# 一、Reactor 概念/POM
"具有非阻塞负压功能的异步流处理系统" 的标准以及API。主要用来构建 JVM环境下的非阻塞应用程序。它直接和 JDK8中的 API相结合,比如:CompletableFuture,Stream和Duration等。它提供了两个非常有用的异步序列API:Flux和Mono,并且实现了Reactive Streams的标准。 我们知道WebFlux的底层使用的是 reactor-netty,而 reactor-netty又引用了Reactor。所以,如果你在POM中引入了 webFlux依赖:那么项目将会自动引入Reactor。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
2
3
4
如果你用的不是Spring webflux,没关系,你可以直接添加下面的依赖来使用Reactor: Reactor Core 运行在 Java 8 及以上版本,这里可以去 Maven中选择最新的 version,也可以通过 BOM进行统一的依赖管理。紧接着就是介绍。
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
2
3
4
【可选项】Reactor 3 使用了 BOM(Bill of Materials,一种标准的 Maven artifact),从而无需操心不同版本组件的互相依赖问题。Bom 是一系列有版本信息的 artifacts,通过 “列车发布”(release train)的发布方式管理,每趟列车由一个 “代号+修饰词”组成。引入 BOM如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>Bismuth-RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
2
3
4
5
6
7
8
9
10
11
RxJava 实现了JVM平台的Reactive。然后 Reactive Streams标准出现了,它定义了 Java平台必须满足的的一些规范。并且已经集成到 JDK9中的 java.util.concurrent类中。
在 Flow中定义了实现 Reactive Streams的四个非常重要的组件,分别是Publisher,Subscriber,Subscription和 Processor。
# 1、Reactive Streams 核心接口
Reactor 引入了实现 Publisher 的响应式类 Flux 和 Mono,以及丰富的操作方式。

# 2、Flux 与 Mono
【1】Flux 对象是一个包含0-N个元素组成的异步序列的Publisher<T>,可以被 onComplete 信号或者 onError 信号终止。在响应流规范中存在三种给下游消费者调用的方法 onNext,onComplete 和 onError 下图表示了 Flux 的抽象模型。
由于多种不同的信号可能性,Flux 可以作为一种通用的响应式类型。注意,所有的信号事件, 包括代表终止的信号事件都是可选的:如果没有 onNext 事件但是有一个 onComplete 事件, 那么发出的就是“空的”有限序列,但是去掉 onComplete 那么得到的就是一个 无限的 空序列。 当然,无限序列也可以不是空序列,比如,Flux.interval(Duration) 生成的是一个 Flux<Long>, 这就是一个无限地周期性发出规律 tick 的时钟序列。
Flux.interval(Duration.of(5, ChronoUnit.SECONDS)).subscribe(System.out::println);
//防止程序过早退出,放一个CountDownLatch拦住
CountDownLatch latch = new CountDownLatch(1);
latch.await();
// 输出: 0 1 2 ....
2
3
4
5

【2】Mono 对象是一个发出0-1个元素的Publisher<T>,可以被 onComplete 信号或者 onError 信号所终止。整体和 Flux一致,差别是 Mono只会发出 0-1个元素。
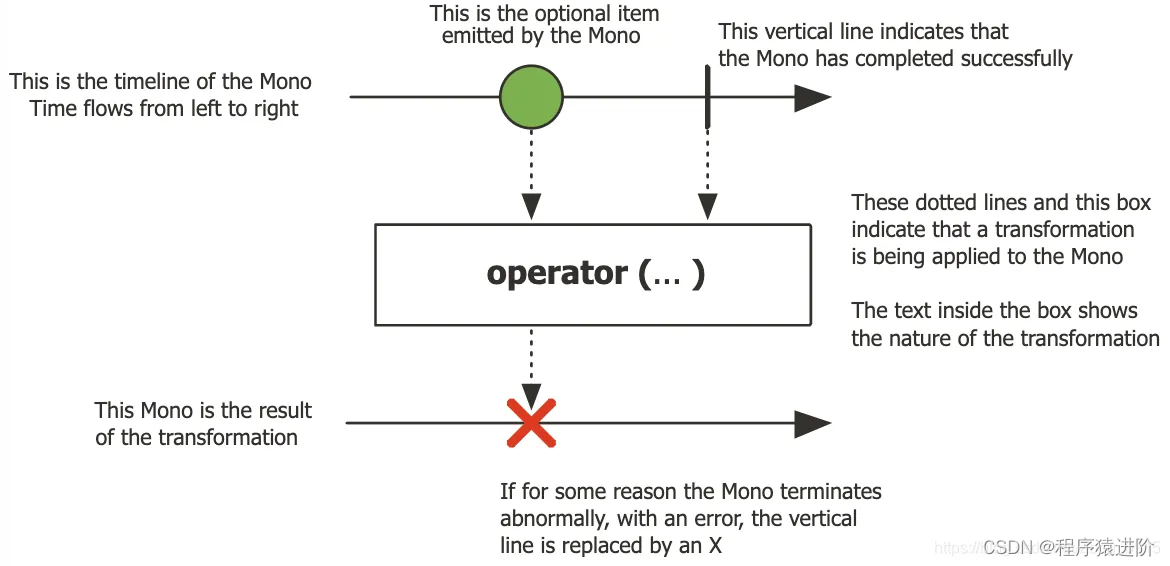
# 3、Reactor 操作符

创建: create, just, from, fromIterable, fromSupplier, fromFuture, empty, fromStream,error ……
转换与组合: map, flapMap, flapMapMany, concatMap, zip, zipWith, mergeWith, collectList, collectSet, collectMap ……
事件: doOnNext, doOnSubscribe, doOnError, doOnComplete ……
筛选与条件: filter, next, last, hasElement, hasElements, defaultIfEmpty, switchIfEmpty ……
错误处理: onErrorReturn, onErrorResume, onErrorContinue ……
重试与定时处理: retry, retryWhen, timeout , internal, defer, delay ……
并发与线程切换: parallel, subscribeOn, publishOn ……
日志: log ……
其他: cache …
【1】简单的创建和订阅 Flux 或 Mono 的方法:最简单的上手 Flux 和 Mono 的方式就是使用相应类提供的多种工厂方法之一。
// 如果要创建一个 String 的序列,你可以直接列举它们,或者将它们放到一个集合里然后用来创建 Flux,如下:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);
// 工厂方法的其他例子如下:
Mono<String> noData = Mono.empty(); //注意,即使没有值,工厂方法仍然采用通用的返回类型。
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3); //第一个参数是 range 的开始,第二个参数是要生成的元素个数。 5 6 7
2
3
4
5
6
7
8
9
10
11
12
在订阅(subscribe)的时候,Flux 和 Mono 使用 Java 8 lambda 表达式。 .subscribe() 方法有多种不同的方法签名,你可以传入各种不同的 lambda 形式的参数来定义回调。如下所示:基于 lambda 的对 Flux 的订阅(subscribe)
【2】订阅并触发序列: 下面的代码没有任何输出,但是它确实执行了。Flux 产生了3个值。如果我们传入一个 lambda, 我们就可以看到这几个值,参考【5】中的案例。
subscribe();
//示例:
Flux<Integer> ints = Flux.range(1, 3); //配置一个在订阅时会产生3个值的 Flux。
ints.subscribe();//最简单的订阅方式。
2
3
4
【3】对每一个生成的元素进行消费
subscribe(Consumer<? super T> consumer);
//示例:
Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe(i -> System.out.println(i)); //订阅它并打印值
//第二行代码会输入如下内容:
/**
1
2
3
**/
2
3
4
5
6
7
8
9
10
【4】对正常元素进行消费,也对错误进行响应
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer);
//示例:为了演示, 我们故意引入一个错误
Flux<Integer> ints = Flux.range(1, 4) //配置一个在订阅时会产生4个值的 Flux。
.map(i -> { //为了对元素进行处理,我们需要一个 map 操作。
if (i <= 3) return i; //对于多数元素,返回值本身。
throw new RuntimeException("Got to 4"); //对其中一个元素抛出错误。
});
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error: " + error));//订阅的时候定义如何进行错误处理。
// 现在我们有两个 lambda 表达式:一个是用来处理正常数据,一个用来处理错误。 刚才的代码输出如下:
/**
1
2
3
Error: java.lang.RuntimeException: Got to 4
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
【5】对正常元素和错误均有响应,还定义了序列正常完成后的回调
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer);
//示例:错误和完成信号都是终止信号,并且二者只会出现其中之一。为了能够最终全部正常完成,你必须处理错误信号。
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");});//订阅时定义错误和完成信号的处理。
//用于处理完成信号的 lambda 是一对空的括号,因为它实际上匹配的是 Runnalbe 接口中的 run 方法, 不接受参数。刚才的代码输出如下:
/**
1
2
3
4
Done
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
【6】对正常元素、错误和完成信号均有响应, 同时也定义了对该 subscribe 方法返回的 Subscription 执行的回调。
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer);
//示例:
SampleSubscriber<Integer> ss = new SampleSubscriber<Integer>();
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");},
s -> ss.request(10));
//响应式流规范定义了另一个 subscribe 方法的签名,它只接收一个自定义的 Subscriber, 没有其他的参数
// 方法签名:subscribe(Subscriber<? super T> subscriber);
ints.subscribe(ss); // 如果没有这行代码的话,上面是没有输出的。这里我就比较奇怪,如果去掉上面代码,也是相同的输出。不知道上面代码存在的意义。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
上面这个例子中,我们把一个自定义的 Subscriber 作为 subscribe 方法的最后一个参数。 下边的例子是这个自定义的 Subscriber,这是一个对 Subscriber 的最简单实现:它提供了很好的配置“背压” 的方法 request(n)。
package io.projectreactor.samples;
import org.reactivestreams.Subscription;
import reactor.core.publisher.BaseSubscriber;
public class SampleSubscriber<T> extends BaseSubscriber<T> {
public void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed");
request(1);//request(n) 就是这样一个方法。它能够在任何 hook 中,通过 subscription 向上游传递 背压请求。这里我们在开始这个流的时候请求1个元素值。
}
public void hookOnNext(T value) {
System.out.println(value + "1");
request(1);//随着接收到新的值,我们继续以每次请求一个元素的节奏从源头请求值。
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SampleSubscriber 类继承自 BaseSubscriber,在 Reactor 中, 推荐用户扩展它来实现自定义的 Subscriber。这个类提供了一些 hook 方法,我们可以通过重写它们来调整 subscriber 的行为。 默认情况下,它会触发一个无限个数的请求,但是当你想自定义请求元素的个数的时候,扩展 BaseSubscriber 就很方便了。
