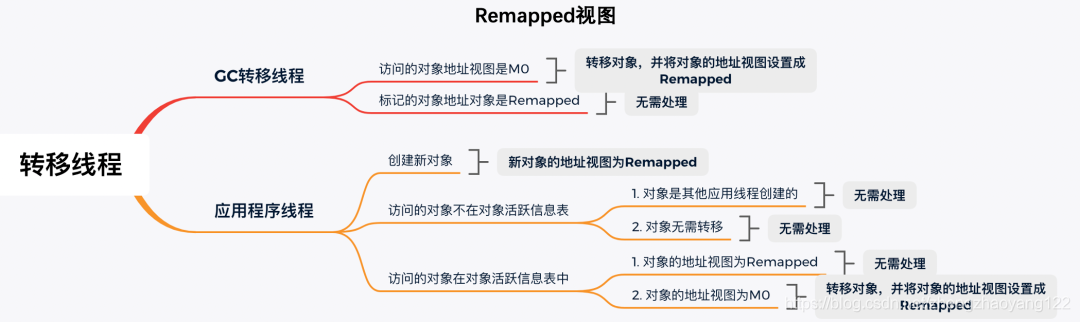
至此,ZGC的一个垃圾回收周期中,并发标记和并发转移就结束了。
为何要设计M0和M1:我们提到在标记阶段存在两个地址视图M0和M1,上面的算法过程显示只用到了一个地址视图,为什么设计成两个?简单地说是为了区别前一次标记和当前标记。ZGC是按照页面进行部分内存垃圾回收的,也就是说当对象所在的页面需要回收时,页面里面的对象需要被转移,如果页面不需要转移,页面里面的对象也就不需要转移。
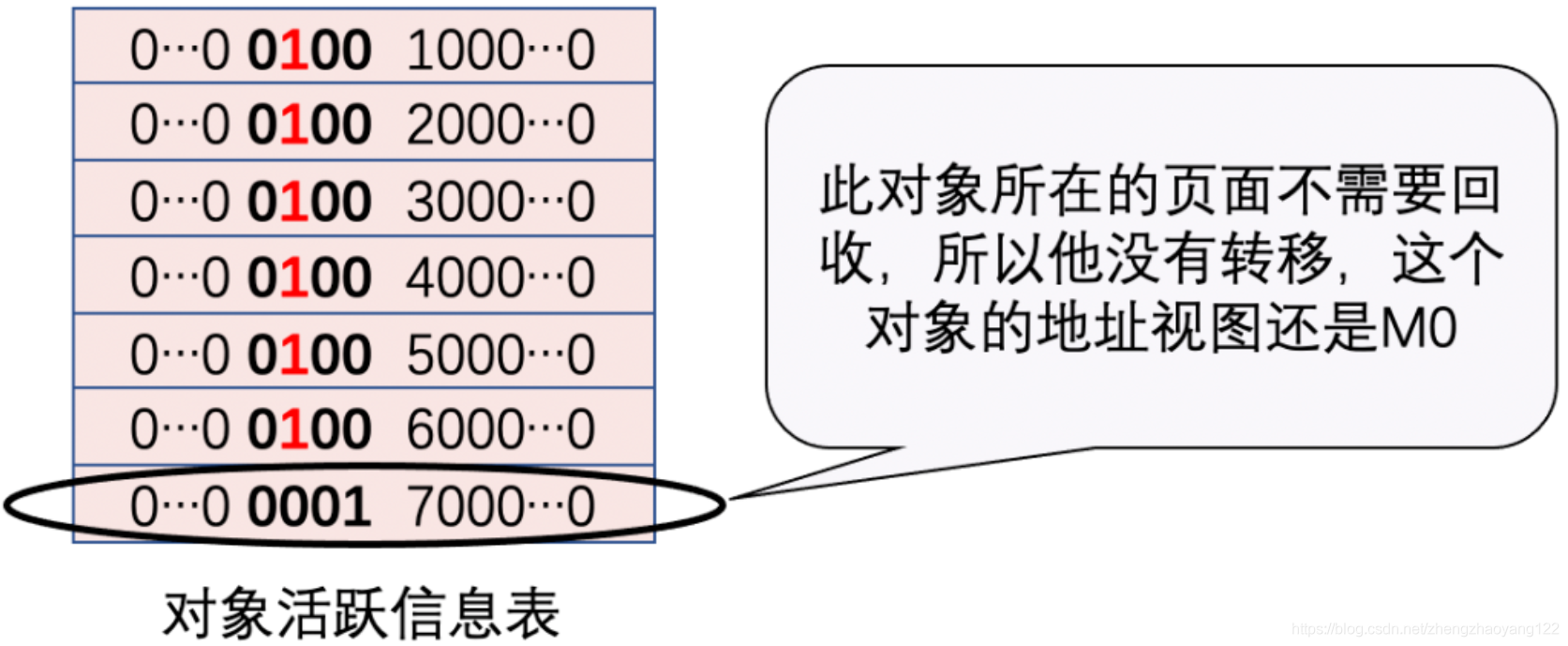
如图,这个对象在第二次GC周期开始的时候,地址视图还是M0。如果第二次GC的标记阶段还切到M0视图的话,就不能区分出对象是活跃的,还是上一次垃圾回收标记过的。这个时候,第二次GC周期的标记阶段切到M1视图的话就可以区分了,此时这3个地址视图代表的含义是:
- M1:本次垃圾回收中识别的活跃对象。
- M0:前一次垃圾回收的标记阶段被标记过的活跃对象,对象在转移阶段未被转移,但是在本次垃圾回收中被识别为不活跃对象。
- Remapped:前一次垃圾回收的转移阶段发生转移的对象或者是被应用程序线程访问的对象,但是在本次垃圾回收中被识别为不活跃对象。
现在,我们可以回答“使用地址视图和染色指针有什么好处”这个问题了。使用地址视图和染色指针可以加快标记和转移的速度。以前的垃圾回收器通过修改对象头的标记位来标记GC信息,这是有内存存取访问的,而ZGC通过地址视图和染色指针技术,无需任何对象访问,只需要设置地址中对应的标志位即可。这就是ZGC在标记和转移阶段速度更快的原因。当GC信息不再存储在对象头上时而存在引用指针上时,当确定一个对象已经无用的时候,可以立即重用对应的内存空间,这是把GC信息放到对象头所做不到的。
# 六、颜色指针
着色指针是一种将信息存储在指针中的技术。
Colored Pointers 即颜色指针,如下图所示,ZGC的核心设计之一。以前的垃圾回收器的GC信息(标记信息、GC分代年龄..)都保存在对象头中,而 ZGC的 GC信息保存在指针中。在 JDK11中,通过64位的低42位进行寻址,≈4TB,所以 JDK11最大支持4TB的内存,在JDK13的时候增加了两位可以支持16TB的内存。中间4位存储的是元数据(用来做GC标记),这些元数据告诉我们一些东西,关于此引用执行的对象已被标记或未标记或搬迁了、移动了。但是我们需要找到它移动到的位置。高位的18位目前没有用到,用于未来的扩展。
最多也就支持16TB,因为CPU与内存交互的时候是通过总线连接的,总线分为数据总线,地址总线,控制总线。目前的主板地址总线最宽 48bit。
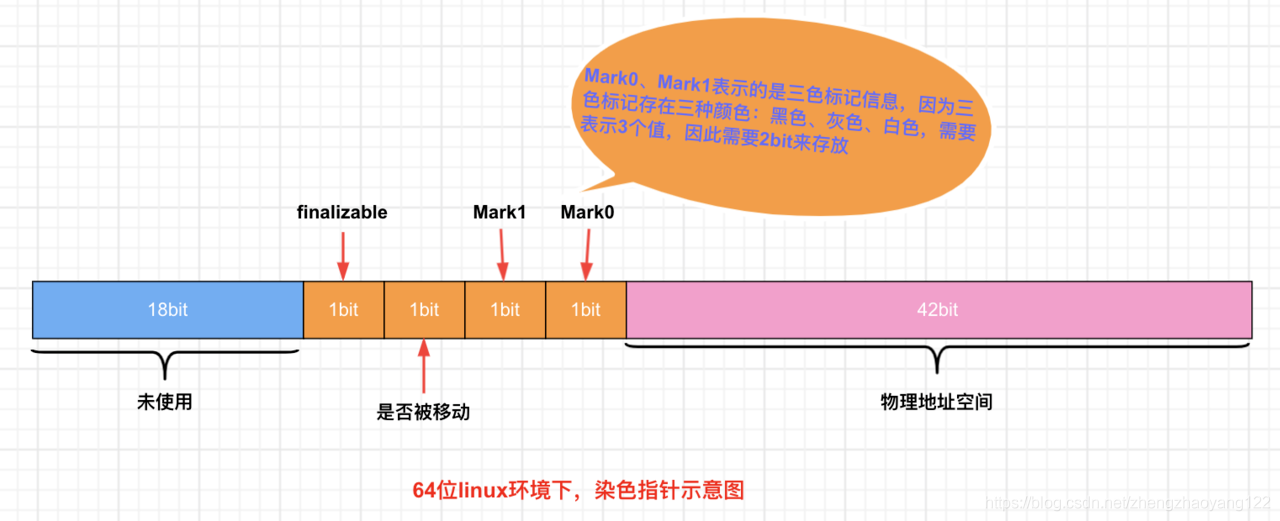
- Finalizable标识,此位与并发引用处理有关,它表示这个对象只能通过 Finalizer 才能访问到;
- Remapped标识,设置此位的值后,对象未指向 relocation set中(relocation set表示需要 GC的Region集合)
- Marked1标识;
- Marked0标识,和上面的 Marked1都是标记对象用于辅助GC(比如 01代表白色,10代表灰色,11代表黑色);
为什么有2个mark标记?每一个 GC周期开始时,会交换使用的标记位,使上次GC周期中修正的已标记状态失效,所有引用都变为标记。 GC周期1:使用 mark0,则周期结束所有引用 mark标记都会变为 01; GC周期2:使用 mark1,则期待的mark0标记10,所以引用都能被重新标记; 通过对配置ZGC后对象指针分析我们可知,对象指针必须是64位,那么ZGC就无法支持32位操作系统,同样的也就无法支持压缩指针了(CompressendOops,压缩指针也是32位,ShenandoahGC却能支持),指针压缩最大支持 35位≈32G,存到内存中只有32位,使用的时候需要解压缩位35位供CPU是使用。
颜色指针的三大优势:
- 一旦某个 Region的存活对象被移走之后,这个 Region立即就能够被释放和重用掉,而不必等待整个堆中所有指向该Region的引用都被修正后才能清理,这使得理论上只要还有一个空闲Region,ZGC就能完成收集。
- 颜色指针可以大幅度减少在垃圾收集过程中内存屏障的使用数量,ZGC只使用了读屏障。
- 颜色指针具备强大的扩展性,它可以作为一种可扩展的存储结构用来记录更多与对象标记、重定位相关的数据,以便日后进一步提高性能。
一个对象的重分配可能由GC线程完成,也可能是应用程序线程(比GC线程更早访问对象时,load barrier进行)。当这两个线程同时尝试重分配同一个对象时,通过原子性的CAS操作,ZGC会找到第一个尝试的线程,该线程完成relocate。完成relocate(GC线程走完所有的relocation set)之后,load barrier会将指向relocation set中的引用修正为新的地址。即Remapping
# 七、读屏障
在并发重分配的时候,每进行一个对象的复制移动会对其颜色指针的 Remapped标识赋值,标识这个指针被 gc过,并且还会为其加一个读屏障,使得用户线程访问这个对象时可以知道这个对象的地址被改变了,程序就应该暂停一下,先更新一下地址,再进行访问值的操作,正是因为 Load Barriers的存在,所以会导致配置ZGC的应用的吞吐量会变低。官方的测试数据是需要多出额外4%的开销。千万不要把这个读屏障和Java内存模型里面的读屏障搞混了,两者根本不是同一个东西,ZGC中的读屏障更像是一种AOP技术,在字节码层面或者编译代码层面给读操作增加一个额外的处理。
之前的 GC都是采用 Write Barrier,这次 ZGC采用了完全不同的方案读屏障,这个是 ZGC一个非常重要的特性。在标记和移动对象的阶段,每次从堆对象的引用类型中读取一个指针的时候,都需要加上一个 Load Barriers。
读屏障是 JVM向应用代码插入一小段代码的技术。当应用线程从堆中读取对象引用时,就会执行这段代码。需要注意的是,仅“从堆中读取对象引用”才会触发这段代码。
读屏障示例:ZGC中读屏障的代码作用:在对象标记和转移过程中,用于确定对象的引用地址是否满足条件,并作出相应动作。第一行代码我们尝试读取堆中的一个对象引用 obj.fieldA并赋值给引用o(fieldA也是一个对象时才会加上读屏障)。如果这个时候对象在GC被移动了,接下来JVM就会加上一个读屏障了,读屏障也会发现并修正指针,于是应用代码就永远都会持有更新后的有效指针,而且不需要STW。
那么,JVM是如何判断对象被移动过呢?就是利用上面提到的颜色指针,如果指针是Bad Color,那么程序还不能往下执行,需要 slow path,修正指针;如果指针是 Good Color,那么正常往下执行即可:
Object o = obj.FieldA // 从堆中读取引用,需要加入屏障
<Load barrier> // JIT就可以插入读屏障
Object p = o // 无需加入屏障,因为不是从堆中读取引用
o.dosomething() // 无需加入屏障,因为不是从堆中读取引用
int i = obj.FieldB //无需加入屏障,因为不是对象引用
2
3
4
5
Load Barrier:大概有 4%的系统消耗。
if (n & bad_bit_mask) {
slow_path(register_for(n), address_of(person.name));
}
2
3
上述代码通过 JIT编辑器生成的代码如下:
mov 0x20(%rax), %rbx // Objetct o = obj.fieldA
test %rbx, (0x16)%r15 // Bad color? 当不是一个正常的对象的时候,汇编上就会加这个语句,探测一下你是不是一个bad color,看你是否正在标记m0,m1,或者看你是否正在移动 relocate,或者正在回收finalize,或者重新分配 remap
jnz slow_path // Yes -> Enter slow path and mark/relocate/remap,adjust 0x20(%rax) and % rbx 就是等它把该做的操作做完了,我再拿新地址进行数据获取。有点像自旋。
2
3
ZGC中读屏障的代码作用:GC线程和应用线程是并发执行的,所以存在应用线程去A对象内部的引用所指向的对象B的时候,这个对象B正在被GC线程移动或者其他操作,加上读屏障之后,应用线程会去探测对象B是否被GC线程操作,然后等待操作完成再读取对象,确保数据的准确性。
# 八、ZGC 配置参数
-Xms10G -Xmx10G
-XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
-XX:ConcGCThreads=2 -XX:ParallelGCThreads=6
-XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/opt/logs/logs/gc-%t.log:time,tid,tags:filecount=5,filesize=50m
2
3
4
5
6
7
首先需要拥有足够大的堆大小以容纳应用程序的实时运行,但你还需要在堆中保留一定的净空,基本上会决定你需要多久执行一次GC,但你应该记住,这是一个并发的GC,所以还有足够的余量以允许分配服务。在一般情况下,当GC运行时,你分配给更多的内存显然更好,但是你不想浪费,就需要找到一个良好的平衡。
-Xms -Xmx:堆的最小内存和最大内存,这里都设置为10G,程序的堆内存将保持10G不变。
-XX:ReservedCodeCacheSize -XX:InitialCodeCacheSize:设置CodeCache的大小, JIT编译的代码都放在 CodeCache中,一般服务 64m或 128m就已经足够。我们的服务因为有一定特殊性,所以设置的较大,后面会详细介绍。
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC:启用 ZGC的配置。
-XX:ConcGCThreads:并发回收垃圾的线程。默认是总核数的12.5%,8核CPU默认是1。调大后GC变快,但会占用程序运行时的 CPU资源,吞吐会受到影响。如果你在这里选择一个数字,太高则存在GC将从中窃取太多 CPU时间的风险。如果数字太低,那么存在ZGC垃圾收集的时间无法跟上创造的时间。
# BUG案例:压测时,流量逐渐增大到一定程度后,出现性能毛刺
日志信息:平均1秒GC一次,两次 GC之间几乎没有间隔。
分析:GC触发及时,但内存标记和回收速度过慢,引起内存分配阻塞,导致停顿。
解决方法:增大-XX:ConcGCThreads, 加快并发标记和回收速度。ConcGCThreads默认值是核数的1/8,8核机器,默认值是1。该参数影响系统吞吐,如果 GC间隔时间大于 GC周期,不建议调整该参数。
-XX:ParallelGCThreads:STW阶段使用线程数,默认是总核数的60%。
-XX:ZCollectionInterval:ZGC发生的最小时间间隔,单位秒。
-XX:ZAllocationSpikeTolerance:ZGC触发自适应算法的修正系数,默认2,数值越大,越早的触发ZGC。
# BUG案例:11.11流量突增,出现性能毛刺
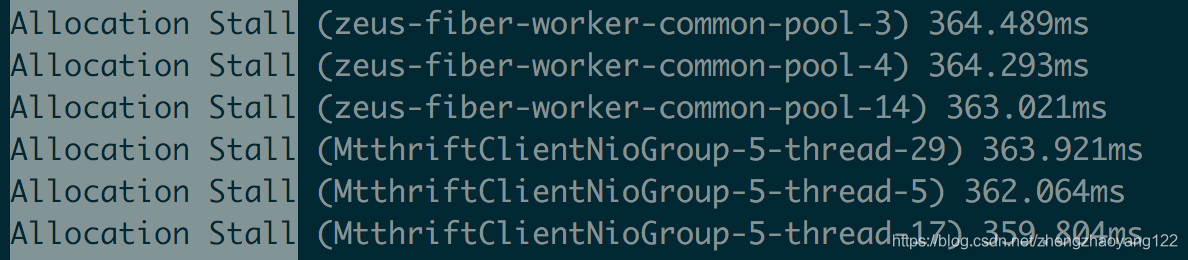
日志信息:对比出现性能毛刺时间点的 GC日志和业务日志,发现 JVM停顿了较长时间,且停顿时 GC日志中有大量的 “Allocation Stall”日志。
分析:这种案例多出现在“自适应算法”为主要 GC触发机制的场景中。ZGC是一款并发的垃圾回收器,GC线程和应用线程同时活动,在 GC过程中,还会产生新的对象。GC完成之前,新产生的对象将堆占满,那么应用线程可能因为申请内存失败而导致线程阻塞。当秒杀活动开始,大量请求打入系统,但自适应算法计算的 GC触发间隔较长,导致GC触发不及时,引起了内存分配阻塞,导致停顿。
解决方法:
【1】开启”基于固定时间间隔“的GC触发机制:-XX:ZCollectionInterval。调整为5秒,甚至更短。
【2】增大修正系数-XX:ZAllocationSpikeTolerance,更早触发GC。ZGC采用正态分布模型预测内存分配速率,模型修正系数 ZAllocationSpikeTolerance默认值为2,值越大,越早的触发GC,Zeus中所有集群设置的是5。
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive:是否启用主动回收,默认开启,这里的配置表示关闭。
-Xlog:设置GC日志中的内容、格式、位置以及每个日志的大小。
-Xlog:gc (basic) / -Xlog:gc* (detailed):如果查看GC日志记录,建议使用上述的选项第一个选项,它将提供基本的日志记录,每个GC周期基本上输出一行,非常高级的信息,或者如果你想要详细的日志记录,使用第二个选项,这在你具体调优或你想在哪里解决问题或获取有关正在发生的事情的更多信息时很有用。第一种形式的日志如下图所示:
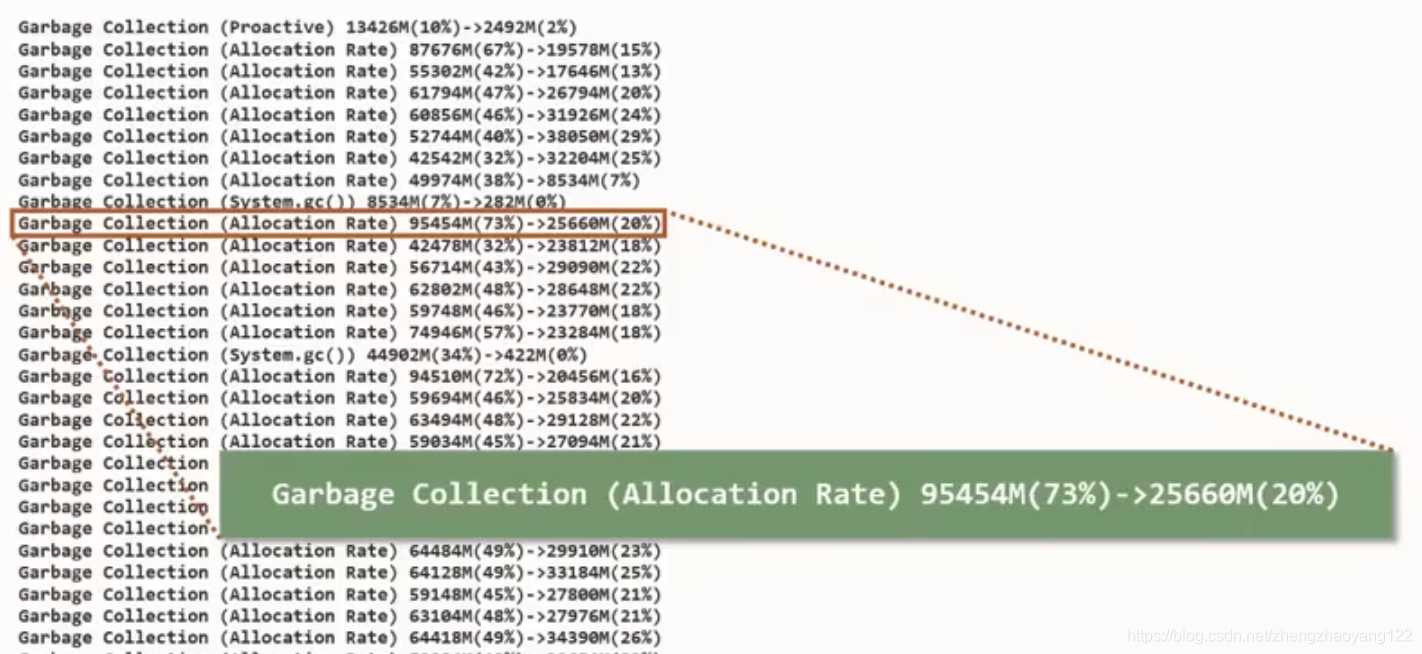
第二种形式的日志如下图:可以看到整个周期演化的过程,所以你可以看到GC周期开始使用了多少,标记阶段结束后,有多少活着,到底有多少垃圾,最终有多少垃圾被回收
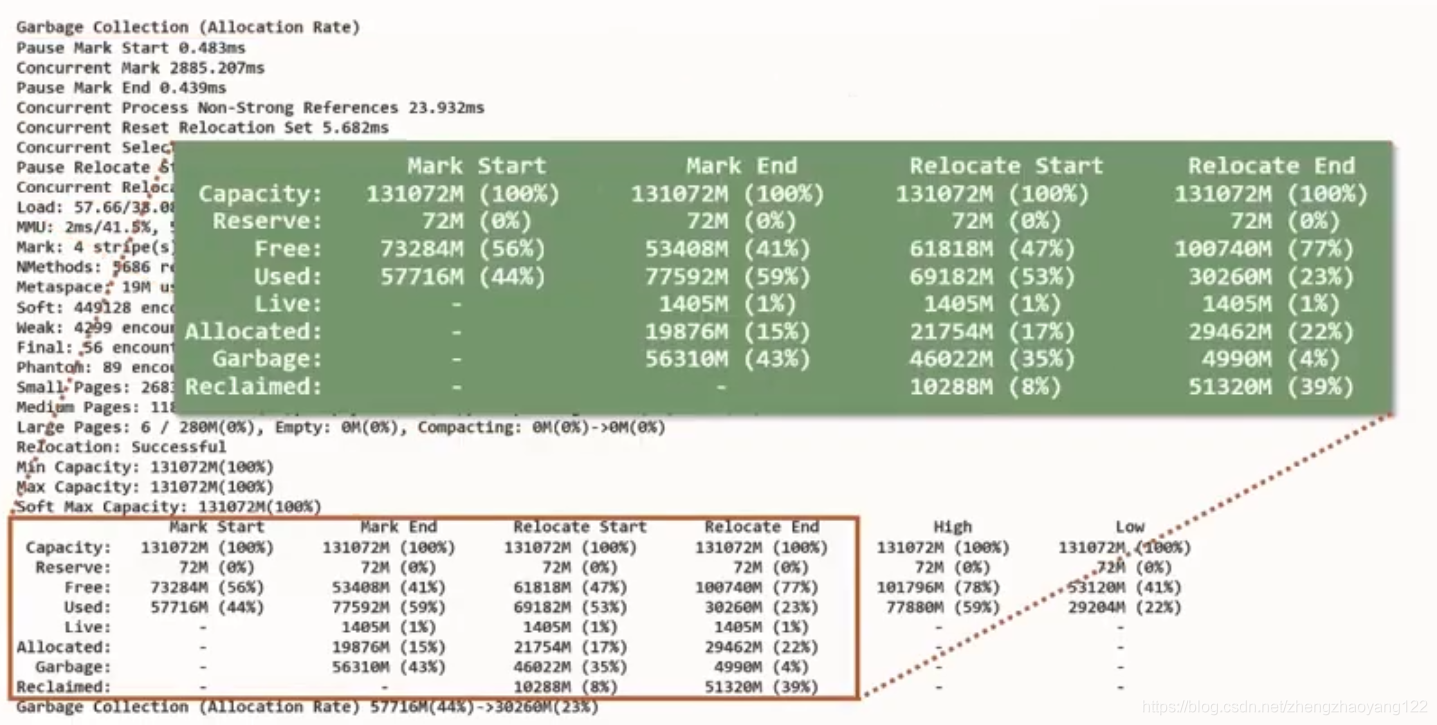
GC日志中每一行都注明了 GC过程中的信息,关键信息如下:
- Start:开始GC,并标明的 GC触发的原因。上图中触发原因是自适应算法。
- Phase-Pause Mark Start:初始标记,会STW。
- Phase-Pause Mark End:再次标记,会STW。
- Phase-Pause Relocate Start:初始转移,会STW。
