# 一、gh-ost的作用
gh-ost是由Github提供的Online DDL工具,使用binlog代替之前的触发器做异步增量数据同步,从而降低主库负载。
基于触发器的Online DDL工具原理:
【1】根据原表结构执行alter语句,新建一个更新表结构之后的表,称为幽灵表,对用户是透明的。
【2】将原表数据全量拷贝至幽灵表。
【3】将增量数据同步到幽灵表,也就是Online的核心。最开始办法是在源表上增加几个触发器,例如当源表执行INSERT,UPDATE,DELETE语句,就把这些操作通过触发器同步到幽灵表上,这样在幽灵表上执行的语句和源表的语句就属于同一个事务,显然这样会影响主库的性能。后面出现了异步的模式,使用触发器把对源表的操作保存到一个Changelog表中,不真正的去执行,专门有一个后台的线程从Changelog表读取数据应用到幽灵表上。这种方式一定程度上缓解了主库的压力,但是保存到Changelog表也同样是属于同一个事务中,对性能也有不小的影响。
【4】拷贝和同步完成之后,锁定源表并交换表名,幽灵表替换源表。
【5】删除源表,完成Online DDL。
触发器同步增量数据的缺点:
【1】Triggers, overhead: 触发器是用存储过程的实现的,就无法避免存储过程本身需要的开销。
【2】Triggers, locks: 增大了同一个事务的执行步骤,更多的锁争抢。
【3】Trigger based migration, no pause: 整个过程无法暂停,假如发现影响主库性能,停止Online DDL,那么下次就需要从头来过。
【4】Triggers, multiple migrations: 他们认为多个并行的操作是不安全的。
【5】Trigger based migration, no reliable production test: 无法在生产环境做测试。
【6】Trigger based migration, bound to server: 触发器和源操作还是在同一个事务空间。
gh-ost放弃了触发器,使用binlog来同步。gh-ost作为一个伪装的备库,可以从主库/备库上拉取binlog,过滤之后重新应用到幽灵表上。
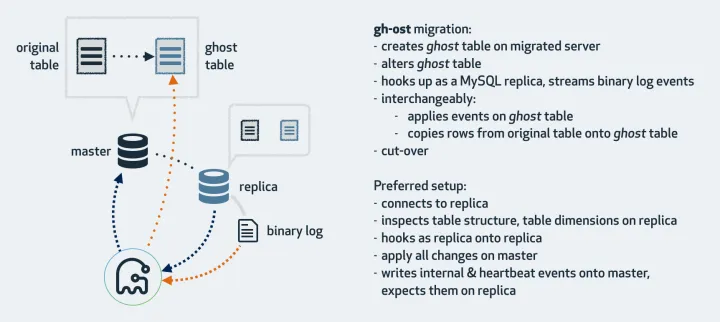
gh-ost首先连接到主库上,根据alter语句创建幽灵表,然后作为一个”备库“连接到其中一个真正的备库上,一边在主库上拷贝已有的数据到幽灵表,一边从备库上拉取增量数据的binlog,然后不断的把binlog应用回主库。图中cut-over是最后一步,锁住主库的源表,等待binlog应用完毕,然后替换gh-ost表为源表。gh-ost在执行中,会在原本的binlog event里面增加以下hint和心跳包,用来控制整个流程的进度,检测状态等。这种架构带来诸多好处,例如:
【1】整个流程异步执行,对于源表的增量数据操作没有额外的开销,高峰期变更业务对性能影响小。
【2】降低写压力,触发器操作都在一个事务内,gh-ost应用binlog是另外一个连接在做。
【3】可停止,binlog有位点记录,如果变更过程发现主库性能受影响,可以立刻停止拉binlog,停止应用binlog,稳定之后继续应用。
【4】可测试,gh-ost提供了测试功能,可以连接到一个备库上直接做Online DDL,在备库上观察变更结果是否正确,再对主库操作,心里更有底。
【5】并行操作,对于gh-ost来说就是多个对主库的连接。
# 二、云数据库场景
用户没有Super权限,因此使用过程中要加上–assume-rbr,gh-ost会认为binlog本身就是row模式,不会再去修改。阿里云RDS上的binlog默认也是row模式,所以不存在问题。binlog的三种模式
其它权限,主要是REPLICATION SLAVE,REPLICATION CLIENT可以拉取binlog,也可以获得。
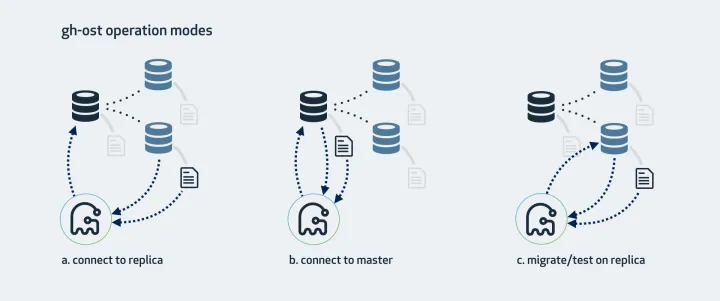
无法连接到备库拉取binlog。备库通常对用户来说是透明的,所以gh-ost需要直接连接到主库上去,这可能会增大对主库的负载。使用的时候需要增加–allow-on-master,–assume-master-host。官方推荐的方式也是连接到其中一个备库,因为会有一些压力较大的SELECT操作,放在备库是最好的。几种连接模式如下图所示: