随着公司业务发展和需求的不断迭代,系统内会累计越来越多过期无用的历史数据,这些数据主要包括两部分,第一部分是由于系统技术改造和需求迭代中动态规则所产生的配置项,第二部分是业务处理流程中产生的持久化过程记录数据。 随着时间的增加,这些过期的过程数据和配置不但会占用过多的磁盘空间,拖慢数据库查询速度,还会增加系统逻辑的复杂度,所以我们需要定期对这些数据做清理,但是如果清理过程中出现问题,则非常有可能影响系统的正常运行,甚至丢失订单数据,造成无法挽回的损失。
# 一、数据库记录清理
# 前期准备
【1】对于生产表,联系DBA拉取符合数据清理条件的表,主要包含三个条件:
● 容量超过限制,占用过多空间,一般认为超过 50GB 都算大表
● 记录条数过多,影响性能,例如条数 > 2 亿
● 存在常规查询语句由于数据量增大而变慢的情况
【2】新建表时,评估表的预期数据总量。在每次新建一张表时,都应该根据每日新增数据和业务需要的记录保存期限来评估表的预期数据总量。如果预期的记录数过大,可以考虑以下方案:
● 如果只在某个范围内有效的数据,可以考虑实现数据自动清理的计划任务(JOB),定时批量清理过期数据
● 如果数据长期有效,则需要考虑对表或者数据库做拆分,做分库分表
【3】逐表评估过期条件 此步骤尤为重要,评估不到位可能导致有效的生产数据被清理引发生产问题!
● 基于DBTrace拉取最近该表的所有访问方
● 与使用方和产品一起仔细确认数据应用范围,条件主要基于两个维度:状态和日期 例如:机票的有效期为 1 年,则超过一年的票号变化数据则为无效数据 或:机票出票的队列,在出票成功后则为冗余的无效数据
● 评估过期条件时最好还需要参考数据库的备份周期,避免新鲜有效且未备份的数据被误删除引发严重的生产问题。
【4】评估删除策略数据表记录清理通常不是一次就能完成的事情,表每日还在新增大量数据,历史积压的数据过多导致查询性能变慢,删除数据会影响生产对该表的读写性能,都是我们需要考虑的问题。所以我们需要基于积压量和单日新增量评估出一个周期性执行的清理任务。 计算单日清理量主要的策略如下:
■ 如历史积压量和新增量都比较低,则计算清理量时可以先设置一个历史数据的目标期限,每日计划清理的量为:每日平均新增量 +(历史数据量 / 期限天数)
■ 如历史积压量非常高,但新增量处于正常或较低水平,则应该先联系DBA和OPS做一次初始化清理,之后再按照平均的每日新增量留少许余量作为单日清理量。
■ 如果单日新增量非常高,到了无法平缓清理的地步,则应该评估数据最大可积压记录数的范围,每到达最大积压数时联系OPS手动大规模清理。并后续调研和改造降低该表的写入量。
由于数据库的delete操作是有锁的,如果单次删除的数据量非常大的话,会block住正常读写操作,或是造成事务堆积,影响到生产业务,所以计算出单日预计删除量后,还需要根据表的特性进行分割,将清理量均匀的,有间隔的分摊到单次清理周期中,以达到平缓的效果。
■ 每日计划建议划分为轮和次,每间隔 X 分钟执行一轮,每轮执行 Y 次批量delete操作,每次delete操作间隔 Z 毫秒。通过合理调节 X,Y, Z 的值,使其对生产的性能影响降到最低。
■ 如果表的单条记录较大,则需要适量减少单条delete语句删除的记录数
■ 如果表的预计删除数量较多,则可增加每轮多条delete语句删除的次数
# 执行事项
【1】delete的语句在部署到生产前,必须经过DBA的review,还需要在测试环境造数据进行严格的条件验证,尤其是条件中需要join其他表的。