扩展的时候通常至少要覆盖 hookOnSubscribe(Subscription subscription) 和 hookOnNext(T value) 这两个方法。这个例子中, hookOnSubscribe 方法打印一段话到标准输出,然后进行第一次请求。 然后 hookOnNext 同样进行了打印,同时逐个处理剩余请求。
建议你同时重写 hookOnError、hookOnCancel,以及 hookOnComplete 方法。 你最好也重写。hookFinally 方法。SampleSubscribe 确实是一个最简单的实现了 请求有限个数元素的 Subscriber。
疑问: 当你修改请求操作的时候,你必须注意让 subscriber 向上提出足够的需求, 否则上游的 Flux 可能会被“卡住”。所以 BaseSubscriber 在进行扩展的时候要覆盖 hookOnSubscribe 和 onNext,这样你至少会调用 request 一次。
BaseSubscriber 还提供了 requestUnbounded() 方法来切换到“无限”模式(等同于 request(Long.MAX_VALUE))。
SampleSubscriber 输出如下: 结果是从用户定义的 SampleSubscriber 中输出的,与主函数的 lamada表达式无关。
Subscribed
11
21
31
41
81
2
3
4
5
6
以上方法会返回一个 Subscription 的引用,如果不再需要更多元素你可以通过它来取消订阅。 取消订阅时,源头会停止生成新的数据,并清理相关资源。取消和清理的操作在 Reactor 中是在 接口 Disposable 中定义的。
【7】then 和 map/flatMap的区别: then参数是Mono,只表示顺序执行的下一步,并不依赖于上一步,因为不能获取到上一步的执行结果。map/flatMap参数是Function,入参是上一步的执行结果。
Mono<V> then(Mono<V> other)
@Test
public void testThen(){
Mono.just("string") // Mono<"string">
.then(lengthMono("test")) // Mono<4>
.then(doubleMono(100)) // Mono<200>
.subscribe(System.out::println); // 只会输出 200
}
private Mono<Integer> doubleMono(int i) {
return Mono.just(i + i);
}
private Mono<Integer> lengthMono(String test) {
return Mono.just(test.length());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
【8】zip和zipwith的区别: zip可以一次合并多个源,zipWith一次只能合并两个。具体方法的区别如下:
public static <T1, T2> Flux<Tuple2<T1, T2>> zip(Publisher<? extends T1> source1, Publisher<? extends T2> source2) {
return zip(source1, source2, tuple2Function());
}
public static <T1, T2, T3> Flux<Tuple3<T1, T2, T3>> zip(Publisher<? extends T1> source1, Publisher<? extends T2> source2, Publisher<? extends T3> source3) {
return zip(Tuples.fn3(), source1, source2, source3);
}
public static <T1, T2, T3, T4> Flux<Tuple4<T1, T2, T3, T4>> zip(Publisher<? extends T1> source1, Publisher<? extends T2> source2, Publisher<? extends T3> source3, Publisher<? extends T4> source4) {
return zip(Tuples.fn4(), source1, source2, source3, source4);
}
public static <T1, T2, T3, T4, T5> Flux<Tuple5<T1, T2, T3, T4, T5>> zip(Publisher<? extends T1> source1, Publisher<? extends T2> source2, Publisher<? extends T3> source3, Publisher<? extends T4> source4, Publisher<? extends T5> source5) {
return zip(Tuples.fn5(), source1, source2, source3, source4, source5);
}
public static <T1, T2, T3, T4, T5, T6> Flux<Tuple6<T1, T2, T3, T4, T5, T6>> zip(Publisher<? extends T1> source1, Publisher<? extends T2> source2, Publisher<? extends T3> source3, Publisher<? extends T4> source4, Publisher<? extends T5> source5, Publisher<? extends T6> source6) {
return zip(Tuples.fn6(), source1, source2, source3, source4, source5, source6);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
zip 使用案例:
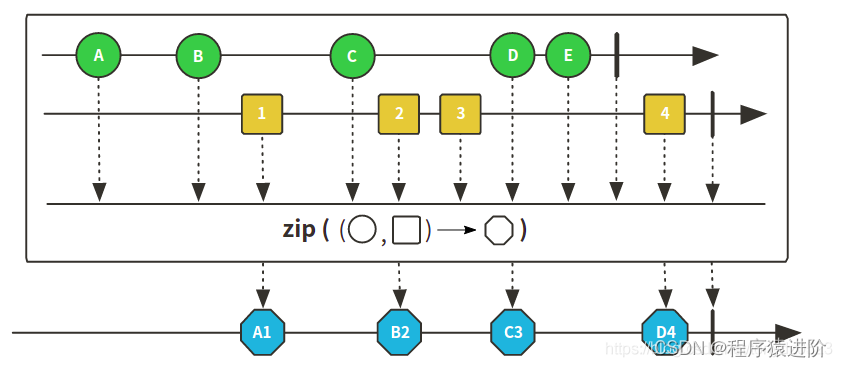
private Flux<String> name () {
return Flux.just("小明", "小花", "小张");
}
private Flux<Integer> age () {
return Flux.just(22, 28, 32);
}
