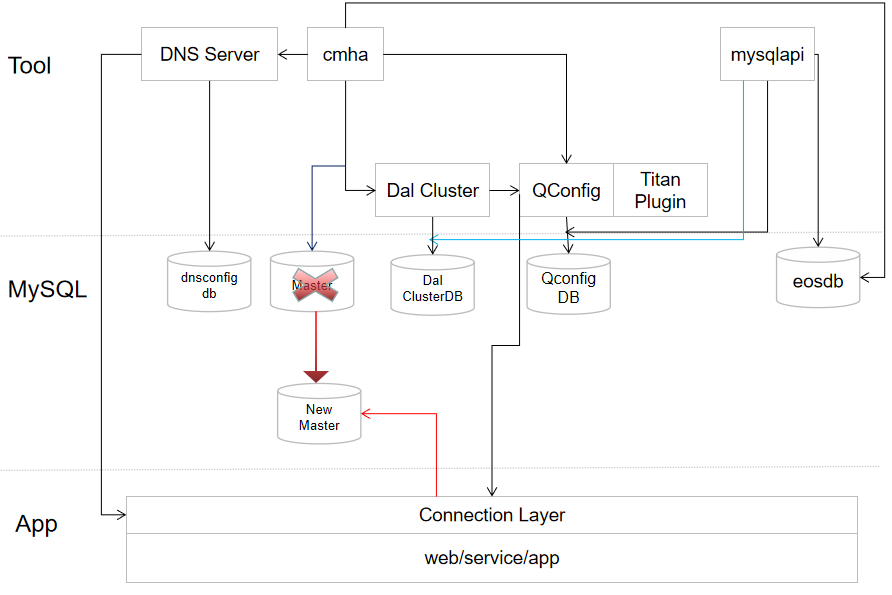
# 一、应用访问形式
MySQL高可用的前提就是当进行了Master和Slave的切换之后,需要让应用进行感知,否则即使切换完成了,应用也是无法访问的。所以首先要从架构上对访问的情况进行梳理。
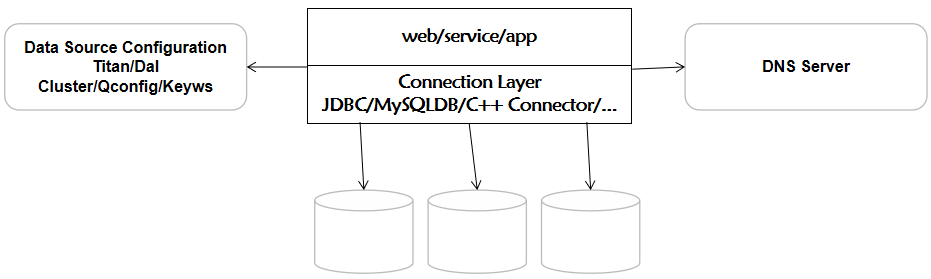
【1】通过Tian/Dal访问数据库,通过从QConfig配置文件中拿到具体的IP(动态数据源)配置去访问数据库。如果发生切换之后,切换信息会同步到QConfig然后对DAL信息进行重新的推送,然后就会应用就会感知到IP发生了变化。
【2】通过Data Source Configuration访问数据库,在python/C++的直连应用中比较多。这种场景可能会依赖DNS Server。如果发生了DNS切换,应用服务器需要刷新DNS缓存,刷新了DNS缓存之后,才能感知到DNS服务发生了变化,感知到变化之后应用才能去访问数据库。有两种情况:一种是对VIP的UP和DOWN这种VIP是不会变的,那么应用会立马感知到。另一种是进行DR切换,将DNS切换到了另一个机房,此时DNS底层的IP发生了变化,此时就依赖应用下面的DNS缓存来解决这个问题。DNS缓存刷新时间,就是你最终切换的时间。所以有时候Python直连应用感知变化的时间比Tian调的时间长。
# 二、复制架构
MySQL复制架构按照机房级别分为如下两种情况:
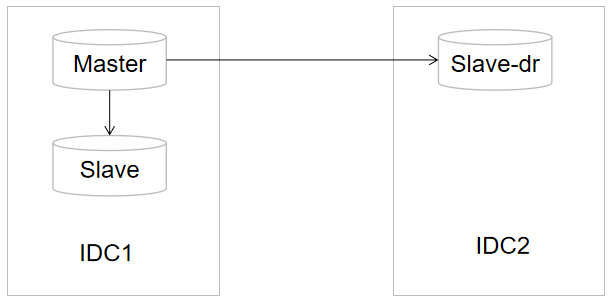
【1】在两个IDC部署MySQL服务器,其中IDC1部署Master-Slave,IDC2只部署一个Slave。假设IDC1挂掉之后,会切换到IDC2。如果只是Master关掉,会在IDC内进行一次切换,从而实现灾备的配置。而IDC1骨干节点一般是内网,理论IDC1中的Slave比IDC2中的Slave的内容更全更新(主要从物理距离考虑)。
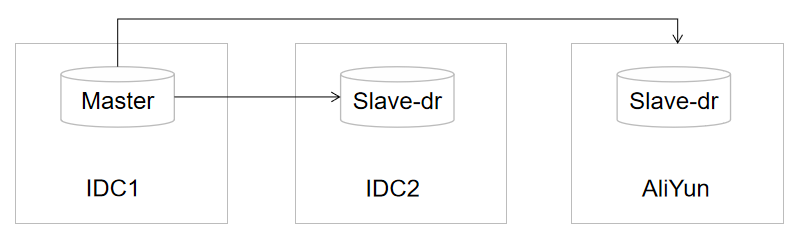
