# 一、MySQL 5.6 并行复制架构
从MySQL 5.6.3版本开始就支持所谓的并行复制了,但是其并行只是基于schema的,也就是基于库的。如果用户的MySQL数据库实例中存在多个schema,对于从机复制的速度的确可以有比较大的帮助。但在一般的MySQL使用中,一库多表比较常见,所以MySQL 5.6的并行复制对真正用户来说属于雷声大雨点小,不太合适生产使用。
MySQL 5.6并行复制的架构如下所示:
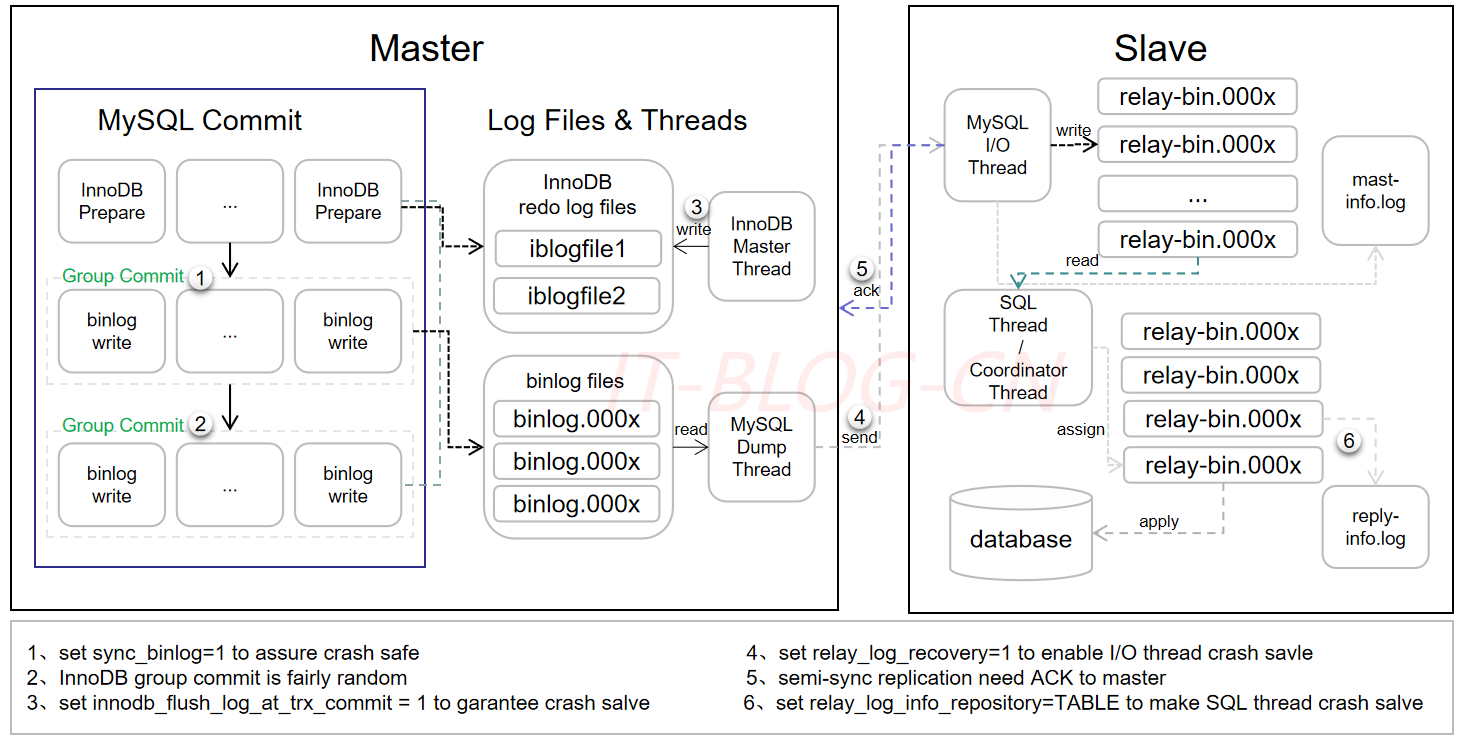
在MySQL 5.6版本之前,Slave服务器上有两个线程,分别是I/O线程和SQL线程。I/O线程负责接收二进制日志(更准确的说是二进制日志的event),SQL线程进行回放二进制日志。如果在MySQL 5.6版本开启并行复制功能,那么SQL线程就变为了coordinator(协调者)线程,coordinator线程主要负责两部分的内容:
【1】判断事务是否可以并行回放,若判断可以并行回放,那么选择worker线程执行事务的二进制日志。
【2】若判断不可以并行执行,如该操作是DDL,亦或者是事务跨schema操作,则等待所有的worker线程执行完成之后,再执行当前的日志。
这意味着coordinator线程并不是仅将日志发送给worker线程,自己也可以回放日志,但是所有可以并行的操作交付由worker线程完成。coordinator线程与worker是典型的生产者与消费者模型。
上述机制实现了基于schema的并行复制存在两个问题,首先是crash safe功能不好做,因为可能之后执行的事务由于并行复制的关系先完成执行,那么当发生crash的时候,这部分的处理逻辑是比较复杂的。从代码上看,5.6这里引入了Low-Water-Mark标记来解决该问题,从设计上看WL#5569,其是希望借助于日志的幂等性来解决该问题,不过5.6的二进制日志回放还不能实现幂等性。另一个最为关键的问题是这样设计的并行复制效果并不高,如果用户实例仅有一个库,那么就无法实现并行回放,甚至性能会比原来的单线程更差。而单库多表是比多库多表更为常见的一种情形。
# 二、MySQL 5.7 并行复制原理
MySQL 5.6基于库的并行复制出来后,基本无人问津,在沉寂了一段时间之后,MySQL 5.7出来了,它的并行复制以一种全新的姿态出现在了DBA面前。MySQL 5.7才可称为真正的并行复制,这其中最为主要的原因就是slave服务器的回放与master是一致的,即master服务器上是怎么并行执行的,那么slave上就怎样进行并行回放。不再有库的并行复制限制,对于二进制日志格式也无特殊的要求(基于库的并行复制也没有要求)。
从MySQL官方来看,其并行复制的原本计划是支持表级的并行复制和行级的并行复制,行级的并行复制通过解析ROW格式的二进制日志的方式来完成,WL#4648。但是最终出现给小伙伴的确是在开发计划中称为:MTS(Prepared transactions slave parallel applier),可见:WL#6314。该并行复制的思想最早是由MariaDB的Kristain提出,并已在MariaDB 10中出现。
MySQL 5.7中的并行复制实现思路: 从MySQL 5.7.17开始,增加了基于writeset的并行复制方式,简单来说就是提供了不一样的last_committed和sequence_number生成方式。目前为止归纳一下就是提供了三种生成last_committed和sequence_number的方式:
■ commit_order
■ writeset
■ writeset_session
其中commit_order就是基于group commit方式生成last_committed和sequence_number,另外两种生成算法由于内容也很多,就不在这篇文章介绍了。可以看相关文章。
# 组提交(group commit)
MySQL 5.6中引入Group Commit技术,这是为了解决事务提交的时候需要fsync导致并发性不够而引入的。简单来说,就是由于事务提交时必须将Binlog写入到磁盘上而调用fsync,这是一个代价比较高的操作,事务并发提交的情况下,每个事务各自获取日志锁并进行fsync会导致事务实际上以串行的方式写入Binlog文件,这样就大大降低了事务提交的并发程度。5.6中采用的Group Commit技术将事务的提交阶段分成了Flush,Sync,Commit三个阶段,每个阶段维护一个队列,并且由该队列中第一个线程负责执行该步骤,这样实际上就达到了一次可以将一批事务的Binlog fsync到磁盘的目的,这样的一批同时提交的事务称为同一个Group的事务。
Group Commit虽然是属于并行提交的技术,但是却意外的解决了从机上事务并行回放的一个难题————既如何判断哪些事务可以并行回放。如果一批事务是同时Commit的,那么这些事务必然不会互斥的持有锁,也不会有执行上的相互依赖,因此这些事务必然可以并行的回放。反过来说,如果有冲突,则后来的操作会等已经获取资源的事务完成之后才能继续,故而不会进入事务的prepare阶段。
因此MySQL 5.7中引入了新的并行回放类型,为了兼容MySQL 5.6基于库的并行复制,5.7引入了新的变量slave_parallel_type,其可以配置的值有:
■ DATABASE:基于库的并行复制方式
■ LOGICAL_CLOCK:基于组提交的并行复制方式
同时参数slave_parallel_workers是用来设置并发的worker线程数量。
注意slave_parallel_workers设置的worker线程的个数,且不包括coordinator协调线程,因此如果不想使用MTS,应该设置该参数为0,然后stop slave, start slave才能生效。因为worker线程是在启动的时候初始化完成的。如果将slave_parallel_workers设置为 1,则SQL线程功能转化为coordinator线程,但是只有1个worker线程进行回放,也是单线程回放。然而,这两种性能却又有一些的区别,因为多了一次coordinator线程的转发,因此slave_parallel_workers=1的性能反而比0还要差,测试下还有20%左右的性能下降。
那么如何知道事务是否在同一组中,又是一个问题,因为原版的MySQL并没有提供这样的信息。在MySQL 5.7版本中,其设计方式是将组提交的信息存放在GTID事件中。为了标记事务所属的组,MySQL 5.7版本在产生Binlog日志时会有两个特殊的值记录在Gtid Event中,last_committed和sequence_number, 其中last_committed指的是该事务提交时,上一个事务提交的sequence_number编号,sequence_number是事务提交的序列号,在一个Binlog文件内单调递增,只要换一个文件flush binary logs,这两个值就都会从0开始计数。如果两个事务的last_committed`值一致,这两个事务就是在一个组内提交的。
通过mysqlbinlog工具解析binlog文件,可以看到组提交的相关信息:
$ mysqlbinlog mysql-bin.0000006 | grep last_committed
#150520 14:23:11 server id 88 end_log_pos 259 CRC32 0x4ead9ad6 GTID last_committed=0 sequence_number=1
#150520 14:23:11 server id 88 end_log_pos 1483 CRC32 0xdf94bc85 GTID last_committed=0 sequence_number=2
#150520 14:23:11 server id 88 end_log_pos 2708 CRC32 0x0914697b GTID last_committed=0 sequence_number=3
#150520 14:23:11 server id 88 end_log_pos 3934 CRC32 0xd9cb4a43 GTID last_committed=0 sequence_number=4
#150520 14:23:11 server id 88 end_log_pos 5159 CRC32 0x06a6f531 GTID last_committed=0 sequence_number=5
#150520 14:23:11 server id 88 end_log_pos 6386 CRC32 0xd6cae930 GTID last_committed=0 sequence_number=6
#150520 14:23:11 server id 88 end_log_pos 14952 CRC32 0xf41181d3 GTID last_committed=1 sequence_number=7
#150520 14:23:11 server id 88 end_log_pos 8834 CRC32 0x96864e6b GTID last_committed=6 sequence_number=8
#150520 14:23:11 server id 88 end_log_pos 10057 CRC32 0x2de1ae55 GTID last_committed=6 sequence_number=9
#150520 14:23:11 server id 88 end_log_pos 11280 CRC32 0x5eb13091 GTID last_committed=6 sequence_number=10
#150520 14:23:11 server id 88 end_log_pos 12504 CRC32 0x16721011 GTID last_committed=6 sequence_number=11
#150520 14:23:11 server id 88 end_log_pos 13727 CRC32 0xe2210ab6 GTID last_committed=6 sequence_number=12
2
3
4
5
6
7
8
9
10
11
12
13
如上binlog文件中,sequence_number 1-6的事务last_committed都是0,因此属于同一个组,可以在从库上并行回放,sequence_number 8-12的last_committed都是6,也属于同一个组,因此可以并行回放。
在上面的并行执行中,last_committed = 1的事务需要等待last_committed = 0的6个事务完成后才能执行,同理,last_committed = 6的5个事务需要等待last_committed = 1的事务完成。但是MySQL 5.7还做了额外的优化,可进一步增大回放的并行度。思想是LOCK-BASED,即如果两个事务有重叠,则两个事务的锁依然是没有冲突的,依然可以并行回放。
在上面的例子中,last_committed = 1的事务可以和last_committed = 0的事务同时并行执行,因为事务有重叠,last_committed不是上一组事务最大sequence_number的值。具体来说,这表示last_committed = 0的事务进入到COMMIT阶段时,last_committed的事务进入到了 PREPARE阶段,即事务间依然没有冲突。具体实现思想可见官方的Worklog: WL#7165: MTS: Optimizing MTS scheduling by increasing the parallelization window on master
MySQL 5.7中引入的基于Logical_Lock极大的提高了在主机并发压力比较大的情况下,从机上的回放速度。基本上做到了主机上如何提交的,在从机上如何回放。
那么如果用户没有开启GTID功能,即将参数gtid_mode设置为OFF呢?故MySQL 5.7又引入了称之为Anonymous_Gtid(ANONYMOUS_GTID_LOG_EVENT)的二进制日志event类型,如:
mysql> SHOW BINLOG EVENTS in 'mysql-bin.000006';
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+----------------+-----------+-------------+-----------------------------------------------+
| mysql-bin.000006 | 4 | Format_desc | 88 | 123 | Server ver: 5.7.7-rc-debug-log, Binlog ver: 4 |
| mysql-bin.000006 | 123 | Previous_gtids | 88 | 194 | |
| mysql-bin.000006 | 194 | Anonymous_Gtid | 88 | 259 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| mysql-bin.000006 | 259 | Query | 88 | 330 | BEGIN |
| mysql-bin.000006 | 330 | Table_map | 88 | 373 | table_id: 108 (aaa.t) |
| mysql-bin.000006 | 373 | Write_rows | 88 | 413 | table_id: 108 flags: STMT_END_F
2
3
4
5
6
7
8
9
10
与GTID相关的几个事件:
【1】PREVIOUS_GTIDS_LOG_EVENT: 用于表示上一个binlog最后一个gitd的位置,每个binlog只有一个,当没有开启GTID时此事件为空。此事件的作用是master用来检验slave发送的gtid set是否合法。maser会先扫描最后一个binary log,拿到PREVIOUS_GTIDS_LOG_EVENT事件,然后检查slave需要拉取的gtid是否在此之后,是就结束,否则检查上一个binary log文件同样拿到PREVIOUS_GTIDS_LOG_EVENT事件,同样检查需要拉取的gtid是否再次之后,如此循环直到找到为止。
【2】GTID_LOG_EVENT: 当开启GTID时,每一个操作语句DML/DDL执行前就会添加一个GTID事件,记录当前全局事务ID;同时在MySQL 5.7版本中,组提交信息也存放在GTID事件中,有两个关键字段last_committed,sequence_number就是用来标识组提交信息的。在InnoDB中有一个全局计数器global counter,在每一次存储引擎提交之前,计数器值就会增加。在事务进入prepare阶段之前,全局计数器的当前值会被储存在事务中,这个值称为此事务的commit-parent(也就是last_committed)。
【3】ANONYMOUS_GTID_LOG_EVENT: 在MySQL 5.7版本中即使不开启GTID,每个事务开始前也是会存在一个Anonymous_Gtid,而这个Anonymous_Gtid事件中就存在着组提交的信息。反之,如果开启了GTID后,就不会存在这个Anonymous_Gtid了,从而组提交信息就记录在非匿名GTID事件中。
总结一下,从上面的描述可以看出,不管是基于GTID方式复制,还是file+postion方式复制,在MySQL 5.7版本都可以使用MTS技术。但不建议在非GTID模式下使用MTS技术,因为无法保证从库crash safe;而在GTID模式下则可以保证从库crash safe。
# 事务两阶段提交
事务的提交主要分为两个主要步骤:
【1】Prepare Phase: 调用prepare接口完成第一阶段,具体会做Binlog Prepare,实际上什么也没做,然后做InnoDB Prepare,此时SQL已经成功执行,并生成xid信息及redo和undo日志,并将事务状态设为TRX_STATE_PREPARED。
【2】Commit Phase:
■ 记录协调者日志,即Binlog日志:如果事务涉及的所有存储引擎的prepare都执行成功,则调用TC_LOG_BINLOG::log_xid方法将SQL语句写到binlog(write 将binary log内存日志数据写入文件系统缓存,fsync将binary log文件系统缓存日志数据永久写入磁盘)。此时,事务已经铁定要提交了。否则,调用ha_rollback_trans方法回滚事务,而SQL语句实际上也不会写到binlog。
■ 告诉引擎做commit:最后,调用引擎做commit完成事务的提交。会清除undo信息,刷redo日志,将事务设为TRX_NOT_STARTED状态。
# ordered_commit
关于MySQL是如何提交的,内部使用ordered_commit函数来处理的。先看它的逻辑图,如下:
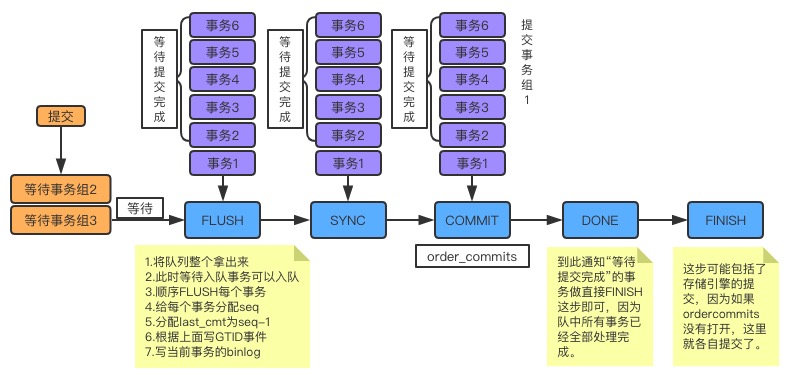
从图中可以看到,只要事务提交(调用ordered_commit方法),就都会先加入队列中。而提交有三个步骤,包括FLUSH、SYNC及COMMIT,相应地也有三个队列。首先要加入的是FLUSH队列,如果某个事务加入时,队列还是空的,则这个事务就担任leader,来代表其他事务执行提交操作。而在其他事务继续加入时,就会发现此时队列已经不为空了,那么这些事务就会等待leader帮它们完成提交操作。在上图中,事务2-6都是这种坐享其成之辈,事务1就是leader了。不过这里需要注意一点,不是说leader会一直等待要提交的事务不停地加入,而是有一个时限,只有在这个时限之内成功加入到队列的,才能帮它提交。这个时限就是从队长加入开始,到它去处理队列的时间,这个时间实际非常小,基本上就是程序从这行到哪行的一个过程,也没有刻意去等待,不然事务响应时间就会拉长。
只要对leader将这个队列中的事务取出,其他事务就可以加入这个队列了。第一个加入的还是leader,但此时必须要等待。因为此时有事务正在做FLUSH,做完FLUSH之后,其他的leader才能带着队员做FLUSH。而在同一时刻,只能有一个组在做FLUSH。这就是上图中所示的等待事务组2和等待事务组3,此时队长会按照顺序依次做FLUSH,做FLUSH的过程中,有一些重要的事务需要去做,如下:
【1】要保证顺序必须是提交加入到队列的顺序。
【2】如果有新的事务提交,此时队列为空,则可以加入到FLUSH队列中。不过,因为此时FLUSH临界区正在被占用,所以新事务组必须要等待。
【3】给每个事务分配sequence_number,如果是第一个事务,则将这个组的last_committed设置为sequence_number: -1。否则last_committed是在binlog prepare阶段就会获取,值为上一个COMMIT队列最大sequence_number。
【4】将带着 last_committed 与 sequence_number 的 GTID 事件写入到 Binlog 文件中,这里是直接写入 binlog 文件,而不经过 binlog cache,所以 GTID 事件是这个事务的第一个事件。
【5】将当前事务所产生的Binlog内容写入到Binlog文件中,这里就是把binlog cache内容刷新到binlog文件。
这样,一个事务的FLUSH就完成了。接下来,依次做完组内所有事务的FLUSH,然后做SYNC。如果SYNC的临界区是空的,则直接做SYNC操作,而如果已经有事务组在做,则必须要等待。同样地,做完FLUSH之后,FLUSH临界区会空闲出来,那么此时再等待这个临界区的组就可以做FLUSH操作了。总而言之,每个步骤都会有事务组在做, 就像一个流水线一样。完成一件产品需要三个工序,每个工序都可以批量来做,那么每个工序车间都不会闲着,都一直重复着相同的事情,最终每个产品都是以完全相同的顺序完成。
到COMMIT时,实际做的是存储引擎提交,参数binlog_order_commits会影响提交行为。如果设置为ON,那么此时提交就变为串行操作了,就以队列的顺序为提交顺序。而如果设置为OFF,提交就不会在这里进行,而会在每个事务(包括队长和队员)做finish_commit(FINISH)时各自做存储引擎的提交操作。组内每个事务做finish_commit是在队长完成COMMIT工序之后进行,到步骤DONE时,便会唤醒每个等待提交完成的事务,告诉他们可以继续了,那么每个事务就会去做finish_commit。而后,自己再去做finish_commit。这样,一个组的事务就都按部就班地提交完成了。现在也可以知道,与这个组中同时在做提交的最多还有另外两个事务,一个是在做FLUSH,一个是在做SYNC。
现在应该搞明白关于order commit的原理了,而这也是LOGICAL_CLOCK并行复制的基础。因为order commit使得所有的事务分了组,并且有了序列号,从库拿到这些信息之后,就可以根据序号放心大胆地做分发了。
但是有没有发现一个问题,每个组的事务数都没有做过特殊处理。因为从时间上说,从leader开始入队,到取队列中的所有事务出来,这之间的时间是非常非常小的,其实就是几行代码的事,也不会有任何费时间的操作,所以在这段时间内其实不会有多少个事务。只有在压力很大,提交的事务非常多的时候,才会提高并发度(组内事务数变大)。不过这个问题也可以解释得通,主库压力小的时候,从库何必要那么大的并发度呢?只有主库压力大的时候,从库才会延迟。
这种情况下也可以通过调整主服务器上的参数binlog_group_commit_sync_delay、binlog_group_commit_sync_no_delay_count。前者表示事务延迟提交多少时间来加大整个组提交的事务数量,从而减少进行磁盘刷盘sync的次数,单位为1/1000000秒,最大值1000000也就是1秒;后者表示组提交的事务数量凑齐多少此值时就跳出等待,然后提交事务,而无需等待binlog_group_commit_sync_delay的延迟时间;但是binlog_group_commit_sync_no_delay_count也不会超过binlog_group_commit_sync_delay设置。几个参数都是为了增加主服务器组提交的事务比例,从而增大从机MTS的并行度。
# 三、重要数据结构
Relay_log_info(sql/rpl_rli.h)对应协调线程,在MTS之前对应SQL线程,为了支持并行复制,在原来的基础上又加了一些成员。
- mapping_db_to_worker // 非常重要的成员,类型是HASH,用于缓存所有的分发关系,APH(Assigned Partition Hash),目的能通过 db 快速找到映射关系,但 HASH 长度大于 mts_partition_hash_soft_max(固定16)时,会对没有使用的映射关系进行回收。
- workers // 类型是 DYNAMIC_ARRAY,成员是一个个 Slave_worker
- pending_jobs // 一个统计信息,表示待执行 job 个数
- mts_slave_worker_queue_len_max // 每个 worker 最多能容纳 jobs 的个数,目前 hard code 是 16384
- mts_pending_jobs_size // 所有 worker 的 job 占的内存
- mts_pending_jobs_size_max // 所有 worker 的 job 占的内存,对应配置 slave_pending_jobs_size_max
- mts_wq_oversize // 标示 job 占用内存已达上限
- gaq // 非常重要的成员,代码注释里经常提到的 GAQ,类型是 Slave_committed_queue,存的成员是 Slave_job_group,大小对应配置 slave-checkpoint-group,用于W和C交互
- curr_group_assigned_parts // 类型是 DYNAMIC_ARRAY,当前 group 中已经分配的 event 的映射关系,可以和 Slave_worker 的 curr_group_exec_parts 对应,简写 CGAP
- curr_group_da // 类型是 DYNAMIC_ARRAY,对于还无法决定分发 worker 的 event,先存在这里
- mts_wq_underrun_w_id // 标识比较空闲的 worker 的 id
- mts_wq_excess_cnt // 标示 worker 的超载情况
- mts_worker_underrun_level // 当 worker 的任务队列大小低于这个值的认为处于饥饿状态
- mts_coordinator_basic_nap // 当 worker 负载较大时,协调线程 sleep,会用到这个值
- opt_slave_parallel_workers // 对应配置 slave_parallel_workers
- slave_parallel_workers // 当前实际的 worker 数
- exit_counter // 退出时用
- max_updated_index // 退出时用
- rli_checkpoint_seqno // 统计最新一次 checkpoint 后分发的 group 个数
- checkpoint_group // 对应配置 mts_checkpoint_group
- recovery_groups // 类型是 MY_BITMAP,恢复时用到
- mts_group_status // 分发线程所处的状态,取值为 MTS_NOT_IN_GROUP、MTS_IN_GROUP、MTS_END_GROUP、MTS_KILLED_GROUP
- mts_events_assigned // 分发的 event 计数
- mts_groups_assigned // 分发的 group 计数
- least_occupied_workers // 类型是 DYNAMIC_ARRAY,从注释将 worker 按从空闲到繁忙排序的一个数组,用于先 worker 用,但是实际并未用到。
- last_clock // 上次做 checkpoint 的时间
- last_master_timestamp // 记录最后一次读取 event 的时间, MTS 下记录 checkpoint 位置事务执行结束时间
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
circular_buffer_queue(sql/rpl_rli_pdb.h)用DYNAMIC_ARRAY arrary实现的一个首尾相连的环形队列,是其他重要数据结构的基类。
- Q // 底层用到的 DYNAMIC_ARRAY
- size // 队列的容量
- avail // 队列尾
- entry // 队列头
- len // 队列实际大小
- de_queue() // 出队操作
- de_tail() // 尾部出队
- en_queue() // 入队操作
- head_queue() // 取队列头,但是不出队
2
3
4
5
6
7
8
9
Slave_committed_queue(sql/rpl_rli_pdb.h)维护分发执行的group信息,是circular_buffer_queue的子类,队列里存的是Slave_job_group。Relay_log_info->gap类型为Slave_committed_queue。
- group_master_log_name // 对应主库的 binlog 文件名
- group_master_log_pos // 对应在主库 binlog 中的位置
- group_relay_log_name // 对应备库 relay log 文件名
- group_relay_log_pos // 对应在备库 relay log 中的位置
- worker_id // 对应的 worker 的 id
- worker // worker 指针
- total_seqno // 当前 group 是启动以来执行的第几个 group
- master_log_pos // group 中 gtid event 的位置
- checkpoint_seqno // 当前 group 是从上次做完 checkpoint 后的第几个 group
- checkpoint_log_pos // worker 通过判断 checkpoint 信号决定是否更新, 两者通过变量交互
- checkpoint_log_name // 同上
- checkpoint_relay_log_pos // 同上
- checkpoint_relay_log_name // 同上
- done // 这个 group 是否已经被 worker commit 掉
- shifted // checkpoint 的时候出队事务的个数
- ts // 时间,更新 Seconds_behind_master
- reset() // 重置上面的成员变量
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Slave_jobs_queue(sql/rpl_rli_pdb.h)任务队列,也是circular_buffer_queue的子类,队列里存的是slave_job_item,每个worker有一个这样的任务队列。Slave_worker->jobs的类型为Slave_jobs_queue。
- overfill // 队列满标志
- waited_overfill // 队列满的次数
2
Slave_job_item: worker的jobs队列的成员。
- data // 就是一个 binlog event
# 四、协调线程分发机制
协调线程主体和之前的sql线程基本是一样的,入口函数handle_slave_sql。
/**
Slave SQL thread entry point.