- Heap信息:记录了 GC过程中 Mark、Relocate前后的堆大小变化状况。High和 Low记录了其中的最大值和最小值,我们一般关注 High中 Used的值,如果达到100%,在 GC过程中一定存在内存分配不足的情况,需要调整GC的触发时机,更早或者更快地进行GC。
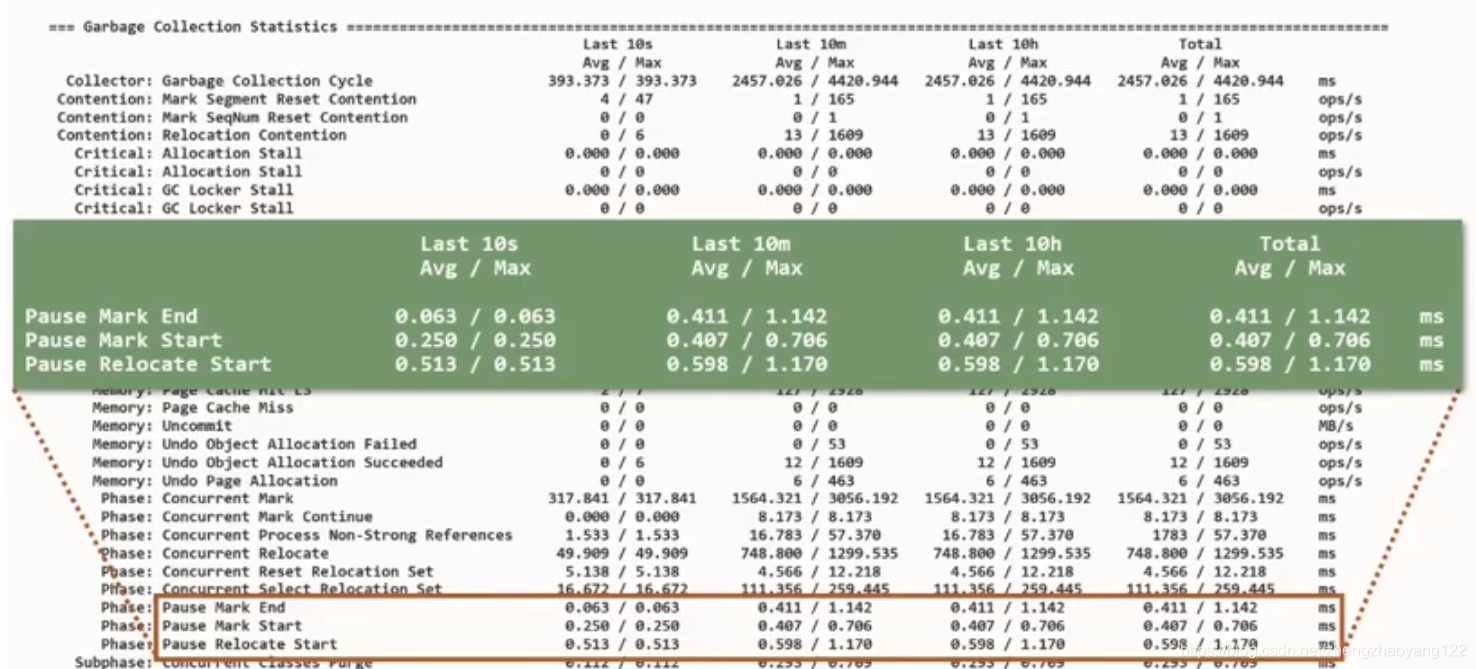
- GC信息统计:可以定时的打印垃圾收集信息,观察10秒内、10分钟内、10个小时内,从启动到现在的所有统计信息。利用这些统计信息,可以排查定位一些异常点。
当启动详细日志记录后,将会看到如下图,将会带有大量GC统计信息计数器的表格。UM这里的四列代表4个不同的时间窗口。日志中内容较多,再过去10秒10分钟内,从JVM启动以来总共10个小时,如果我们在这里选择几个示例,我们将看到分配比率应用程序,因此在某种程度上我们看到JVM从某个时候开始这个应用程序分配了一些东西,例如每秒13GB,但平均而言每秒2.2GB。

在这里,我们有时候统计数据,所以如果再看一下总计列,我们对所有的暂停都有一个总结,到目前为止,我们已经看到平均脉冲时间为大约半毫秒,此处的最大脉冲时间似乎是一个重新定位在 1.17毫秒处开始暂停。
# ZGC停顿原因
我们在实战过程中共发现了 6种使程序停顿的场景,分别如下:
- GC时,初始标记:日志中 Pause Mark Start。
- GC时,再标记:日志中 Pause Mark End。
- GC时,初始转移:日志中Pause Relocate Start。
- 内存分配阻塞:当内存不足时线程会阻塞等待 GC完成,关键字是 “Allocation Stall”。
# 理解 ZGC触发时机
相比于 CMS和 G1的 GC触发机制,ZGC的 GC触发机制有很大不同。ZGC的核心特点是并发,GC过程中一直有新的对象产生。如何保证在 GC完成之前,新产生的对象不会将堆占满,是 ZGC参数调优的第一大目标。因为在 ZGC中,当垃圾来不及回收将堆占满时,会导致正在运行的线程停顿,持续时间可能长达秒级之久。
ZGC有多种 GC触发机制,总结如下:
- 阻塞内存分配请求触发:当垃圾来不及回收,垃圾将堆占满时,会导致部分线程阻塞。我们应当避免出现这种触发方式。日志中关键字是“Allocation Stall”[分配内存暂停]。
- 基于分配速率的自适应算法:最主要的 GC触发方式,其算法原理可简单描述为 ”ZGC根据近期的对象分配速率以及GC时间,计算出当内存占用达到什么阈值时触发下一次GC”。自适应算法的详细理论可参考彭成寒《新一代垃圾回收器ZGC设计与实现》一书中的内容。通过 ZAllocationSpikeTolerance参数控制阈值大小,该参数默认2,数值越大,越早的触发GC。我们通过调整此参数解决了一些问题。日志中关键字是“Allocation Rate”。
- 基于固定时间间隔:通过 ZCollectionInterval控制,适合应对突增流量场景。流量平稳变化时,自适应算法可能在堆使用率达到95%以上才触发GC。流量突增时,自适应算法触发的时机可能会过晚,导致部分线程阻塞。我们通过调整此参数解决流量突增场景的问题,比如定时活动、秒杀等场景。日志中关键字是“Timer”。
- 主动触发规则:类似于固定间隔规则,但时间间隔不固定,是 ZGC自行算出来的时机,我们的服务因为已经加了基于固定时间间隔的触发机制,所以通过 -ZProactive参数将该功能关闭,以免GC频繁,影响服务可用性。 日志中关键字是“Proactive”。
- 预热规则:服务刚启动时出现,一般不需要关注。日志中关键字是“Warmup”。
- 外部触发:代码中显式调用 System.gc()触发。 日志中关键字是“System.gc()”。
- 元数据分配触发:元数据区不足时导致,一般不需要关注。 日志中关键字是“Metadata GC Threshold”。
# “智慧园区” BUG案例
# 案例: 单次 GC停顿时间30ms,与预期停顿10ms左右有较大差距
日志信息:观察 ZGC日志信息统计,“Pause Roots ClassLoaderDataGraph”一项耗时较长。
分析:dump内存文件,发现系统中有上万个 ClassLoader实例。我们知道 ClassLoader属于 GC Roots一部分,且 ZGC停顿时间与 GC Roots成正比,GC Roots数量越大,停顿时间越久。再进一步分析,ClassLoader的类名表明,这些 ClassLoader均由 Aviator组件生成。分析 Aviator源码,发现 Aviator对每一个表达式新生成类时,会创建一个 ClassLoader,这导致了 ClassLoader数量巨大的问题。在更高 Aviator版本中,该问题已经被修复,即仅创建一个 ClassLoader为所有表达式生成类。
解决方法:升级 Aviator组件版本,避免生成多余的 ClassLoader。
# 案例:服务启动后,运行时间越长,单次GC时间越长,重启后恢复
日志信息:观察 ZGC日志信息统计,“Pause Roots CodeCache”的耗时会随着服务运行时间逐渐增长。
分析:CodeCache空间用于存放 Java热点代码的 JIT编译结果,而 CodeCache也属于 GC Roots一部分。通过添加 -XX:+PrintCodeCacheOnCompilation参数,打印 CodeCache中的被优化的方法,发现大量的 Aviator表达式代码。定位到根本原因,每个表达式都是一个类中一个方法。随着运行时间越长,执行次数增加,这些方法会被 JIT优化编译进入到 Code Cache中,导致 CodeCache越来越大。
解决方法:JIT有一些参数配置可以调整 JIT编译的条件,但对于我们的问题都不太适用。我们最终通过业务优化解决,删除不需要执行的 Aviator表达式,从而避免了大量 Aviator方法进入 CodeCache中。
值得一提的是,我们并不是在所有这些问题都解决后才全量部署所有集群。即使开始有各种各样的毛刺,但计算后发现,有各种问题的 ZGC也比之前的 CMS对服务可用性影响小。所以从开始准备使用 ZGC到全量部署,大概用了 2周的时间。在之后的 3个月时间里,我们边做业务需求,边解决这些问题,最终逐个解决了上述问题,从而使 ZGC在各个集群上达到了一个更好表现。
# 九、附录
在生产环境升级JDK 11,使用 ZGC,大家最关心的可能不是效果怎么样,而是这个新版本用的人少,网上实践也少,靠不靠谱,稳不稳定。其次是升级成本会不会很大,万一不成功岂不是白白浪费时间。所以,在使用新技术前,首先要做的是评估收益、成本和风险。
评估收益:对于 JDK这种世界关注的程序,大版本升级所引入的新技术一般已经在理论上经过验证。我们要做的事情就是确定当前系统的瓶颈是否是新版本 JDK可解决的问题,切忌问题未诊断清楚就采取措施。评估完收益之后再评估成本和风险,收益过大或者过小,其他两项影响权重就会小很多。
以本文开头提到的案例为例,假设 GC次数不变(10次/分钟),且单次 GC时间从 40ms降低10ms。通过计算,一分钟内有100/60000 = 0.17%的时间在进行GC,且期间所有请求仅停顿10ms,GC期间影响的请求数和因 GC增加的延迟都有所减少。
评估成本:这里主要指升级所需要的人力成本。此项相对比较成熟,根据新技术的使用手册判断改动点。跟做其他项目区别不大,不再具体细说。在我们的实践中,两周时间完成线上部署,达到安全稳定运行的状态。后续持续迭代3个月,根据业务场景对 ZGC进行了更契合的优化适配。
评估风险:升级 JDK的风险可以分为三类:
【1】兼容性风险:Java程序 JAR包依赖很多,升级 JDK版本后程序是否能运行起来。例如我们的服务是从 JDK 8升级到JDK 11,需要解决较多 JAR包不兼容的问题。
【2】功能风险:运行起来后,是否会有一些组件逻辑变更,影响现有功能的逻辑。
【3】性能风险:功能如果没有问题,性能是否稳定,能稳定的在线上运行。
验证功能正确性:通过完备的单测、集成和回归测试,保证功能正确性。
经过分类后,每类风险的应对转化成了常见的测试问题,不再属于未知风险。风险是指不确定的事情,如果不确定的事情都能转化成可确定的事情,意味着风险已消除。
参考文章:https://wiki.openjdk.java.net/display/zgc/Main http://cr.openjdk.java.net/~pliden/slides/ZGC-Jfokus-2018.pdf