【2】我们有的DR节点是上了阿里云的,这种场景所有的切换都是DR切换,这种三机房的DR部署,优先切换到IDC2。因为是骨干网,延迟比较低。阿里云走的专线,延迟相对比较长。
# 三、半同步复制
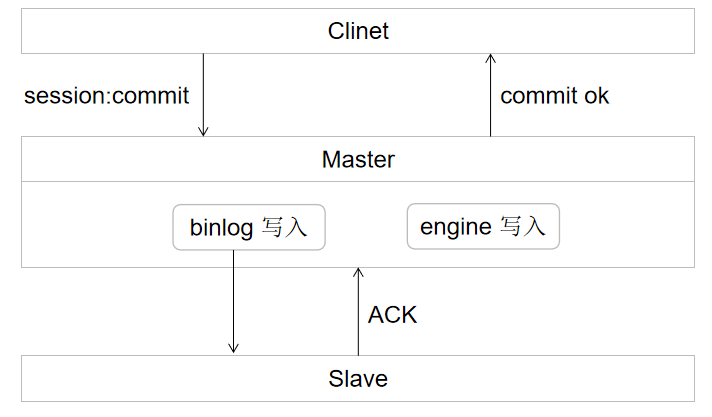
MySQL采用的复制方式都是半同步复制方式,半同步对数据的保护程度是最好的,在了解半同步复制之前,我们先看下MySQL的两阶段提交问题。
当客户端进行Commit的时候,首先会写入binlog,此时会将事务置为prepare状态,binlog写完之后回向Slave节点发送一个ACK请求。确定binlog是否传到了Slave并且Slave生成了relaylog<a href='http://localhost:8080/blogs/db/replay.html'target='_blank'>中继日志,生成之后Slave会向Master回馈ACK。此时Master才会向引擎层进行写入并向Client返回OK别的事务才会看到。半同步复制可以保证在超时的情况下,一定有一个Slave拥有最新的数据。还有一个优点,就是当在ACK的时候挂掉了,那么在Slave上拿到的中继日志一定是最新的,从而保证数据不丢失。从而保证我们在主从切换过程中,丢数据的概率大大降低。
# 四、CMHA
如下实际生产部署的高可用架构信息,我们的高可用是基于MHA架构完成的,MHA是一个日本工程师发明的设计工具。我们对MHA封装之后称为CMHA。CMHA有两个核心主键: MySQL Sentinel哨兵,基于Redis哨兵进行了修改。哨兵模式的机制是探活Master和Slave节点,同时还要探活Slave节点到Master节点可通,比较重要,假设应用发现Master连不上Slave可以连接上,但是Slave和Master是通的,所以需要去验证一下,因为有可能是哨兵的节点和Master节点不通而已。MHA不仅仅保证主从的切换,还会保证数据的一致性。首先,MHA会在MySQL Cluster中找到最新的later slave,然后从Master上将日志补录到此Slave中,最后才会发起切换。