【2】部署在生产后需要密切监控DB和相关表的性能,如果发现对生产性能指标造成了影响,需要及时终止清理计划。
【3】清理的时间点应该避开生产高峰期,凌晨 0 ~ 6 点为最佳区间。
【4】最好在 hickwall 中部署数据清理相关埋点的图表,例如查询语句耗时,delete 语句耗时,无可清理数据,总删除量等等信息,并根据这些数据动态的调整清理的配置,使得整个清理过程对生产影响尽可能低。
# 灾备方案
对于一些丢失代价非常高的核心数据,即时经过充分的测试和评估,也不能完全杜绝出错的可能性,所以这时候需要做好灾备的方案。
【1】对于提事件由DBA协助清理的数据,清理时需要勾选备份数据并选定保留天数。
【2】对于JOB程序自动清理的方式,可以使用MongoDB等灵活部署的数据库作为所有待删除数据的回收站。推荐Mongo是因为他新建表和定义表结构非常方便,而且可以直接部署在docker上,成本较低。
■ 程序中需要先select出符合删除范围的整条记录,而不仅仅是主键。
■ 维持表字段不变,将上述记录列表插入MongoDB的同名Collection中,如果Collection不存在,Mongo会自动创建。
■ 应用中可以直接按照表的维度做保留时间的配置项,插入时根据配置直接设置TTL,过期自动删除。
■ 保证插入成功后,再将原表对应的记录应用平滑策略删除。
■ 一旦由于条件配置错误等原因发生误删数据,可以直接从回收站中还原原始数据。
# 二、执行了delete,但表文件大小没减小
项目中使用Mysql作为数据库,对于表来说,一般为表结构和表数据。表结构占用空间都是比较小的,一般都是表数据占用的空间。
当我们使用delete删除数据时,确实删除了表中的数据记录,但查看表文件大小却没什么变化。
# Mysql数据结构
凡是使用过mysql,对B+树肯定是有所耳闻的,MySQL InnoDB中采用了B+树作为存储数据的结构,也就是常说的索引组织表,并且数据时按照页来存储的。因此在删除数据时,会有两种情况:
【1】删除数据页中的某些记录
【2】删除整个数据页的内容
为什么delete表数据,磁盘空间却还是被占用
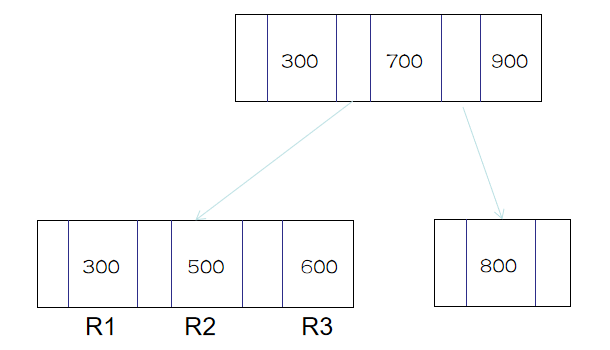
InnoDB直接将R2这条记录标记为删除,称为可复用的位置。如果之后要插入ID在 300到700间的记录时,就会复用该位置。由此可见,磁盘文件的大小并不会减少。
通用删除整页数据也将记录标记删除,数据就复用用该位置,与删除默写记录不同的是,删除整页记录,当后来插入的数据不在原来的范围时,都可以复用位置,而如果只是删除默写记录,是需要插入数据符合删除记录位置的时候才能复用。
因此,无论是数据行的删除还是数据页的删除,都是将其标记为删除的状态,用于复用,所以文件并不会减小。
# 那怎么才能让表大小变小
DELETE只是将数据标识位删除,并没有整理数据文件,当插入新数据后,会再次使用这些被置为删除标识的记录空间,可以使用OPTIMIZE TABLE来回收未使用的空间,并整理数据文件的碎片。
OPTIMIZE TABLE 表名;
WARNING
注意:OPTIMIZE TABLE只对MyISAM, BDB和InnoDB表起作用。
另外,也可以执行通过ALTER TABLE重建表
ALTER TABLE 表名 ENGINE=INNODB
有人会问OPTIMIZE TABLE和ALTER TABLE有什么区别?