@param arg Pointer to Relay_log_info object that holds information
for the SQL thread.
@return Always 0.
*/
extern "C" void *handle_slave_sql(void *arg) {
// 重要的循环
// 会判断 SQL 线程是否被用户关闭
while (!main_loop_error && !sql_slave_killed(thd, rli)) {
...
// read next event
mysql_mutex_lock(&rli->data_lock);
ev = applier_reader.read_next_event();
mysql_mutex_unlock(&rli->data_lock);
// try to execute the event
switch (exec_relay_log_event(thd, rli, &applier_reader, ev)) {
case ...
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
可以看到,关键就是循环不停的读取event,然后调用exec_relay_log_event函数。
这里是
MySQL 8.0的代码,在8.0之前读取可用的relay log函数在exec_relay_log_event函数中,同时之前的函数名字叫next_event,在8.0中叫read_next_event。
在exec_relay_log_event中,会根据一些条件选择是否更新last_master_timestamp,比如在并行复制模式和非并行复制模式下,更新last_master_timestamp的逻辑是不同的。此外就是调用apply_event_and_update_pos函数做event分发。除此之外还会调用mts_checkpoint_routine强制做checkpoint,后面会详细讲checkpiont过程。
static int exec_relay_log_event(THD *thd, Relay_log_info *rli,
Rpl_applier_reader *applier_reader,
Log_event *in) {
....
if (ev != nullptr) {
// 是否更新 last_master_timestamp
// 开启 MTS 时更新 last_master_timestamp 由 checkpoint 处理
if ((!rli->is_parallel_exec() || rli->last_master_timestamp == 0) &&
!(ev->is_artificial_event() || ev->is_relay_log_event() ||
ev->get_type_code() == binary_log::FORMAT_DESCRIPTION_EVENT ||
ev->server_id == 0)) {
rli->last_master_timestamp =
ev->common_header->when.tv_sec + (time_t)ev->exec_time;
DBUG_ASSERT(rli->last_master_timestamp >= 0);
}
// rli_checkpoint_seqno 表示 gaq 队列未出队的事务数量
// checkpoint_group 表示 gaq 队列大小, 参数 mts_checkpoint_group, 默认 512
bool force = rli->rli_checkpoint_seqno >= rli->checkpoint_group;
if (force || rli->is_time_for_mts_checkpoint()) {
mysql_mutex_unlock(&rli->data_lock);
if (mts_checkpoint_routine(rli, force)) {
delete ev;
return 1;
}
mysql_mutex_lock(&rli->data_lock);
}
exec_res = apply_event_and_update_pos(ptr_ev, thd, rli);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
apply_event_and_update_pos进行分发的入口是Log_event::apply_event。
apply_event_and_update_pos(Log_event **ptr_ev, THD *thd, Relay_log_info *rli) {
....
// 很多事情在这里做, 跳过 event, 延迟执行等等
....
// 应用分发 event
// apply_event 返回 0 表示分发成功,否则失败
// 然后通过判断 ev->worker 是否等于 rli 来判断此次分发是 worker 线程执行还是协调线程执行
exec_res = ev->apply_event(rli);
....
}
2
3
4
5
6
7
8
9
10
Log_event::apply_event会进行判断,如果没有开MTS,就是原来的逻辑,SQL线程直接执行event,调用do_apply_event函数,每个event类都实现了do_apply_event函数;如果开了MTS的话,调用Log_event::get_slave_worker,这个是分发的主逻辑。从库是以事务为单位做apply的,每个事务有一个GTID事件,从而都有last_committed及sequence_number值,主要就是根据这两个值来进行并行回放的。
/*
调度事件是以并行方式执行还是 SQL 线程直接执行
在 MTS 情况下,事件由协调线程或 worker 线程处理;在单线程顺序模式下事件映射到 SQL 线程 rli
@return 0 为成功,否则为失败
*/
int Log_event::apply_event(Relay_log_info *rli) {
// 是否进行 mts recovery
if (rli->is_mts_recovery()) {
// 如果是恢复, 这个地方就是前面恢复扫描出来的位置
bool skip = bitmap_is_set(&rli->recovery_groups, rli->mts_recovery_index) &&
(get_mts_execution_mode(rli->mts_group_status ==
Relay_log_info::MTS_IN_GROUP) ==
EVENT_EXEC_PARALLEL);
if (skip) {
return 0;
} else {
int error = do_apply_event(rli);
....
}
}
// 非 mts 调用 do_apply_event(rli)
// mts 调用 get_slave_worker(rli)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
我们这里主要看MTS下分发event的流程,下面分解一下Log_event::get_slave_worker都做了什么:
【1】如果是GTID_LOG_EVENT事件代表事务开始,则将本事务加入到GAQ队列中(GAQ下面会详细描述)。参考Log_event::get_slave_worker。
【2】将GTID_LOG_EVENT事件加入到curr_group_da队列中暂存。参考Log_event::get_slave_worker。
Slave_worker *Log_event::get_slave_worker(Relay_log_info *rli) {
// 初始化一个组, 类型是 Slave_job_group
Slave_job_group group = Slave_job_group(), *ptr_group = nullptr;
bool is_s_event;
// worker 类型是 Slave_worker
Slave_worker *ret_worker = nullptr;
char llbuff[22];
// gaq 类型是 Slave_committed_queue
// 存的成员是 Slave_job_group, 用于 worker 线程和协调线程交互
Slave_committed_queue *gaq = rli->gaq;
DBUG_TRACE;
// 如果是 BEGIN 或 GTID 事件表示事务(group)的开始
if ((is_s_event = starts_group()) || is_gtid_event(this) ||
// or DDL:s or autocommit queries possibly associated with own p-events
(!rli->curr_group_seen_begin && !rli->curr_group_seen_gtid &&
/*
the following is a special case of B-free still multi-event group like
{ p_1,p_2,...,p_k, g }.
In that case either GAQ is empty (the very first group is being
assigned) or the last assigned group index points at one of
mapped-to-a-worker.
*/
(gaq->empty() ||
gaq->get_job_group(rli->gaq->assigned_group_index)->worker_id !=
MTS_WORKER_UNDEF))) {
// 在 gaq 中分配队列序号 rli->mts_groups_assigned++
if (!rli->curr_group_seen_gtid && !rli->curr_group_seen_begin) {
rli->mts_groups_assigned++;
rli->curr_group_isolated = false;
// 将 group 入队 gaq, 并获取分发的 group 在 GAQ 中的索引位置
group.reset(common_header->log_pos, rli->mts_groups_assigned);
gaq->assigned_group_index = gaq->en_queue(&group);
// 判断事件类型为 begin or gtid
if (is_s_event || is_gtid_event(this)) {
Slave_job_item job_item = {this, rli->get_event_relay_log_number(),
rli->get_event_start_pos()};
// 入队 curr_group_da
rli->curr_group_da.push_back(job_item);
if (starts_group()) {
// 标记 begin event, 说明已经找到了
rli->mts_end_group_sets_max_dbs = true;
rli->curr_group_seen_begin = true;
}
if (is_gtid_event(this)) {
// 标记 gtid event, 说明已经找到了
rli->curr_group_seen_gtid = true;
Gtid_log_event *gtid_log_ev = static_cast<Gtid_log_event *>(this);
rli->started_processing(gtid_log_ev);
}
// 事务并发判断
if (schedule_next_event(this, rli)) {
rli->abort_slave = true;
if (is_gtid_event(this)) {
rli->clear_processing_trx();
}
return nullptr;
}
return ret_worker;
}
} else {
....
}
....
}
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
【3】获取GTID_LOG_EVENT事件中的last_committed及sequence_number值,决定是否分配下一个event到worker线程。可参考函数Mts_submode_logical_clock::schedule_next_event。
【4】获取current_lwm值,代码里面叫last_lwm_timestamp,这个值代表的是所有在GAQ队列上还没有提交完成事务中最早的那个事务的前一个已经提交事务的sequence_number(rli->gaq->lwm.sequence_number),但可能后面的事务已经提交完成了,听起来可能比较拗口但很重要。如果都提交完成了,那么就是取最新提交事务的sequence_number,下面的图表达的就是这个意思,这个图是源码中的。这个值的获取可参考函数Mts_submode_logical_clock::get_lwm_timestamp。
@verbatim
the last time index containg lwm
+------+
| LWM |
| | |
V V V
GAQ: xoooooxxxxxXXXXX...X
^ ^
| | LWM+1
|
+- tne new current_lwm
<---- logical (commit) time ----
@endverbatim
2
3
4
5
6
7
8
9
10
11
12
13
14
我们可以先不看lwm部分,对于检查点的lwm后面讨论。sequence_number从右向左递增,在GAQ中实际上有三种值:
■ X:已经做了检查点,在GAQ中出队的事务。
■ x:已经提交完成的事务。
■ o:没有提交完成的事务。
我们可以看到我们需要获取的current_lwm并不是最新一次提交事务的sequence_number的值,而是最早未提交事务的前一个已经提交事务的sequence_number,这里就是x。这一点很重要,因为理解后就会知道大事务是如何影响MTS的并行回放的,同时中间的5个o实际上就是所谓的gap,后面会描述。
【5】会检查当前事务是否和正在执行的事务冲突,将GTID_LOG_EVENT事件中的last_committed和当前current_lwm进行比较。可以参考函数Mts_submode_logical_clock::schedule_next_event。基于COMMIT_ORDER和WRITESET的都使用这个方法。
下面是大概的比较规则:
■ 如果last_committed大于current_lwm,同时该事务前面还有其他事务执行,则表示不能进行并行回放,这个时候协调线程就需要等待了,直到确认没有冲突事务或者前面的事务已经执行完。条件成立后协调线程会被worker线程唤醒。等待期间状态被置为Waiting for dependent transaction to commit。
■ 其余的条件表示都可以并行回放,比如last_committed小于等于current_lwm时。这里last_committed等于current_lwm的时候,实际这两个值拥有事务的Lock Interval(锁定间隔) 是没有重叠的,没有重叠是可能有冲突的。一般这种情况是前面一个事务执行结束,后面一个事务获取到last_committed为前面一个事务的sequence_number的情况时,他们的Lock Interval没有重叠。但由于current_lwm表示的是已经提交的事务,所以等于的时候,该事务也可以执行。当last_committed小于current_lwm时,要么是同一组的事务,要么是有重叠的事务,自然可以并行。
Mts_submode_logical_clock::schedule_next_event
int Mts_submode_logical_clock::schedule_next_event(Relay_log_info* rli,
Log_event *ev)
{
if (!is_new_group)
{
longlong lwm_estimate = estimate_lwm_timestamp();
if (!clock_leq(last_committed, lwm_estimate) && // 如果 last_committed > lwm_estimate
rli->gaq->assigned_group_index != rli->gaq->entry) // 当前事务前面还有执行的事务
{
...
// 等待没有冲突事务或者前面的事务都已经执行完
if (wait_for_last_committed_trx(rli, last_committed, lwm_estimate))
...
}
...
}
}
bool Mts_submode_logical_clock::wait_for_last_committed_trx(Relay_log_info* rli,
longlong last_committed_arg,
longlong lwm_estimate_arg)
{
...
min_waited_timestamp.store(last_committed_arg); // 设置 min_waited_timestamp 等待标志
...
if ((!rli->info_thd->killed && !is_error) &&
!clock_leq(last_committed_arg, get_lwm_timestamp(rli, true))) // 真实获取 lwm 并检查当前是否有冲突事务
{
// 循环等待直到没有冲突事务
do {
mysql_cond_wait(&rli->logical_clock_cond, &rli->mts_gaq_LOCK);
} while ((!rli->info_thd->killed && !is_error) &&
!clock_leq(last_committed_arg, estimate_lwm_timestamp()));
min_waited_timestamp.store(SEQ_UNINIT); // 重置等待标志
...
} else {
min_waited_timestamp.store(SEQ_UNINIT);
mysql_mutex_unlock(&rli->mts_gaq_LOCK);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
上面循环等待的时候,会等待logical_clock_cond条件然后做检查。该条件的唤醒逻辑是:当回放事务结束,如果存在等待的事务,即检查min_waited_timestamp和当前curr_lwm(lwm同时会被更新),如果min_waited_timestamp小于等于curr_lwm,则唤醒等待的coordinator线程。
【6】如果是QUERY_EVENT事件则初始化一个Slave_job_item,加入到curr_group_da队列中暂存。
【7】如果是MAP_EVENT事件进行worker线程的分配。参考函数Mts_submode_logical_clock::get_least_occupied_worker,分配worker线程如下:
■ 如果有空闲的worker线程则分配完成,继续。
■ 如果没有空闲的worker线程则等待空闲的worker线程。这种情况下状态会置为Waiting for slave workers to process their queues。
然后会回到apply_event_and_update_pos函数,将GTID_LOG_EVENT 事件和 QUERY_EVENT事件分配给worker线程,具体入worker线程队列可参考append_item_to_jobs函数。
函数append_item_to_jobs入队的时候会检查worker线程的任务队列是否已满,如果满了则需要等待,状态置为Waiting for Slave Worker queue。因为分配的单位是event,对于一个事务而言可能包含很多event,如果worker线程应用的速度赶不上协调线程入队的速度,可能导致任务队列的积压,因此任务队列被占满是可能的。任务队列的大小为16384,当前由变量mts_slave_worker_queue_len_max硬编码。每等待一次,就会累加rli->mts_wq_overfill_cnt++操作。
另外,分配前还会对event大小进行检查。如果是big event(event size大于slave_pending_jobs_size_max但小于slave_max_allowed_packet),它将等待worker队列中的所有任务完成。如果是正常的事件(event size小于slave_pending_jobs_size_max),event size+ 已经在等待的任务大小超过slave_pending_jobs_size_max,则它将等待有足够的可用内存时将事件添加到worker队列中。设置此变量对未启用多线程的从库没有影响。另外,设置此变量不会立即生效,变量的状态适用于所有后续start slave命令。此变量的最小可能值为1MB,默认值为 128MB,最大可能值为18446744073709551615(16艾字节)。内存足够,或者延迟较大时,可以适当调大。
接收器线程(
I/O线程) 负责限制事件大小到slave_max_allowed_packet。如果来自主库的事件大于此值slave_max_allowed_packet,IO线程将停止,并报ER_NET_PACKET_TOO_LARGE错误。
【8】MAP_EVENT事件分配给worker线程,同上。
【9】ROWS_EVENT事件分配给相同worker线程,同上。
【10】XID_EVENT事件分配给相同worker线程,同上。但是这里还需要额外的处理,主要处理一些和检查点相关的信息,在get_slave_worker函数中。
Slave_worker *Log_event::get_slave_worker(Relay_log_info *rli) {
....
if (ends_group() ||
(!rli->curr_group_seen_begin &&
(get_type_code() == binary_log::QUERY_EVENT || !rli->curr_group_seen_gtid))) {
....
// 判断 worker->checkpoint_notified 不为 true 就在 group 中填写 checkpoint 信息
// 填写完毕后会把 worker->checkpoint_notified 设置为 true
// 在 checkpoint 时会把 worker->checkpoint_notified 设置为 false
if (!ret_worker->checkpoint_notified) {
// 通过 rli->gaq->assigned_group_index 索引获取 GAQ 队列中的 group 信息
if (!ptr_group)
ptr_group = gaq->get_job_group(rli->gaq->assigned_group_index);
ptr_group->checkpoint_log_name = my_strdup(
key_memory_log_event, rli->get_group_master_log_name(), MYF(MY_WME));
ptr_group->checkpoint_log_pos = rli->get_group_master_log_pos();
ptr_group->checkpoint_relay_log_name = my_strdup(
key_memory_log_event, rli->get_group_relay_log_name(), MYF(MY_WME));
ptr_group->checkpoint_relay_log_pos = rli->get_group_relay_log_pos();
// ret_worker->bitmap_shifted 为 checkpoint 后出队事务的个数
// 用于后面提交的时候改变参考 Slave_worker::commit_positions
// ret_worker->bitmap_shifted 设置参考 mts_checkpoint_routine()
ptr_group->shifted = ret_worker->bitmap_shifted;
// 重置偏移值
ret_worker->bitmap_shifted = 0;
ret_worker->checkpoint_notified = true;
}
// 获取并设置本事务的序号
// 通过 rli->rli_checkpoint_seqno 赋值给 ptr_group->checkpoint_seqno
// rli->rli_checkpoint_seqno 这个值会在 checkpoint 后减去出队事务数量
ptr_group->checkpoint_seqno = rli->rli_checkpoint_seqno;
// Seconds_behind_master 有关
// 获取 xid_event header timestamp 存储在 Slave_job_group
// checkpoint 的时候会将这个值再次传递给 mts_checkpoint_routine() 使用
ptr_group->ts = common_header->when.tv_sec + (time_t)exec_time;
// 增加 seqno 序号
rli->rli_checkpoint_seqno++;
}
....
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
这里关注一点如下:如果检查点处于这个事务上,那么这些信息会出现在表slave_worker_info中,并且会出现在show slave status中。也就是说,show slave status中很多信息是来自MTS的检查点。后面具体描述。
需要注意,Log_event::get_slave_worker每个event的处理流程完成后,都会回到上层Log_event::apply_event函数,然后会回到apply_event_and_update_pos函数,接着MTS逻辑才进行,也就是入队到worker中去。
apply_event_and_update_pos(Log_event **ptr_ev, THD *thd, Relay_log_info *rli) {
....
// 执行 event 分发
exec_res = ev->apply_event(rli);
....
if (!exec_res && (ev->worker != rli)) {
if (ev->worker) {
// 初始化 map event 的 Slave_job_item
Slave_job_item item = {ev, rli->get_event_relay_log_number(),
rli->get_event_start_pos()};
Slave_job_item *job_item = &item;
Slave_worker *w = (Slave_worker *)ev->worker;
// specially marked group typically with OVER_MAX_DBS_IN_EVENT_MTS db:s
bool need_sync = ev->is_mts_group_isolated();
// Reset mts in-group state
if (rli->mts_group_status == Relay_log_info::MTS_END_GROUP) {
// CGAP cleanup
rli->curr_group_assigned_parts.clear();
// reset the B-group and Gtid-group marker
rli->curr_group_seen_begin = rli->curr_group_seen_gtid = false;
rli->last_assigned_worker = nullptr;
}
// 设置 ev 属于在 gaq 中的位置
ev->mts_group_idx = rli->gaq->assigned_group_index;
bool append_item_to_jobs_error = false;
// 当 curr_group_da 队列不为空时,首先进行 gtid 和 query event 入队
if (rli->curr_group_da.size() > 0) {
// 当前事件已排序,该部分为当前组属于。现在是处理延迟数组事件的时间
for (uint i = 0; i < rli->curr_group_da.size(); i++) {
Slave_job_item da_item = rli->curr_group_da[i];
DBUG_PRINT("mts", ("Assigning job %llu to worker %lu",
(da_item.data)->common_header->log_pos, w->id));
da_item.data->mts_group_idx =
rli->gaq->assigned_group_index; // similarly to above
if (!append_item_to_jobs_error)
append_item_to_jobs_error = append_item_to_jobs(&da_item, w, rli);
if (append_item_to_jobs_error) delete da_item.data;
}
rli->curr_group_da.clear();
}
// 然后 map/row/xid event 自己入队列
if (append_item_to_jobs(job_item, w, rli))
return SLAVE_APPLY_EVENT_AND_UPDATE_POS_APPEND_JOB_ERROR;
....
if (rli->is_parallel_exec() && rli->mts_events_assigned % 1024 == 1) {
time_t my_now = my_time(0);
// const long mts_online_stat_period = 60 * 2
// 如果每个 event 的前面的操作超过 120 秒, 则会出现警告日志
if ((my_now - rli->mts_last_online_stat) >= mts_online_stat_period) {
LogErr(INFORMATION_LEVEL, ER_RPL_MTS_STATISTICS,
rli->get_for_channel_str(),
static_cast<unsigned long>(my_now - rli->mts_last_online_stat),
rli->mts_events_assigned, rli->mts_wq_overrun_cnt,
rli->mts_wq_overfill_cnt, rli->wq_size_waits_cnt,
rli->mts_total_wait_overlap.load(),
rli->mts_wq_no_underrun_cnt, rli->mts_total_wait_worker_avail);
// 赋值当前时间
rli->mts_last_online_stat = my_now;
}
}
....
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
如果上面event的分配过程大于120秒,可能会出现一个日志如下:
[Note] Multi-threaded slave statistics for channel ”: seconds elapsed = 127; events assigned = 6959105; worker queues filled over overrun level = 0; waited due a Worker queue full = 0; waited due the total size = 0; waited at clock conflicts = 93948853900 waited (count) when Workers occupied = 0 waited when Workers occupied = 0
| 指标 | 描述 |
|---|---|
| seconds elapsed | 整个分配过程消耗的总时间,单位秒。超过120秒会出现这个日志。 |
| events assigned | 本worker线程分配的event数量。 |
| worker queues filled over overrun level | 本worker线程任务队列中event个数大于90%的次数,当前硬编码大于14746。 |
| Waited due to a Worker queue full | 本worker线程任务队列已满造成的等待次数,当前硬编码14746。 |
| Waited due to the total size | 由于worker队列未应用event达到slave_pending_jobs_size_max大小而造成协调线程等待的时间。 |
| slave_pending_jobs_size_max | big event出现的次数,big event就是event size大于slave_pending_jobs_size_max,但是小于slave_max_allowed_packet。 |
| Waited at clock conflicts | 由于不能并行回放,协调线程等待的时间,单位纳秒。 |
| Waited (count) when used occupied | 由于没有空闲的worker线程而导致协调线程等待的次数。 |
| waited when Workers occupied | 由于没有空闲的worker线程而导致协调线程等待的时间,单位纳秒。 |
我们可以看到这个日志还是记录很全的,基本覆盖了前面我们讨论的全部可能性。那么我们再看看案例中的日志,waited at clock conflicts = 93948853900,大于93秒。120秒中大约91秒都因为不能并行回放而造成的等待,很明显应该考虑是否有大事务的存在。
从上面的分析中我们一共看到了三个等待点:
■ Waiting for dependent transaction to commit: 由于协调线程判定本事务由于last_committed大于current_lwm,因此并不能并行回放,协调线程处于等待,大事务会加剧这种情况。
■ Waiting for slave workers to process their queues: 由于没有空闲的worker线程,协调线程会等待。这种情况说明理论上的并行度是理想的,但是可能是参数slave_parallel_workers设置不够。当然设置worker线程的个数应该和服务器的配置和负载相互结合考虑。
■ Waiting for Slave Worker queue: 由于worker线程的任务队列已满,协调线程会等待。这种情况前面说过是由于一个事务包含了过多的event,并且worker线程应用event的速度赶不上协调线程分配event的速度,导致了积压并且超过了16384个event。
■ Waiting for Slave Workers to free pending events: 由所谓的big event造成的,什么是big event呢?源码中描述为:event size大于slave_pending_jobs_size_max,但是小于slave_max_allowed_packet。出现的可能性并不大。可以在函数 append_item_to_jobs中找到答案。
# worker 线程执行 event
前面已经讨论了协调线程分发event的规则,实际上协调线程只是将event发到了worker线程的执行队列中。那么worker线程执行event就需要从执行队列中拿出这些event,然后进行执行。整个过程可以参考函数slave_worker_exec_job_group。
这个流程也比较简单,只需要关注一下如下几点:
【1】循环从执行队列中读取event,注意这里如果执行队列中没有event那么就进入空闲等待,也就是worker线程处于无事可做的状态,等待状态为Waiting for an event from Coordinator。参考slave_worker_exec_job_group函数。
【2】如果执行到XID_EVENT,那么说明事务已经结束了,那么需要完成内存信息更新操作。可参考Slave_worker::slave_worker_exec_event和Xid_apply_log_event::do_apply_event_worker函数。更新内存相关信息可参考函数Slave_worker::commit_positions函数。更新的信息基本和 slave_worker_info表中的信息基本一致。此外,还会更新worker线程的Bitmap信息。
【3】如果执行到XID_EVENT,那么说明事务已经结束了,那么需要完成内存信息的持久化。即强制刷内存信息持久化到slave_worker_info表中realy_log_info_repository设置为table
【4】如果执行到XID_EVENT,那么还需要进行事务的提交操作,也就是进行InnoDB层事务的提交。在Xid_apply_log_event::do_apply_event_worker函数中调用do_commit函数。
Slave_worker::commit_positions
bool Slave_worker::commit_positions(Log_event *ev, Slave_job_group *ptr_g,
bool force) {
DBUG_TRACE;
// 更新当前信息
if (ptr_g->group_master_log_name != nullptr) {
strmake(group_master_log_name, ptr_g->group_master_log_name,
sizeof(group_master_log_name) - 1);
my_free(ptr_g->group_master_log_name);
ptr_g->group_master_log_name = nullptr;
strmake(checkpoint_master_log_name, group_master_log_name,
sizeof(checkpoint_master_log_name) - 1);
}
// 更新 checkpoint 信息, relay log 和 master binlog 信息
// Slave_job_group 事务中的 checkpoint 信息由 XID_EVENT 分配时更新
if (ptr_g->checkpoint_log_name != nullptr) {
strmake(checkpoint_relay_log_name, ptr_g->checkpoint_relay_log_name,
sizeof(checkpoint_relay_log_name) - 1);
checkpoint_relay_log_pos = ptr_g->checkpoint_relay_log_pos;
strmake(checkpoint_master_log_name, ptr_g->checkpoint_log_name,
sizeof(checkpoint_master_log_name) - 1);
checkpoint_master_log_pos = ptr_g->checkpoint_log_pos;
my_free(ptr_g->checkpoint_log_name);
ptr_g->checkpoint_log_name = nullptr;
my_free(ptr_g->checkpoint_relay_log_name);
ptr_g->checkpoint_relay_log_name = nullptr;
// 复制一份 group_executed bitmap 为临时 group_shifted
bitmap_copy(&group_shifted, &group_executed);
// 清除 group_executed Bitmap
bitmap_clear_all(&group_executed);
// 更新 bitmap, 可能已经由 checkpoint 进行 GAQ 出队
// ptr_g->shifted 是 GAQ 中出队事务的个数, 由分配 xid_event 时 ptr_group->shifted = ret_worker->bitmap_shifted
for (uint pos = ptr_g->shifted; pos < c_rli->checkpoint_group; pos++) {
// 重新设置位图, 因为已经 checkpoint
if (bitmap_is_set(&group_shifted, pos))
// 这里就需要偏移掉出队的事务, 因为恢复的时候已经不需要了
bitmap_set_bit(&group_executed, pos - ptr_g->shifted);
}
}
// 提取更新的 relay log 文件名以存储在 Worker 的 rli 结构中
if (ptr_g->group_relay_log_name) {
DBUG_ASSERT(strlen(ptr_g->group_relay_log_name) + 1 <=
sizeof(group_relay_log_name));
strmake(group_relay_log_name, ptr_g->group_relay_log_name,
sizeof(group_relay_log_name) - 1);
}
DBUG_ASSERT(ptr_g->checkpoint_seqno <= (c_rli->checkpoint_group - 1));
// 设置 bitmap 位图, 在本次事务相应的位置设置为 1
// ptr_g->checkpoint_seqno 本事务的序号
bitmap_set_bit(&group_executed, ptr_g->checkpoint_seqno);
// worker 线程每次事务提交时设置对应的 checkpoint_seqno 值
worker_checkpoint_seqno = ptr_g->checkpoint_seqno;
// 更新事务对应的 relay log & master log 位置信息
group_relay_log_pos = ev->future_event_relay_log_pos;
group_master_log_pos = ev->common_header->log_pos;
strmake(group_master_log_name, c_rli->get_group_master_log_name(),
sizeof(group_master_log_name) - 1);
DBUG_PRINT("mts", ("Committing worker-id %lu group master log pos %llu "
"group master log name %s checkpoint sequence number %lu.",
id, group_master_log_pos, group_master_log_name,
worker_checkpoint_seqno));
DBUG_EXECUTE_IF("mts_debug_concurrent_access",
{ mts_debug_concurrent_access++; };);
// 刷盘操作, 将信息写入到表中
return flush_info(force);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
从上面我们可以看到MTS中每次事务的提交并不会更新slave_relay_log_info表,而是进行slave_worker_info表的更新,将最新的信息写入到slave_worker_info表中。我们前面也说过sql线程已经蜕变为协调线程,那么slave_relay_log_info表什么时候更新呢?下面我们就能看到 slave_relay_log_info表的更新实际上由协调线程在做完checkpoint之后更新。
MTS中的checkpoint: 总的说来MTS中的检查点是MTS进行异常恢复的起点,实际上就是代表到这个位置之前(包含自身)事务都是已经在从库执行过的,但之后的事务可能已经执行完成了,也可能没有执行完成,checkpoint由协调线程进行。
# 协调线程的 GAQ 队列
前面我们已经知道了MTS中为每个worker线程维护了一个event的分发队列,除此之外协调线程Relay_log_info->gaq还维护了一个非常重要的队列GAQ(Global Assigned Queue),其结构类型为Slave_committed_queue,属于circular_buffer_queue的子类,是用DYNAMIC_ARRAY arrary实现的一个首尾相连的环形队列,队列长度由slave_checkpoint_group参数定义,默认512。队列成员类型为Slave_job_group,主要维护一个正在执行的事务的信息,如对应的位点信息、事务分发到的worker、事务有没有执行完等等。由此可以看出GAQ用于协调线程和worker线程交互。
每次协调线程分发事务的时候都会将事务记录到GAQ队列中,因此GAQ中事务的顺序总是和relay log文件中事务的顺序一致的。检查点正是作用在GAQ队列上的,通过判断事务是否已经提交(判断Slave_job_group->done状态),把已经提交的事务移除GAQ队列,向前推进事务完成位置,每次推进的位置称为LWM(Low-Water-Mark),就是把移除的Slave_job_group事务信息赋值给LWM,它在GAQ队列中进行维护,源码变量名称就叫lwm,类型为Slave_job_group。
// 最新一次 checkpoint 时 Low-Water-Mark
Slave_job_group lwm;
2
在GAQ队列中还维护有一个叫做rli_checkpoint_seqno的变量,它是最后一次检查点以来每个分配事务的序号。
// 最新一次 checkpoint 后事务执行计数器
uint rli_checkpoint_seqno;
2
在协调线程读取到GTID_LOG_EVENT事件后为其分配序号,可参考get_slave_worker函数。
// 增加 rli_checkpoint_seqno
rli->rli_checkpoint_seqno++;
2
当协调线程进行检查点的时候,当遇到没有完成的事务时,就是遇到一个gap,表示对应worker还没执行完当前事务,checkpoint不能再向前推进了,到此结束。此时,就会使用rli_checkpoint_seqno序号减去此次出队的事务数量,那么这时的rli_checkpoint_seqno值对应的就是GAQ中事务Slave_job_group的个数,就是尚未被checkpoint出队的事务(可能已经被worker执行完了),对woker线程来说,这个对应当前worker执行到的事务编号。
// 减去出队的事务
rli_checkpoint_seqno = rli_checkpoint_seqno - shift;
2
在MTS异常恢复的时候也会用到这个序号,每个worker线程会通过这个序号来确认本worker线程执行事务的上限。如下:
// mts_recovery_group
for (uint i = (w->checkpoint_seqno + 1) - recovery_group_cnt,
j=0; i <= w->checkpoint_seqno; i++, j++)
{
// 如果这一位已经设置
if (bitmap_is_set(&w->group_executed, i))
{
DBUG_PRINT('mts', ("Setting bit %u.", j));
// 那么 group 这个 bitmap 中应该设置, 最终 groups 会包含全的需要恢复的事务
bitmap_fast_test_and_set(groups, j);
}
}
2
3
4
5
6
7
8
9
10
11
12
# worker 线程的 Bitmap
有了GAQ队列和检查点就知道异常恢复开始的位置了。但是我们并不知道每一个worker线程都完成了哪些事务,哪些又没有执行完成,因此就不能确认哪些事务需要恢复。在MTS中并行回放事务的提交并不是按分发顺序进行的,某些大事务(或者其他原因)可能迟迟不能提交,而一些小事务缺会很快提交完成。这些迟迟不能提交的事务就成为了所谓的gap,如果使用了GTID,那么在查看已经执行的gtid set的时候可能出现一些“空洞”,为了防止gap的发生,通常需要设置参数slave_preserve_commit_order,也就是顺序提交事务,但是如果要设置slave_preserve_commit_order参数,就需要开启从库记录binary log的功能,因此必须开启log_slave_update参数,这有关于从库crash safe。
这里简单说一下MTS恢复会有两个关键阶段:
■ 扫描阶段:通过扫描检查点以后的relay log,通过每个worker线程的Bitmap区分出哪些事务已经执行完成,哪些事务没有执行完成,并且汇总形成恢复Bitmap,同时得到需要恢复的事务总量。
■ 执行阶段:通过这个汇总恢复Bitmap,将这些没有执行完成的事务读取relay log再次执行。
这个Bitmap(Slave_worker->group_executed)位图和GAQ中的事务一一对应,与GAQ大小一致,由参数slave_checkpoint_group决定,默认512。worker线程每当执行XID_EVENT事件完成提交后,会在group_executed bitmap中将本事务位(也就是checkpoint_seqno位)设置为1。
# 协调线程信息的持久化
这个已经在前面提到过,实际上每次进行检查点的时候都需要将检查点的位置固化到slave_relay_log_info表中relay_log_info_repository设置为table。因此slave_relay_log_info中存储的实际上不是实时的信息,而是检查点的信息。随着MySQL版本不同,这个表的结构也一直在发生变化。与此同时,命令show slave status中的某些信息也是检查点的内存信息。比如下面的信息将是来自检查点:
■ Relay_Log_File:最新一次检查点的relay log文件名。
■ Relay_Log_Pos:最新一次检查点的relay log位点。
■ Relay_Master_Log_File:最新一次检查点的主库binary log文件名。
■ Relay_Master_Log_Pos:最新一次检查点的主库binary log位点。
■ Seconds_Behind_Master:根据检查点指向事务的提交XID_EVENT时间计算的延迟。
需要注意的是,我们的GTID模块独立在这一套理论之外,GTID模块的初始化是在从库信息初始化之前完成的。因此在做MTS异常恢复的时候使用gtid auto_position模式将会变的更加简单和安全。
# worker 线程信息的持久化
worker线程信息的持久化在slave_worker_info表中,前面我们描述worker线程执行event注意点的时候已经做了相应的描述。执行XID_EVENT完成事务提交之后会将信息写入到slave_worker_info表中,相关操作都是Slave_worker::commit_positions函数,其中包括信息:
■ Relay_log_name:工作线程最后一个提交事务的relay log文件名。
■ Relay_log_pos:工作线程最后一个提交事务的relay log位点。
■ Master_log_name:工作线程最后一个提交事务的主库binary log文件名。
■ Master_log_pos:工作线程最后一个提交事务的主库binary log位点。
■ Checkpoint_relay_log_name:工作线程最后一个提交事务对应检查点的relay log文件名。
■ Checkpoint_relay_log_pos:工作线程最后一个提交事务对应检查点的relay log位置。
■ Checkpoint_master_log_name:工作线程最后一个提交事务对应检查点的主库binary log文件名。
■ Checkpoint_master_log_pos:工作线程最后一个提交事务对应检查点的主库binary log位点。
■ Checkpoint_seqno:工作线程最后一个提交事务对应checkpoint_seqno序号。
■ Checkpoint_group_size:checkpoint_group_bitmap的长度,默认64字节512位,是阅读checkpoint_group_bitmap所必须的。
■ Checkpoint_group_bitmap:工作线程对应的Bitmap位图信息。
■ Channel_name:复制通道的名称。
这其中比较重要的就是Checkpoint_group_bitmap,记录哪些事务是执行过的,下面会介绍对bitmap的操作。
检查点运行的时机:
■ 距离上一次checkpoint的时间间隔达到slave_checkpoint_period参数配置的时间,运行一次检查点,默认300毫秒。
■ GAQ队列大小达到slave_checkpoint_group参数的值时强制运行检查点,默认512。
■ 正常stop slave。
一个例子: 通常有压力的情况下,slave_worker_info中的所有worker线程最大的Checkpoint_master_log_pos应该和slave_relay_log_info表中的Master_log_pos相等。因为这是最后一个检查点的位置信息。压力特别小的详情下,同样也会有类似现象。
mysql > select Checkpoint_master_log_name, Checkpoint_master_log_pos from mysql.slave_worker_info;
select Master_log_name, Master_log_pos from mysql.slave_relay_log_info;
+----------------------------+---------------------------+
| Checkpoint_master_log_name | Checkpoint_master_log_pos |
+----------------------------+---------------------------+
| mysql-bin.003029 | 274566299 |
| mysql-bin.003029 | 274276174 |
| mysql-bin.003029 | 257686176 |
| mysql-bin.003017 | 29777425 |
| mysql-bin.002967 | 1933832 |
| mysql-bin.002926 | 303991040 |
| mysql-bin.002926 | 303991040 |
| mysql-bin.002926 | 303991040 |
+----------------------------+---------------------------+
8 rows in set (0.00 sec)
+------------------+----------------+
| Master_log_name | Master_log_pos |
+------------------+----------------+
| mysql-bin.003029 | 274566299 |
+------------------+----------------+
1 row in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
可以看出,并行8个线程回放,由于压力不大,所以有很多线程已经很久没有执行事务了。
# MTS 中的 checkpoint 流程
这一部分将详细描述一下检查点的步骤,关于检查点可以参考mts_checkpoint_routine函数。
假设现在有7个事务是可以并行执行的,worker线程数量为4个。当前协调线程已经分发了5个,前面4个事务都已经执行完成,其中第5个事务是一个大事务。那么可能当前的状态图如下:
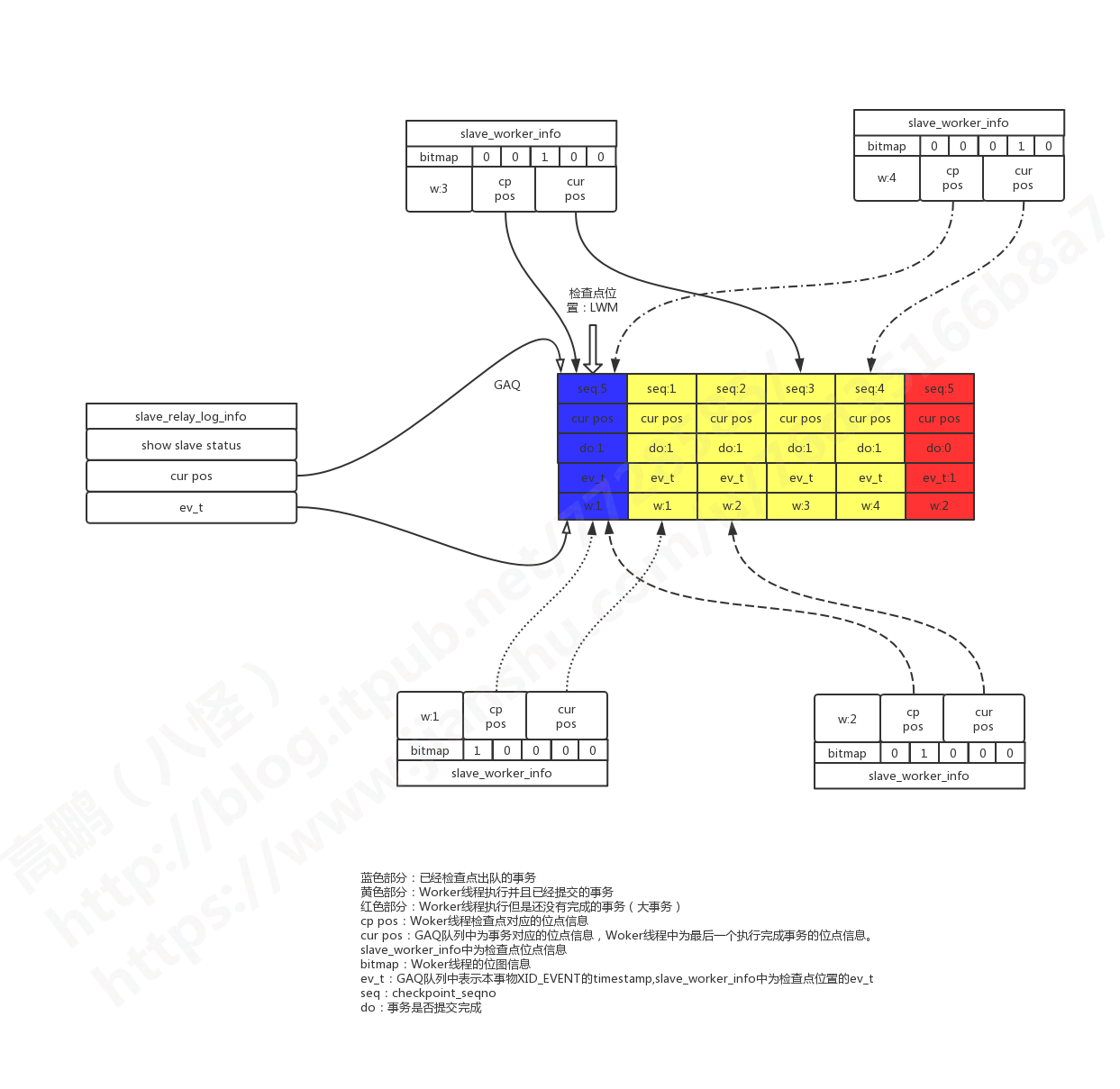
前面4个事务每个worker线程都分到一个,最后一个大事务这里假设由worker线程2进行执行,图中用红色部分表示。
【1】检查点被触发,调用mts_checkpoint_routine函数。
【2】扫描GAQ队列进行出队操作,直到第一个没有提交的事务为止。图中红色部分就是一个大事务,检查点只能停留在它之前。
bool mts_checkpoint_routine(Relay_log_info *rli, bool force) {
// 传入 worker 数组, 返回出队事务的个数
cnt = rli->gaq->move_queue_head(&rli->workers);
}
2
3
4
Slave_committed_queue::move_queue_head函数部分代码如下:
ulong Slave_committed_queue::move_queue_head(Slave_worker_array *ws) {
DBUG_TRACE;
ulong i, cnt = 0;
// 扫描 GAQ 队列
// len 队列实际长度
// size 队列大小
// avail 队列尾
// entry 队列头
// de_queue() 出队操作
// en_queue() 入队操作
for (i = entry; i != avail && !empty(); cnt++, i = (i + 1) % size) {
Slave_worker *w_i;
Slave_job_group *ptr_g;
char grl_name[FN_REFLEN];
grl_name[0] = 0;
ptr_g = &m_Q[i];
// ptr_g->done.load() == 1 表示事务执行完成, 0 表示未完成
// 当前事务是否已经执行完成, 如果没有执行完成就需要停止本次检查点
if (ptr_g->worker_id == MTS_WORKER_UNDEF || ptr_g->done.load() == 0)
break; /* gap at i'th */
/* Worker-id domain guard */
static_assert(MTS_WORKER_UNDEF > MTS_MAX_WORKERS, "");
w_i = ws->at(ptr_g->worker_id);
// 记住最新有效的 group_relay_log_name
if (ptr_g->group_relay_log_name) {
strcpy(grl_name, ptr_g->group_relay_log_name);
my_free(ptr_g->group_relay_log_name);
// 将字段标记为已释放, 非常重要
ptr_g->group_relay_log_name = nullptr;
}
// 从 (G)lobal (A)ssigned (Q)ueue 移除 job
Slave_job_group g = Slave_job_group();
#ifndef DBUG_OFF
ulong ind =
#endif
de_queue(&g);
// 推进 lwm
// 将记住的名称存储到结果结构中
// 请注意,我们首先处理指针,然后通过分配结构复制其他元素
if (grl_name[0] != 0) {
strcpy(lwm.group_relay_log_name, grl_name);
}
g.group_relay_log_name = lwm.group_relay_log_name;
lwm = g;
#ifndef DBUG_OFF
{
ulonglong l = last_done[w_i->id];
// 必须有一些进展,否则我们应该早点退出循环
DBUG_ASSERT(l < ptr_g->total_seqno);
}
#endif
// 这用于计算每个 worker 线程上次处理事件的时间
last_done[w_i->id] = ptr_g->total_seqno;
}
DBUG_ASSERT(cnt <= size);
// 返回值就是退出前已经推进的 group 个数
return cnt;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
【3】先更新内存信息为本次检查点指向的位置,也就是我们show slave status时看到的信息,然后强制写入slave_relay_log_info表relay_log_info_repository为table。
【4】更新last_master_timestamp信息为检查点位置事务的XID_EVENT的timestamp值。它是计算Seconds_behind_master的一个因素,因此MTS中Seconds_behind_master的计算和检查点息息相关。
bool mts_checkpoint_routine(Relay_log_info *rli, bool force) {
...
/*
Update the rli->last_master_timestamp for reporting correct
Seconds_behind_master.
If GAQ is empty, set it to zero.
Else, update it with the timestamp of the first job of the Slave_job_queue
which was assigned in the Log_event::get_slave_worker() function.