MySQL Sentinel和MHA依赖上游的eosdb,eosdb是一个特殊的MHA架构,主要的作用是存储一些元数据,包括DB和dal层面的元数据。同时,MHA节点还依赖consul kv可以理解为zookeeper,拥有分布式选主的能力,还作为eosdb的缓存,主要作用就是防止发生大面积的切换eosdb有可能扛不住,所以通过consul kv作为缓存层,减少eosdb的压力。
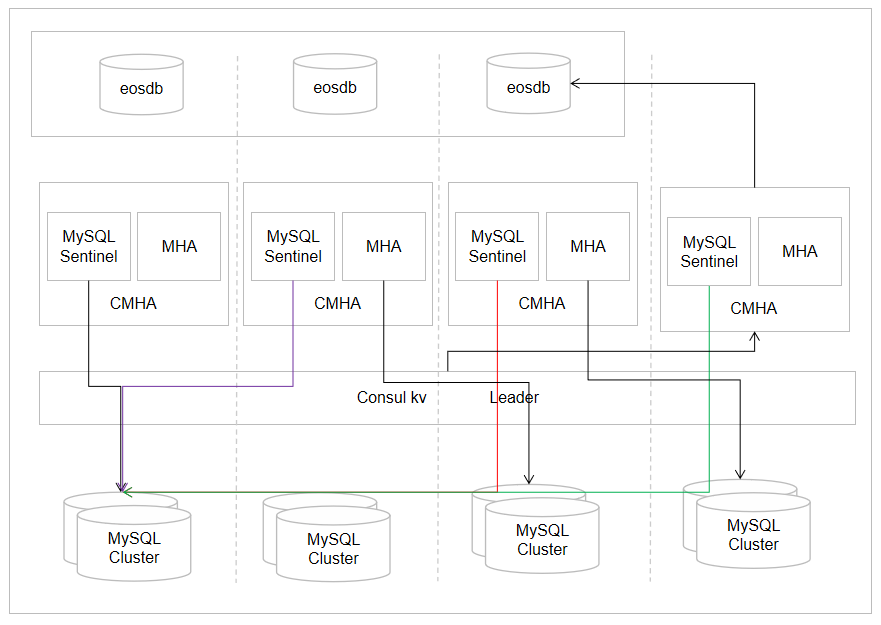
实际切换流程:CMHA发现Master挂掉后会发起一次主从切换,CMHA会通知三个主键:DNS Server是否需要切换IP、Dal Cluster是否需要切换IP、QConfig会拿到新的IP然后推送给应用,CMHA还会去更新eosdb中的数据。如果应用不是走QConfig配置,是通过Data Sorce、Configuration等,就可能会因为DNS Server什么时候切换完成,并在应用层将DNS Server缓存更新完之后,才会自动将DNS切换到New Master上,这个时候应用才会感知到,此时切换流程就完成了。
因为MySQL是一个有状态的服务,与应用层不同,应用层我们想切那个就切那个,Mysql会碰到一致性问题。有几种情况会存在数据不一致性问题:假设Master crash了,此时Master日志还在,通过将Master日志应用到New Master上,此时New Master的数据就是最新的。还有一种情况,假设Master节点不是crash的,而是有很多类似演练的这种大规模的网络切换,会存在一个问题,Master节点没有死透,还有应用节点在访问,CMHA做切换以后,New Master有新的应用连接进来,此时两边都在写,就会出现脑裂问题。此时,我们会对Old Master进行补刀,同时会对已经写入的Old Master上的binlog和New Master的binlog进行比较,通过业务来判断哪些数据是需要的哪些是不需要的,这个是当前架构解决不了的问题。