alter table t engine = InnoDB(也就是recreate),而optimize table t等于recreate+analyze
# 表文件大小未更改和mysql设计有关
比如想要删除R2这条记录:
ALGORITHM选项
INPLACE: 替换:直接在原表上面执行DDL的操作。
COPY: 复制:使用一种临时表的方式,克隆出一个临时表,在临时表上执行DDL,然后再把数据导入到临时表中,在重命名等。这期间需要多出一倍的磁盘空间来支撑这样的 操作。执行期间,表不允许DML的操作。
DEFAULT: 默认方式,有MySQL自己选择,优先使用INPLACE的方式。
LOCK选项
SHARE: 共享锁,执行DDL的表可以读,但是不可以写。
NONE: 没有任何限制,执行DDL的表可读可写。
EXCLUSIVE: 排它锁,执行DDL的表不可以读,也不可以写。
DEFAULT: 默认值,也就是在DDL语句中不指定LOCK子句的时候使用的默认值。如果指定LOCK的值为DEFAULT,那就是交给MySQL子句去觉得锁还是不锁表。不建议使用,如果你确定你的DDL语句不会锁表,你可以不指定lock或者指定它的值为default,否则建议指定它的锁类型。
执行DDL操作时,ALGORITHM选项可以不指定,这时候MySQL按照INSTANT、INPLACE、COPY的顺序自动选择合适的模式。也可以指定ALGORITHM=DEFAULT,也是同样的效果。如果指定了ALGORITHM选项,但不支持的话,会直接报错。
OPTIMIZE TABLE和ALTER TABLE 表名 ENGINE=INNODB都支持Oline DDL,但依旧建议在业务访问量低的时候使用
# Online DDL
最后,再说一下Online DDL,dba的日常工作肯定有一项是ddl变更,ddl变更会锁表,这个可以说是dba心中永远的痛,特别是执行ddl变更,导致库上大量线程处于Waiting for meta data lock状态的时候。因此在5.6版本后引入了Online DDL。
Online DDL推出以前,执行ddl主要有两种方式copy方式和inplace方式,inplace方式又称为fast index creation。相对于copy方式,inplace方式不拷贝数据,因此较快。但是这种方式仅支持添加、删除索引两种方式,而且与copy方式一样需要全程锁表,实用性不是很强。Online方式与前两种方式相比,不仅可以读,还可以支持写操作。
执行online DDL语句的时候,使用ALGORITHM和LOCK关键字,这两个关键字在我们的DDL语句的最后面,用逗号隔开即可。示例如下:
ALTER TABLE tbl_name ADD COLUMN col_name col_type, ALGORITHM=INPLACE, LOCK=NONE;
# 三、配置数据清理
# 前期准备
过期的配置数据主要有两个来源,一是下线/到期的业务规则,二是系统技改迭代中产生的控制开关,包括硬开关和灰度控制。获取到需要清理的配置项后,需要做以下操作
■ 梳理该配置涉及到的业务逻辑与系统流程
■ 与业务方,产品,对应开发仔细确认下线该配置涉及到的业务影响
■ 代码中全局搜索该配置名称,找出所有引用以及关联的逻辑,并在技术层面上再次确认影响范围。(idea intelj 可通过 ctrl+shift+F 并选择 scope 做包括依赖包的全局搜索)
# 执行过程
【1】删除该配置关联到的所有代码,善用全局搜索。
【2】测试环境中新代码做黑白对照,生产配置的跑一次所有case,配置源删除对应项后再跑一次所有case,看两者结果是否完全相同。
【3】代码发布前,想好如何拉取受影响的订单,可以通过DB取数,也可以通过log埋点。
【4】代码分集群灰度发布,密切监控相关订单是否符合预期。
【5】代码发布完成,监控一小时以上无异常后,可以将配置源中配置项或是对应数据删除。
【6】过程中一旦出现问题,需要及时回退配置项,再回滚代码到上个版本,并拉取受影响的项目进行手工补偿,避免影响客人出行或系统稳定性。
# 四、数据变更
原则上,不建议开发在高峰期修改生产配置。因为需要审批邮件。测试环境验证通过。生产灰度配置开关。(如不能灰度需说明原因)观察各项指标是否正常,至少 15 分钟。全量切换配置开关。观察各项指标是否正常,至少 20 分钟。
# 空值处理原则
【1】空值的出现可能和当前的业务逻辑并无关系,但是如果处理不当会抛出空指针异常,严重的可能会导致业务系统发生灾难性故障;
【2】根据业务需要,代码中要严格校验数据的空或无结果值,可以将空值替换为特定的值或者直接过滤掉;
【3】主要处理原则有以下几点 空集合返回值, 使用 Optional 变量 ,jsr 303,jsr 305 这几种方式,可以让我们的代码可读性更强,出错率更低!