private Flux<Integer> salary () {
return Flux.just(10000, 20000, 30000);
}
@Test
public void zipTest() {
Flux<Tuple3<String, Integer, Integer>> zip = Flux.zip(name(), age(), salary()); // 如果三个方法的参数不同时,会出现木桶效应 or 报错
zip.subscribe(System.out::println);
}
/** 输出如下:
[小明,22,10000]
[小花,28,20000]
[小张,32,30000]
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
将数据转化为类,通过 getTx方法获取数据,也可以直接从 zip中将数据转为类。案例如下:
@Test
public void zipMapTest() {
Flux<Tuple3<String, Integer, Integer>> flux = Flux.zip(name(), age(), salary());
// Emplyee 自己创建的一个类,包含 name,age,salary 属性
Flux<Employee> employee = flux.map(tuple -> new Employee(tuple.getT1(), tuple.getT2(), tuple.getT3()));
employee.subscribe( e -> System.out.println(e.toString()));
}
/** 输出如下:
Employee{name='小明', age=22, salary=10000}
Employee{name='小花', age=28, salary=20000}
Employee{name='小张', age=32, salary=30000}
**/
// 直接在 zip方法中将数据转化为类
@Test
public void zipCollectTest() {
Flux<Employee> flux = Flux.zip(data -> {
return new Employee((String) data[0], (int)data[1], (int)data[2]);
}, name(), age(), salary());
flux.subscribe(System.out::println);
}
/** 输出如下:
Employee{name='小明', age=22, salary=10000}
Employee{name='小花', age=28, salary=20000}
Employee{name='小张', age=32, salary=30000}
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
zipwith 使用案例:
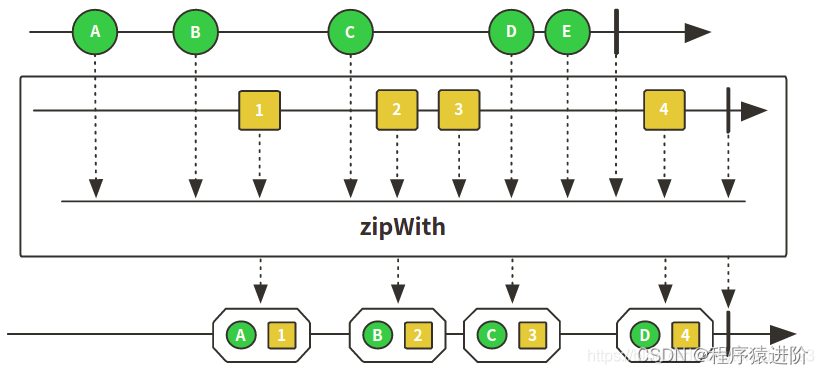
@Test
public void zipWithTest() {
Flux<User> userFlux = name().zipWith(age(), (name, age) -> {
return new User(name, age);
});
userFlux.subscribe(System.out::println);
}
/** 输出如下:
User{name='小明', age=22}
User{name='小花', age=28}
User{name='小张', age=32}
**/
2
3
4
5
6
7
8
9
10
11
12
13
# 二、Sink 池
如何通过定义相应的事件(onNext、onError 和 onComplete)创建一个 Flux 或 Mono。所有这些方法都通过 API来触发我们叫做 sink(池)的事件。
# 1、Generate
这是一种同步地, 逐个地产生值的方法,意味着 sink 是一个 SynchronousSink 而且其 next() 方法在每次回调的时候最多只能被调用一次。你也可以调用 error(Throwable) 或者 complete(),不过是可选的。
最有用的一种方式就是同时能够记录一个状态值(state),从而在使用 sink 发出下一个元素的时候能够 基于这个状态值去产生元素。此时生成器(generator)方法就是一个 BiFunction<S, SynchronousSink<T>, S>, 其中<S>是状态对象的类型。你需要提供一个Supplier<S>来初始化状态值,而生成器需要在每一“回合”生成元素后返回新的状态值(供下一回合使用)。
reactor 简单示例:我们使用一个 int 作为状态值。
@Test
public void generateTest(){
Flux.generate(
() -> 0, // 初始化状态值(state)为0。
(state, sink) -> {
sink.next("3 X " + state + " = " + 3 * state);//我们基于状态值 state 来生成下一个值(state 乘以 3)。
if (state == 10) sink.complete();//我们也可以用状态值来决定什么时候终止序列。
return state + 1;// 返回一个新的状态值 state,用于下一次调用。
}
).subscribe(System.out::println);
}
/**
输出:
3 X 0 = 0
3 X 1 = 3
3 X 2 = 6
3 X 3 = 9
3 X 4 = 12
3 X 5 = 15
3 X 6 = 18
3 X 7 = 21
3 X 8 = 24
3 X 9 = 27
3 X 10 = 30
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
如果状态对象需要清理资源,可以使用 generate(Supplier<S>, BiFunction, Consumer<S>) 这个签名方法来清理状态对象(译者注:Comsumer 在序列终止才被调用)。
下面是一个在 generate 方法中增加 Consumer 的例子:
@Test
public void generateConsumerTest(){
Flux.generate(
AtomicLong::new, // 初始化状态值(state)为0。
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 X " + state + " = " + 3 * i);//我们基于状态值 state 来生成下一个值(state 乘以 3)。
if (i == 10) sink.complete();//我们也可以用状态值来决定什么时候终止序列。
return state;// 返回一个新的状态值 state,用于下一次调用。
},
(state) -> System.out.println("state: " + state)//我们会看到最后一个状态值(11)会被这个 Consumer lambda 输出。
).subscribe(System.out::println);
}
2
3
4
5
6
7
8
9
10
11
12
13
如果 state 使用了数据库连接或者其他需要最终进行清理的资源,这个 Consumer lambda 可以用来在最后关闭连接或完成相关的其他清理任务。
# 2、Create [疑问]
作为一个更高级的创建 Flux 的方式, create 方法的生成方式既可以是同步, 也可以是异步的,并且还可以每次发出多个元素。与 generate 不同的是,create 不需要状态值,另一方面,它可以在回调中触发 多个事件(即使是在未来的某个时间)。
create 有个好处就是可以将现有的 API 转为响应式,比如监听器的异步方法。
假设你有一个监听器 API,它按 chunk 处理数据,有两种事件:(1)一个 chunk 数据准备好的事件;(2)处理结束的事件。如下:
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}
2
3
4
你可以使用 create 方法将其转化为响应式类型 Flux<T>:
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register( // 所有这些都是在 myEventProcessor 执行时异步执行的。
new MyEventListener<String>() { // 桥接 MyEventListener。
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s); //每一个 chunk 的数据转化为 Flux 中的一个元素。
}
}
public void processComplete() {
sink.complete(); //processComplete 事件转换为 onComplete。
}
});
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
此外,既然 create 可以是异步地,并且能够控制背压,你可以通过提供一个 OverflowStrategy 来定义背压行为。
IGNORE: 完全忽略下游背压请求,这可能会在下游队列积满的时候导致 IllegalStateException。
ERROR: 当下游跟不上节奏的时候发出一个 IllegalStateException 的错误信号。
DROP:当下游没有准备好接收新的元素的时候抛弃这个元素。
LATEST:让下游只得到上游最新的元素。
BUFFER:(默认的)缓存所有下游没有来得及处理的元素(这个不限大小的缓存可能导致 OutOfMemoryError)。
Mono 也有一个用于 create 的生成器(generator)—— MonoSink,它不能生成多个元素, 因此会抛弃第一个元素之后的所有元素。
推送(push)模式
create 的一个变体是 push,适合生成事件流。与 create类似,push 也可以是异步地, 并且能够使用以上各种溢出策略(overflow strategies)管理背压。每次只有一个生成线程可以调用 next,complete 或 error。
Flux<String> bridge = Flux.push(sink -> {
myEventProcessor.register(
new SingleThreadEventListener<String>() { //桥接 SingleThreadEventListener API。
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s); //在监听器所在线程中,事件通过调用 next 被推送到 sink。
}
}
public void processComplete() {
sink.complete(); // complete 事件也在同一个线程中。
}
public void processError(Throwable e) {
sink.error(e); //error 事件也在同一个线程中。
}
});
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
推送/拉取(push/pull)混合模式 不像 push,create 可以用于 push 或 pull 模式,因此适合桥接监听器的 的 API,因为事件消息会随时异步地到来。回调方法 onRequest 可以被注册到 FluxSink 以便跟踪请求。这个回调可以被用于从源头请求更多数据,或者通过在下游请求到来的时候传递数据给 sink 以实现背压管理。这是一种推送/拉取混合的模式, 因为下游可以从上游拉取已经就绪的数据,上游也可以在数据就绪的时候将其推送到下游。
Flux<String> bridge = Flux.create(sink -> {
myMessageProcessor.register(
new MyMessageListener<String>() {
public void onMessage(List<String> messages) {
for(String s : messages) {
sink.next(s); //后续异步到达的 message 也会被发送给 sink。
}
}
});
sink.onRequest(n -> {
List<String> messages = myMessageProcessor.request(n); //当有请求的时候取出一个 message。
for(String s : message) {
sink.next(s); //如果有就绪的 message,就发送到 sink。
}
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
清理(Cleaning up) onDispose 和 onCancel 这两个回调用于在被取消和终止后进行清理工作。 onDispose 可用于在 Flux 完成,有错误出现或被取消的时候执行清理。 onCancel 只用于针对“取消”信号执行相关操作,会先于 onDispose 执行。
Flux<String> bridge = Flux.create(sink -> {
sink.onRequest(n -> channel.poll(n))
.onCancel(() -> channel.cancel()) //onCancel 在取消时被调用。
.onDispose(() -> channel.close()) //onDispose 在有完成、错误和取消时被调用。
});
2
3
4
5
# 3、Handle
handle 方法有些不同,它在 Mono 和 Flux 中都有。然而,它是一个实例方法 (instance method),意思就是它要链接在一个现有的源后使用(与其他操作符一样)。
它与 generate 比较类似,因为它也使用 SynchronousSink,并且只允许元素逐个发出。 然而,handle 可被用于基于现有数据源中的元素生成任意值,有可能还会跳过一些元素。 这样,可以把它当做 map 与 filter 的组合。handle 方法签名如下:
handle(BiConsumer<T, SynchronousSink<R>>)
举个例子,响应式流规范允许 null 这样的值出现在序列中。假如你想执行一个类似 map 的操作,你想利用一个现有的具有映射功能的方法,但是它会返回 null,这时候怎么办呢?
例如,下边的方法可以用于 Integer 序列,映射为字母或 null 。
public String alphabet(int letterNumber) {
if (letterNumber < 1 || letterNumber > 26) {
return null;
}
int letterIndexAscii = 'A' + letterNumber - 1;
return "" + (char) letterIndexAscii;
}
2
3
4
5
6
7
我们可以使用 handle 来去掉其中的 null。将 handle 用于一个 "映射 + 过滤 null" 的场景
public String alphabet(int letterNumber) {
if (letterNumber < 1 || letterNumber > 26) {
return null;
}
int letterIndexAscii = 'A' + letterNumber - 1;
return "" + (char) letterIndexAscii;
}
Flux<String> alphabet = Flux.just(-1, 30, 13, 9, 20)
.handle((i, sink) -> {
String letter = alphabet(i); //映射到字母。alphabet自定义的方法
if (letter != null) //如果返回的是 null …
sink.next(letter); //就不会调用 sink.next 从而过滤掉。
});
/**
输出:
M
I
T
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 三、调度器(Schedulers)
在 Reactor 中,执行模式以及执行过程取决于所使用的 Scheduler。 Scheduler 是一个拥有广泛实现类的抽象接口。 Schedulers 类提供的静态方法用于达成如下的执行环境:
【1】当前线程(Schedulers.immediate());
【2】可重用的单线程(Schedulers.single())。注意,这个方法对所有调用者都提供同一个线程来使用, 直到该调度器(Scheduler)被废弃。如果你想使用专一的线程,就对每一个调用使用 Schedulers.newSingle()。
【3】弹性线程池(Schedulers.elastic()。它根据需要创建一个线程池,重用空闲线程。线程池如果空闲时间过长 (默认为 60s)就会被废弃。对于 I/O 阻塞的场景比较适用。 Schedulers.elastic() 能够方便地给一个阻塞的任务分配它自己的线程,从而不会妨碍其他任务和资源。
// 举例:很多时候,信息源是同步和阻塞的。在 Reactor 中,我们用以下方式处理这种信息源:
Mono blockingWrapper = Mono.fromCallable(() -> { // 使用 fromCallable 方法生成一个 Mono;
return /* make a remote synchronous call */ //返回同步、阻塞的资源;
});
blockingWrapper = blockingWrapper.subscribeOn(Schedulers.elastic()); //使用 Schedulers.elastic() 确保对每一个订阅来说运行在一个专门的线程上。
/**
因为调用返回一个值,所以你应该使用 Mono。你应该使用 Schedulers.elastic 因为它会创建一个专门的线程来等待阻塞的调用返回。
注意 subscribeOn 方法并不会“订阅”这个 Mono。它只是指定了订阅操作使用哪个 Scheduler。
**/
2
3
4
5
6
7
8
9
10
【4】固定大小线程池(Schedulers.parallel())。所创建线程池的大小与 CPU 个数等同。
此外,你还可以使用 Schedulers.fromExecutorService(ExecutorService) 基于现有的 ExecutorService 创建 Scheduler。(虽然不太建议,不过你也可以使用 Executor 来创建)。你也可以使用 newXXX 方法来创建不同的调度器。比如 Schedulers.newElastic(yourScheduleName) 创建一个新的名为 yourScheduleName 的弹性调度器。
Reactor 提供了两种在响应式链中调整调度器 Scheduler 的方法:publishOn 和 subscribeOn。 它们都接受一个 Scheduler 作为参数,从而可以改变调度器。但是 publishOn 在链中出现的位置 是有讲究的,而 subscribeOn 则无所谓。
