# 一、简介
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数,既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。它可以告诉你某样东西一定不存在或者可能存在。相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。

添加数据: 当要向布隆过滤器中添加一个元素key时,我们通过多个hash函数,算出一个值,然后将这个值所在的方格置为1。比如,下图hash1(key)=1,那么在第2个格子将0变为1(数组是从0开始计数的),hash2(key)=7,那么将第8个格子置位1,依次类推。
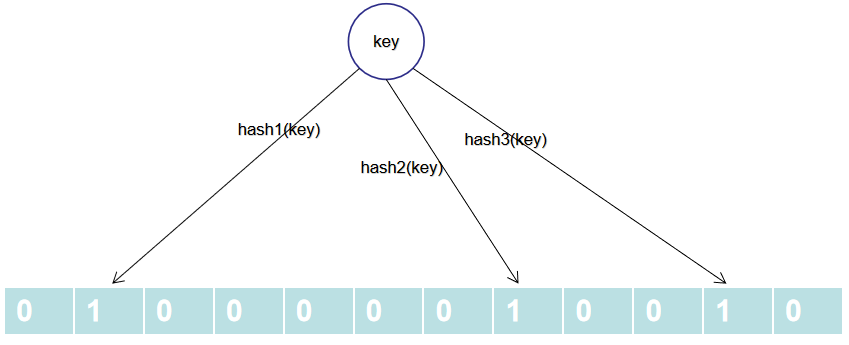
查询数据: 将key通过自定义的几个哈希函数分别算出各个值,然后看其对应下标是否都是1,如果存在0,该数据一定不存在于这个布隆过滤器中。如果通过哈希函数算出来的值,对应下标都是1,这个key可能存在布隆过滤器中。因为多个不同的key通过hash函数算出来的结果是会有重复的,所以会存在某个位置是别的key通过hash函数置为的1。这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个bit并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
# 二、优缺点
优点: 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数$O(K)$,另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点: 误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面。这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
# 三、减少布隆过滤器的误判
关于减少误判的产生,方法有两个:
【1】增加二进制位数。在原始情况下我们设置索引位到达了100,但是如果我们把它放大1万倍,到达了100万,是不是Hash以后的数据会变得更分散,出现重复的情况就会更小,这是第一种方式。
【2】增加Hash的次数。其实每一次Hash处理都是在增加数据的特征,特征越多,出现误判的概率就越小。
现在我们是做了三次Hash,那么如果你做十次,是不是它出现误判的概率就会小非常多?但是在这个过程中,代价便是CPU需要进行更多运算,这会让布隆过滤器的性能有所降低。
# 四、使用
Redis实现布隆过滤器的底层就是通过bitmap这种数据结构,在Java中提供了一个客户端工具Redisson组件,它内置了布隆过滤器,可以让程序员非常简单直接地去设置布隆过滤器。
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.x.x:6379");
config.useSingleServer().setPassword("xxx");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameBloom");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
// 第二个 0.01 则代表误判率最大允许为 1%,在我们以前的项目中通常也是设置为 1%。如果把这个数值设置太小,虽然会降低误判率,但会产生更多次的 Hash 操作,会降低系统的性能(正是刚刚讲过的),因此 1% 也是我所建议的数值。
bloomFilter.tryInit(100000000L,0.01);
//将号码10086插入到布隆过滤器中
bloomFilter.add("zzx");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("fj"));//false
System.out.println(bloomFilter.contains("zzx"));//true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
guava工具包
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),10000000,0.03);
bloomFilter.put("zzx");
System.out.println(bloomFilter.mightContain("fj")); //false
System.out.println(bloomFilter.mightContain("zzx")); //true
2
3
4
5