■ 空集合返回值 :如果有集合这样返回值时,除非真的有说服自己的理由,否则,一定要返回空集合,而不是 null
// 常规处理方式
public List<User> listUser(){
List<User> userList = userListRepostity.selectByExample(new UserExample());
if(CollectionUtils.isEmpty(userList)){//spring util工具类
return null;
}
return userList;
}
// 优雅处理方式
public List<User> listUser(){
List<User> userList = userListRepostity.selectByExample(new UserExample());
if(CollectionUtils.isEmpty(userList)){
return Lists.newArrayList();//guava类库提供的方式
}
return userList;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
■ Optional: 如果你的代码是 jdk8,就引入它!如果不是,则使用 Guava 的 Optional,或者升级 jdk 版本!它很大程度的能增加了接口的可读性!
// 常规处理方式
public interface UserSearchService{
List<User> listUser();
User get(Integer id);
}
// 优雅处理方式
public interface UserSearchService{
/**
* 根据用户id获取用户信息
* @param id 用户id
* @return 用户实体
* @exception UserNotFoundException
*/
User get(Integer id);
}
// 更优雅处理方式
public interface UserSearchService{
/**
* 根据用户id获取用户信息
* @param id 用户id
* @return 用户实体,此实体有可能是缺省值
*/
Optional<User> getOptional(Integer id);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
■ jsr 303: 如果新的项目正在开发,不防加上这个试试!一定有一种特别爽的感觉!
public interface UserSearchService{
/**
* 根据用户id获取用户信息
* @param id 用户id
* @return 用户实体
* @exception UserNotFoundException
*/
User get(@NotNull Integer id);
/**
* 根据用户id获取用户信息
* @param id 用户id
* @return 用户实体,此实体有可能是缺省值
*/
Optional<User> getOptional(@NotNull Integer id);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
■ jsr 305: 如果老的项目在你的手上,你可以尝试的加上这种文档型注解,有助于你后期的重构,或者新功能增加了,对于老接口的理解!
public interface UserSearchService{
/**
* 根据用户id获取用户信息
* @param id 用户id
* @return 用户实体
* @exception UserNotFoundException
*/
@CheckForNull
User get(@NonNull Integer id);
/**
* 根据用户id获取用户信息
* @param id 用户id
* @return 用户实体,此实体有可能是缺省值
*/
Optional<User> getOptional(@NonNull Integer id);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 数据变更 RCA 案例
某日生产数据同步清理目标库操作,导致引擎刷新缓存以后拿不到某数据,数据节点为空,依赖项目报空引用,block 住主流程,导致订单跌 0
经验教训
- 生产数据同步,需要放在非业务高峰期
- 对配置和数据库的修改,必须发邮件通知到相关人员,以及要列出监控点,风险点,和回滚策略
- 生产数据操作,严格按照流程,审批通过之后操作
- 关键业务逻辑要充分考虑空值带来的风险