*/
// 如果 GAQ 队列为空设置 ts 为 0
// rli->gaq->head_queue()) 检查点位置的事务结束时间
ts = rli->gaq->empty()
? 0
: reinterpret_cast<Slave_job_group *>(rli->gaq->head_queue())->ts;
// 传入出队事务数量及 ts 时间
rli->reset_notified_checkpoint(cnt, ts, true);
/* end-of "Coordinator::"commit_positions" */
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
【5】最后还会将前面GAQ出队的事务数量累加给每个worker线程,因为每个worker线程需要根据这个值来进行Bitmap位图的偏移;并且还会维护我们前面说的GAQ的checkpoint_seqno值,及更新last_master_timestamp。
这个操作也是在函数Relay_log_info::reset_notified_checkpoint中完成的,实际上很简单,部分代码如下:
void Relay_log_info::reset_notified_checkpoint(ulong shift, time_t new_ts,
bool update_timestamp) {
// 循环每个 worker
for (Slave_worker **it= workers.begin(); it != workers.end(); ++it)
{
// 通知更新 worker 中 checkpoint 信息
w->checkpoint_notified = false;
// 每个 worker 线程都会增加出队的事务个数
w->bitmap_shifed = w->bitmap_shifted + shift;
}
// 这里减去出队事务的个数
rli_checkpoint_seqno = rli_checkpoint_seqno - shift;
// 更新 last_master_timestamp 值为 xid_event header timestamp
// show slave status 时 Seconds_Behind_Master 的计算依赖 last_master_timestamp
if (update_timestamp) {
mysql_mutex_lock(&data_lock);
last_master_timestamp = new_ts;
mysql_mutex_unlock(&data_lock);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
到这里整个检查点基本操作就完成了。我们看到实际步骤并不多,拿到Bitmap偏移量后每个worker线程就会在随后的第一个事务提交的时候进行位图的偏移,checkpoint_seqno计数也会更新。
我们前面的假设环境中,如果触发了一次检查点,并且协调线程将后两个可以并行的事务发给了worker1和worker3进行处理,并且处理完成。那么我们的图会变成如下:
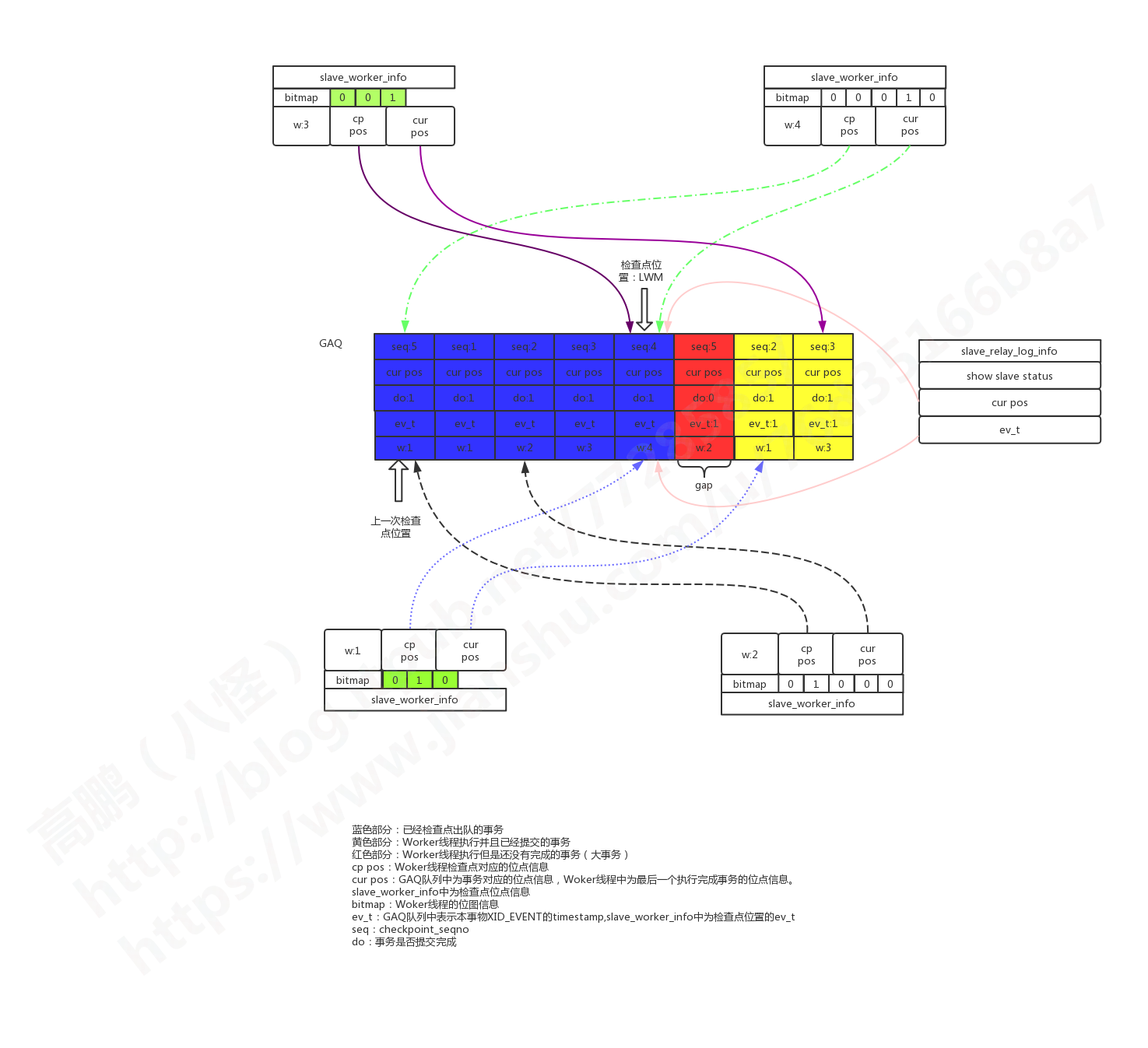
这种图中我用不同的样色表示了不同线条,因为它们交叉比较多。GAQ中的红色事务就是我们假设的大事务,它仍然没有执行完成,它也是我们所谓的gap。如果这个时候MySQL实例异常重启后,那么这个红色gap就是我们启动后需要找到的事务,方式就是通过Bitmap位图进行比对。如果是开启了 GTID,这种gap很容易就能观察到,后面会说。
同时我们需要注意这个时候worker2并没有分发新的事务执行,因为worker2没有执行完大事务,因此在slave_worker_info表中它的信息仍然显示为上一次提交事务的信息。而worker4因为没有分配到新的事务,因此slave_worker_info表中它的信息也显示为上一次提交事务的信息。因此在slave_worker_info中worker2和worker4的检查点信息、Bitmap信息、checkpoint_seqno都是老的信息。
# 淘宝月报版本
如下图所示,GAQ中第0、2、5号事务分发给了worker a,第0个已经执行完成,所以worker a的bitmap中,第0位置1;worker b和worker c的bitmap同理,标识已经执行的事务。
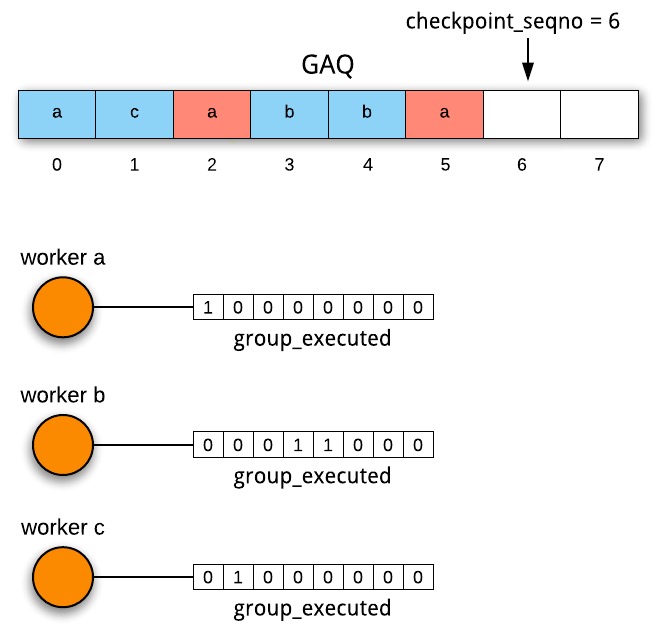
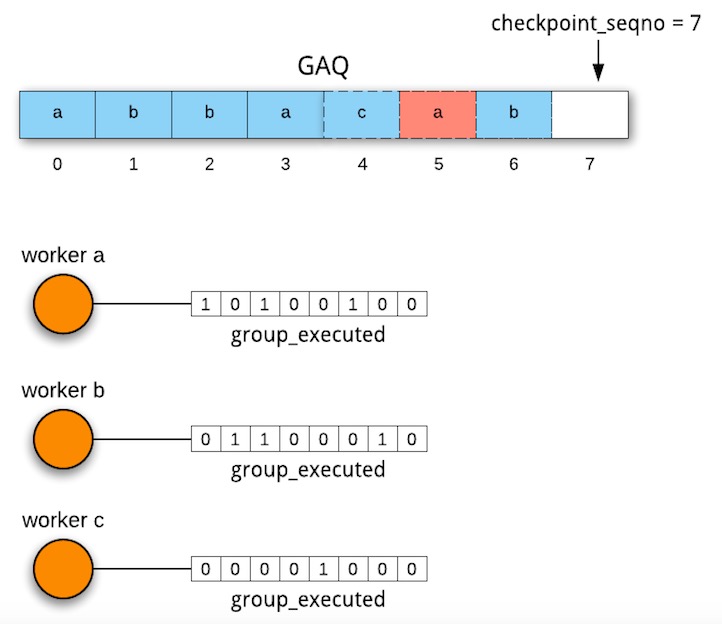
假设这个时候协调线程做了一次checkpoint,将队列头部2个已经完成的事务出队,然后将rli_checkpoint_seqno – 2,同时将2累加到每个worker->bitmap_shifted中,当协调线程将新的事务分给worker的时候,会将worker->bitmap_shifted取出,存在当前Slave_job_group.shifted中,当worker执行到这个group(就是事务),就开始对group_executed bitmap进行偏移,偏移量就是Slave_job_group.shitfed(再一次说明了GAQ中的Slave_job_group,充当了协调线程和worker线程通信的角色)。bitmap的变化就如下图所示,checkpoint后,原来的0和1出队,然后新的4、5、6加入进来,新分发给worker b和worker c的4和6已经执行完成,所以bitamp和上图相比,已经向左路偏移了2位,而新分发worker a的5并示执行,所以worker a的bitmap还未偏移。
# MTS 中 gap 测试
前面我们主要描述了MTS多线程并发回放的原理。提到了一种情况,如果不设置slave_preserve_commit_order参数为ON的情况下,可能出现gap。这种gap可能是由于在并行回放的事务中存在一个大事务没有执行完成,但其随后的事务已经由其他worker线程执行完成,意味着从库并行回放时候事务顺序发生变化,用户在从库端读取数据可能先读到后提交的事务(相对主库来说),这种场景就无法满足Causal Consistency(因果一致性)。如果设置了slave_preserve_commit_order将会防止这种gap现象的存在,也就可以在并行回放的同时保证了Causal Consistency。下面我们来测试这种gap,然后解释为什么slave_preserve_commit_order参数设置为ON可以防止这种现象。
要测试gap需要使用gtid auto_position模式,通过观察gtid set来发现。
首先可以人为的调大参数binlog_group_commit_sync_delay=1000000,也就是1秒,这样设置可能会导致简单的DML都需要1秒的时间。我们可以使用如下方式:
| 大事务 | 小事务 |
|---|---|
| begin | |
| begin | |
| 执行大事务 | |
| 执行小事务 | |
| commit | |
| commit |
注意这两个commit发起间隔不能超过1秒,因此我们可以在两个窗口先打好commit命令,然后直接回车,同时这两个事务修改的记录是不能冲突的。
现在我使用上面的方法得到了2个可以并发执行的事务,如下,第一个是大事务,第二个是小事务。
#150520 14:23:11 server id 88 end_log_pos 259 CRC32 0x4ead9ad6 GTID last_committed=2 sequence_number=3
'185179df-c5a1-11e9-ac93-7cd30adaa26c:187' /*!*/;
#150520 14:23:11 server id 88 end_log_pos 1483 CRC32 0xdf94bc85 GTID last_committed=2 sequence_number=4
'185179df-c5a1-11e9-ac93-7cd30adaa26c:188' /*!*/;
2
3
4
从库我们可以观察到下面的现象:
Retrieved_Gtid_Set: 185179df-c5a1-11e9-ac93-7cd30adaa26c:1-188
Executed_Gtid_Set: 185179df-c5a1-11e9-ac93-7cd30adaa26c:1-186:188
2
这里我们可以发现Executed_Gtid_Set中缺少了gno为187的这个事务,因为这个事务正在执行,但是188这个事务已经由其他worker线程执行完成了,因此出现这种gap。如果这个时候从库MySQL异常重启了,这个gap是需要填补起来的,具体怎么填补后面再说。
# 参数 slave_preserve_commit_order 的影响
首先我们应该知道,如果要开启参数slave_preserve_commit_order,从库必须开启记录event功能,也就是log_bin 和 log_slave_updates参数都需要设置。
因为slave_preserve_commit_order参数的主要实现还是集中在MYSQL_BIN_LOG::ordered_commit函数中,如果不记录event的话根本就不会进入这个函数。还有一个参数binlog_order_commits,这个参数主要用于保证InnoDB层提交顺序和MySQL层提交一致,并且这个参数默认是开启的。既然能保证顺序那么为什么还会出现gap呢?还需要参数slave_preserve_commit_order呢?
实际上这两个参数用处完全不一样:
【1】binlog_order_commits:默认是打开的,主要用于保证InnoDB层提交顺序和MySQL层提交顺序一致,这样事务的可见顺序也就和MySQL层提交顺序一致了。它在order commit的commit阶段前生效,开启后按照commit队列顺序在InnoDB层提交事务,否则commit队列中的每个事务就各自进行InnoDB层提交(不按照binary log中事务的的顺序)。
【2】slave_preserve_commit_order:虽然协调线程的分发是按照主库事务执行的顺序进行分发,但是每个worker线程执行完这个事务进行提交的时间却是不一定的。这里的顺序就是为了保证每个worker线程的事务提交顺序和主库事务执行的顺序一致。它在order commit的flush阶段前就生效。worker线程的事务在等待获取自己提交权限期间会堵塞在状态Waiting for preceding transaction to commit下,如果并行执行的事务中有一个大事务,很容易出现这种情况,因为大事务迟迟不能提交,导致其他worker线程就会一直等待获取自己的提交权限。
要实现这个功能,我们只需要保证worker线程进行事务提交的顺序和协调线程的分发顺序一致就可以了,因为协调线程是顺序读取的relay log,然后分发给worker线程的。那么下面我们来看看slave_preserve_commit_order参数具体的实现方法。
实现slave_preserve_commit_order的关键是添加了Commit_order_manager类,开启该参数会在获取worker时候向Commit_order_manager注册事务。
Slave_worker *Mts_submode_logical_clock::get_least_occupied_worker(Relay_log_info *rli,
Slave_worker_array *ws,
Log_event * ev)
{
...
if (rli->get_commit_order_manager() != NULL && worker != NULL)
rli->get_commit_order_manager()->register_trx(worker);
...
}
void Commit_order_manager::register_trx(Slave_worker *worker)
{
...
queue_push(worker->id);
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
协调线程在完成事务的分发后将事务注册到一个队列中,元素就是worker线程的ID。参考函数Commit_order_manager::register_trx。
如前所述,worker线程在提交事务进入order commit的时候,在事务进入FLUSH_STAGE前,会等待前面的事务都进入FLUSH_STAGE。直到队列中的首个元素的 worker线程ID和本worker线程ID相同则说明自己的提交时机到来了,事务开始进入FLUSH_STAGE。整个过程的等待会处于状态 Waiting for preceding transaction to commit中。参数函数Commit_order_manager::wait_for_its_turn。
当本事务进入FLUSH_STAGE后,那么就可以从队列中去掉这个worker线程的ID了,唤醒下一个事务。参数函数Commit_order_manager::unregister_trx。
在保证事务binlog flush的顺序后,通过binlog_order_commit参数即可获取同样的提交顺序,也就不存在Causal Consistency(因果一致性),即在备库获得和主库完全一致的执行顺序。
可以看到这个实现过程其实还是比较简单的,但是其主要实现位于MYSQL_BIN_LOG::ordered_commit函数下,因此必须要记录event到binary log才行。这也是最大的限制,开启记录event到binary log就涉及到影响从库性能,和我们开启MTS想提搞从库性能的初衷相违背。
但是经过测试,这个参数在
MySQL 5.7.18中设置之后,也无法保证从库上事务提交的顺序与relay log一致。 在·MySQL 5.7.19·设置后,从库上事务的提交顺序与relay log中一致(所以生产要想使用MTS特性,版本大于等于MySQL 5.7.19才是安全的)。
# 五、MySQL 5.7 并行复制测试
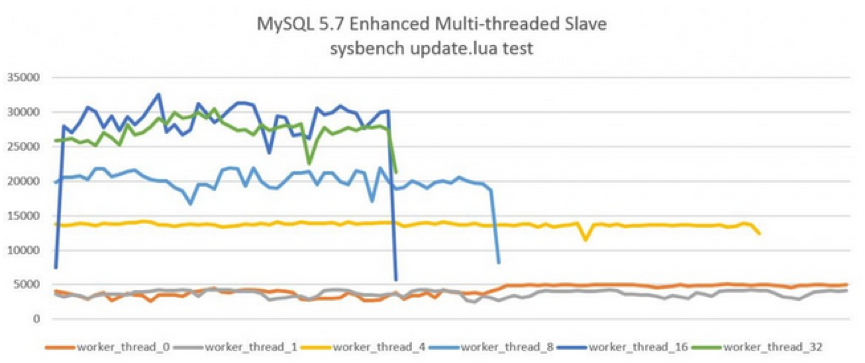
下图显示了开启MTS后,Slave服务器的QPS。测试的工具是sysbench的单表全update测试,测试结果显示在16个线程下的性能最好,从机的QPS可以达到25000以上,进一步增加并行执行的线程至32并没有带来更高的提升。而原单线程回放的QPS仅在4000左右,可见MySQL 5.7MTS 带来的性能提升,而由于测试的是单表,所以MySQL 5.6的MTS机制则完全无能为力了。
# 六、mts 实践
说了这么多,要开启enhanced multi-threaded slave其实很简单,只需根据如下设置:
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=16
slave_pending_jobs_size_max = 2147483648
slave_preserve_commit_order=1
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
2
3
4
5
6
7
8
在使用了MTS后,复制的监控依旧可以通过SHOW SLAVE STATUS\G,但是MySQL 5.7在performance_schema架构下多了以下这些元数据表,用户可以更细力度的进行监控:
mysql> show tables like 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
通过replication_applier_status_by_worker可以看到worker进程的工作情况:
mysql> select * from replication_applier_status_by_worker;
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
| CHANNEL_NAME | WORKER_ID | THREAD_ID | SERVICE_STATE | LAST_SEEN_TRANSACTION | LAST_ERROR_NUMBER | LAST_ERROR_MESSAGE | LAST_ERROR_TIMESTAMP |
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
| | 1 | 32 | ON | 0d8513d8-00a4-11e6-a510-f4ce46861268:96604 | 0 | | 0000-00-00 00:00:00 |
| | 2 | 33 | ON | 0d8513d8-00a4-11e6-a510-f4ce46861268:97760 | 0 | | 0000-00-00 00:00:00 |
+--------------+-----------+-----------+---------------+--------------------------------------------+-------------------+--------------------+----------------------+
2 rows in set (0.00 sec)
2
3
4
5
6
7
8
那么怎样知道从机MTS的并行程度又是一个难度不小。简单的一种方法(姜总给出的),可以使用performance_schema库来观察,比如下面这条SQL可以统计每个Worker Thread执行的事务数量,在此基础上再做一个聚合分析就可得出每个MTS的并行度:
SELECT
thread_id,
count_star
FROM
performance_schema.events_transactions_summary_by_thread_by_event_name
WHERE
thread_id IN (
SELECT
thread_id
FROM
performance_schema.replication_applier_status_by_worker
);
2
3
4
5
6
7
8
9
10
11
12
如果线程并行度太高,不够平均,其实并行效果并不会好,可以试着优化。这种场景下,可以通过调整主服务器上的参数binlog_group_commit_sync_delay、binlog_group_commit_sync_no_delay_count。前者表示延迟多少时间提交事务,后者表示组提交事务凑齐多少个事务再一起提交。总体来说,都是为了增加主服务器组提交的事务比例,从而增大从机MTS的并行度。
虽然MySQL 5.7推出的Enhanced Multi-Threaded Slave在一定程度上解决了困扰MySQ L长达数十年的复制延迟问题。然而,目前MTS机制基于组提交实现,简单来说在主上是怎样并行执行的,从服务器上就怎么回放。这里存在一个可能,即若主服务器的并行度不够,则从机的并行机制效果就会大打折扣。MySQL 8.0最新的基于writeset的MTS才是最终的解决之道。即两个事务,只要更新的记录没有重叠overlap,则在从机上就可并行执行,无需在一个组,即使主服务器单线程执行,从服务器依然可以并行回放。相信这是最完美的解决之道,MTS的最终形态。
最后,如果MySQL 5.7要使用MTS功能,必须使用最新版本,最少升级到5.7.19版本,修复了很多Bug。比如这个Bug。
# stop slave
类似单线程复制,stop slave命令会终止sql线程和worker线程的运行。
sql线程收到退出信号后,会先调用slave_stop_workers函数终止worker线程,过程如下:
【1】依次把每个运行中的worker的runnig_status设置Slave_worker::STOP,同时设置worker执行终止位置rli->max_updated_index;
【2】sql线程等待所有worker线程终止w->running_status == Slave_worker::NOT_RUNNING;
【3】调用mts_checkpoint_routine函数,做一次checkpoint;
【4】释放资源,如GAQ、curr_group_da等。
SQL线程在pop_jobs_item函数中会调用set_max_updated_index_on_stop函数,会检查2个条件:
【1】worker job队列是空的;
【2】当前worker执行的事务在GAQ中的位置,是否已经超过rli->max_updated_index;
任一条件满足就设置状态running_status为Slave_worker::STOP_ACCEPTED,表示开始退出。
从上面的逻辑可以看出,在收到stop信号后,worker线程会等正在执行的事务完成后,才会退出,是安全的。
# 异常退出
worker线程被kill或者执行出错
【1】slave_worker_exec_job进入错误处理逻辑,调用Slave_worker::slave_worker_ends_group函数,给sql线程发KILL_QUERY信号,然后做相关变量的清理,把job队列的任务全部清理掉,最终把running_status置为Slave_worker::NOT_RUNNING,表示结束;
【2】sql线程收到kill信号后,停止分发,然后进入slave_stop_workers逻辑,给活跃的worker线程发送STOP信号;
【3】其它worker线程收到STOP信号后,会处理job队列中所有的event;
【4】和stop slave不同的是,sql线程最后不会做checkpoint。
sql线程被kill: sql线程被kill的处理逻辑和stop slave差不多,不同之处在于等worker全部终止后,不会做checkpoint。
# 非 GTID AUTO_POSITION 模式异常恢复
在非GTID AUTO_POSITION复制模式下,从库线程重启(正常关闭或者异常kill)后,需要根据sql线程和每个worker线程的记录信息来进行恢复,推进到一个一致状态后再开始并行。
恢复的主要逻辑是mts_recovery_groups这个函数。
在启动从库的时候,如果relay-log.info中存的Number_of_workers不为0,就说明之前是并行复制,然后调用mts_recovery_groups,进入恢复逻辑。如前所述,mts_recovery_groups的目的就是根据slave_worker_info和slave_relay_log_info中信息,把gap事务找出来。
首先会创建Number_of_workers个worker,依次把每个slave_worker_info的信息读出来,然后把worker执行位点信息和slave_relay_log_info中记录的位点信息(低水位)相比,如果比后者小,说明崩溃前已经被checkpoint出队,不可能造成空隙,直接跳过;如果比后者大,就把worker存入above_lwm_jobs 数组。above_lwm_jobs收集完成后,初始化bitmap rli->recovery_groups,用来汇总每个worker的bitmap。对above_lwm_jobs中的每个worker,设置一个计数器recovery_group_cnt,从低水位位点开始扫relay log,每扫完一个事务,recovery_group_cnt加1,直到扫到worker.info中记录的位点为止,之后把worker的bitmap汇总到rli->recovery_groups中,其间会统计一个最大的recovery_group_cnt,记入rli->mts_recovery_group_cnt,这个对应高水位。
bitmap汇总逻辑如下:
// sql/rpl_slave.cc
for (uint i= (w->checkpoint_seqno + 1) - recovery_group_cnt,
j= 0; i <= w->checkpoint_seqno; i++, j++)
{
if (bitmap_is_set(&w->group_executed, i))
{
DBUG_PRINT("mts", ("Setting bit %u.", j));
bitmap_fast_test_and_set(groups, j);
}
}
2
3
4
5
6
7
8
9
10
之后SQL线程就可以从低水位往高水位扫relay log,对于每个事务,如果rli->recovery_groups对应bit为1,说明崩溃前已经执行过,就跳过;反之,就对事务中的每个event调用do_apply_event函数执行。扫描到高水位后整个恢复逻辑结束,后面SQL线程就进入正常的执行逻辑,执行(串行)或者分发(并行)event。
文章转载:http://www.ywnds.com/?p=3894 (opens new window)