基于此,我们仔细研究一下 publishOn 和 subscribeOn 这两个操作符:
■ publishOn 的用法和处于订阅链(subscriber chain)中的其他操作符一样。它将上游信号传给下游,同时执行指定的调度器 Scheduler 的某个工作线程上的回调。 它会 改变后续的操作符的执行所在线程 (直到下一个 publishOn 出现在这个链上)。
■ subscribeOn 用于订阅(subscription)过程,作用于那个向上的订阅链(发布者在被订阅 时才激活,订阅的传递方向是向上游的)。所以,无论你把 subscribeOn 至于操作链的什么位置, 它都会影响到源头的线程执行环境(context)。 但是,它不会影响到后续的 publishOn,后者仍能够切换其后操作符的线程执行环境。
只有操作链中最早的 subscribeOn 调用才算数。
Flux.range(1, 10000) //创建一个有 10,000 个元素的 Flux。
.publishOn(Schedulers.parallel()) //创建等同于 CPU 个数的线程(最小为4)。
.subscribe(result) //subscribe() 之前什么都不会发生。
2
3
Scheduler.parallel() 创建一个基于单线程 ExecutorService 的固定大小的任务线程池。 因为可能会有一个或两个线程导致问题,它总是至少创建 4 个线程。然后 publishOn 方法便共享了这些任务线程, 当 publishOn 请求元素的时候,会从任一个正在发出元素的线程那里获取元素。这样, 就是进行了任务共享(一种资源共享方式)。
内部机制保证了这些操作符能够借助自增计数器(incremental counters)和警戒条件(guard conditions) 以线程安全的方式工作。例如,如果我们有四个线程处理一个流(就像上边的例子),每一个请求会让计数器自增, 这样后续的来自不同线程的请求就能拿到正确的元素。
# 四、错误处理
在响应式流中,错误(error)是终止(terminal)事件。当有错误发生时,它会导致流序列停止, 并且错误信号会沿着操作链条向下传递,直至遇到你定义的 Subscriber 及其 onError 方法。
下面介绍六中 “错误处理” 的方法:
# 1、静态缺省值
onErrorReturn 方法
@Test
public String doSomethingDangerous(int j){
int i = 1/0;
return "";
}
@Test
public void createTest() {
Flux<String> flux = Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn("RECOVERED");// 方法的返回值要与 map中的返回值对应
flux.subscribe(System.out::println);
}
/**
输出:RECOVERED
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
你还可以通过判断错误信息的内容,来筛选哪些要给出缺省值,哪些仍然让错误继续传递下去:
@Test
public String doSomethingDangerous(int j){
return j == 3 ? "error" : j+"";
}
@Test
public void createTest() {
Flux<String> flux = Flux.range(0,5)
.map(this::doSomethingDangerous)
.onErrorReturn(e -> e.equals("error"), "9error");
flux.subscribe(System.out::println);
}
/**
输出:
0
1
2
error
4
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 2、异常处理方法
如果你不只是想要在发生错误的时候给出缺省值,而是希望提供一种更安全的处理数据的方式, 可以使用 onErrorResume。捕获并执行一个异常处理方法。
假设,你会尝试从一个外部的不稳定服务获取数据,但仍然会在本地缓存一份可能有些过期的数据, 因为缓存的读取更加可靠。可以这样来做:
Flux.just("key1", "key2")
.flatMap(k -> callExternalService(k)) //对于每一个 key, 异步地调用一个外部服务。
.onErrorResume(e -> getFromCache(k));//如果对外部服务的调用失败,则再去缓存中查找该 key。注意,这里无论 e 是什么,都会执行异常处理方法。
2
3
就像 onErrorReturn,onErrorResume 也有可以用于预先过滤错误内容的方法变体,可以基于异常类或 Predicate 进行过滤。它实际上是用一个 Function 来作为参数,还可以返回一个新的流序列。
Flux.just("timeout1", "unknown", "key2")
.flatMap(k -> callExternalService(k))
.onErrorResume(error -> {//这个函数式允许开发者自行决定如何处理。
if (error instanceof TimeoutException) //如果源超时,使用本地缓存。
return getFromCache(k);
else if (error instanceof UnknownKeyException) //如果源找不到对应的 key,创建一个新的实体。
return registerNewEntry(k, "DEFAULT");
else
return Flux.error(error); //否则, 将问题“重新抛出”。
});
2
3
4
5
6
7
8
9
10
# 3、动态候补值
有时候并不想提供一个错误处理方法,而是想在接收到错误的时候计算一个候补的值。捕获并动态计算一个候补)。
例如,如果你的返回类型本身就有可能包装有异常(比如 Future.complete(T success) vs Future.completeExceptionally(Throwable error)),你有可能使用流中的错误包装起来实例化返回值。
这也可以使用上一种错误处理方法的方式(使用 onErrorResume)解决,代码如下:
erroringFlux.onErrorResume(error -> Mono.just( //在 onErrorResume 中,使用 Mono.just 创建一个 Mono。
myWrapper.fromError(error) // 将异常包装到另一个类中。
));
2
3
# 4、捕获并重新抛出
在“错误处理方法”的例子中,基于 flatMap 方法的最后一行,捕获,包装到一个业务相关的异常,然后抛出业务异常:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorResume(original -> Flux.error(
new BusinessException("oops, SLA exceeded", original)
);
2
3
4
5
然而还有一个更加直接的方法—— onErrorMap:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorMap(original -> new BusinessException("oops, SLA exceeded", original));
2
3
# 5、记录错误日志
如果对于错误你只是想在不改变它的情况下做出响应(如记录日志),并让错误继续传递下去, 那么可以用 doOnError 方法。捕获,记录错误日志,并继续抛出。 这个方法与其他以 doOn 开头的方法一样,只起副作用("side-effect")。它们对序列都是只读, 而不会带来任何改动。
LongAdder failureStat = new LongAdder();
Flux<String> flux =
Flux.just("unknown")
.flatMap(k -> callExternalService(k)) //对外部服务的调用失败…
.doOnError(e -> {
failureStat.increment();
log("uh oh, falling back, service failed for key " + k); //记录错误日志
})
.onErrorResume(e -> getFromCache(k)); //然后回调错误处理方法。
2
3
4
5
6
7
8
9
# 6、使用资源和 try-catch 代码块
在 Reactor 中都有对应的方法: using 和 doFinally:
AtomicBoolean isDisposed = new AtomicBoolean();
Disposable disposableInstance = new Disposable() {
@Override
public void dispose() {
isDisposed.set(true); //在订阅或执行流序列之后, isDisposed 会置为 true。
}
@Override
public String toString() {
return "DISPOSABLE";
}
};
Flux<String> flux =
Flux.using(
() -> disposableInstance, //第一个 lambda 生成资源,这里我们返回模拟的(mock) Disposable。
disposable -> Flux.just(disposable.toString()), //二个 lambda 处理资源,返回一个 Flux<T>。
Disposable::dispose // 类型 finally 第三个 lambda 在 2) 中的资源 Flux 终止或取消的时候,用于清理资源。
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
另一方面, doFinally 在序列终止(无论是 onComplete、onError还是取消)的时候被执行, 并且能够判断是什么类型的终止事件(完成、错误还是取消?)。
LongAdder statsCancel = new LongAdder(); // 我们想进行统计,所以用到了 LongAdder。
Flux<String> flux =
Flux.just("foo", "bar")
.doFinally(type -> {
if (type == SignalType.CANCEL) //doFinally 用 SignalType 检查了终止信号的类型。
statsCancel.increment(); //如果只是取消,那么统计数据自增。
})
.take(1); // take(1) 能够在发出 1 个元素后取消流。
2
3
4
5
6
7
8
9
# 7、重试 retry
还有一个用于错误处理的操作符你可能会用到,就是 retry,见文知意,用它可以对出现错误的序列进行重试。
问题是它对于上游 Flux 是基于重订阅(re-subscribing)的方式。这实际上已经一个不同的序列了, 发出错误信号的序列仍然是终止了的。为了验证这一点,我们可以在继续用上边的例子,增加一个 retry(1) 代替 onErrorReturn 来重试一次。
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.elapsed() // elapsed 会关联从当前值与上个值发出的时间间隔(译者加:如下边输出的内容中的 259/249/251…)。
.retry(1)
.subscribe(System.out::println, System.err::println); //我们还是要看一下 onError 时的内容。
Thread.sleep(2100); //确保我们有足够的时间可以进行 4x2 次 tick。
/** 输出如下:
259,tick 0
249,tick 1
251,tick 2
506,tick 0 *** 注意:一个新的 interval 从 tick 0 开始。多出来的 250ms 间隔来自于第 4 次 tick, 就是导致出现异常并执行 retry 的那次(译者加:我在机器上测试的时候 elapsed “显示”的时间间隔没有加倍,但是确实有第 4 次的间隔)。
248,tick 1
253,tick 2
java.lang.RuntimeException: boom
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
可见, retry(1) 不过是再一次从新订阅了原始的 interval,从 tick 0 开始。第二次, 由于异常再次出现,便将异常传递到下游了。
# 五、Reacotr 基本原理
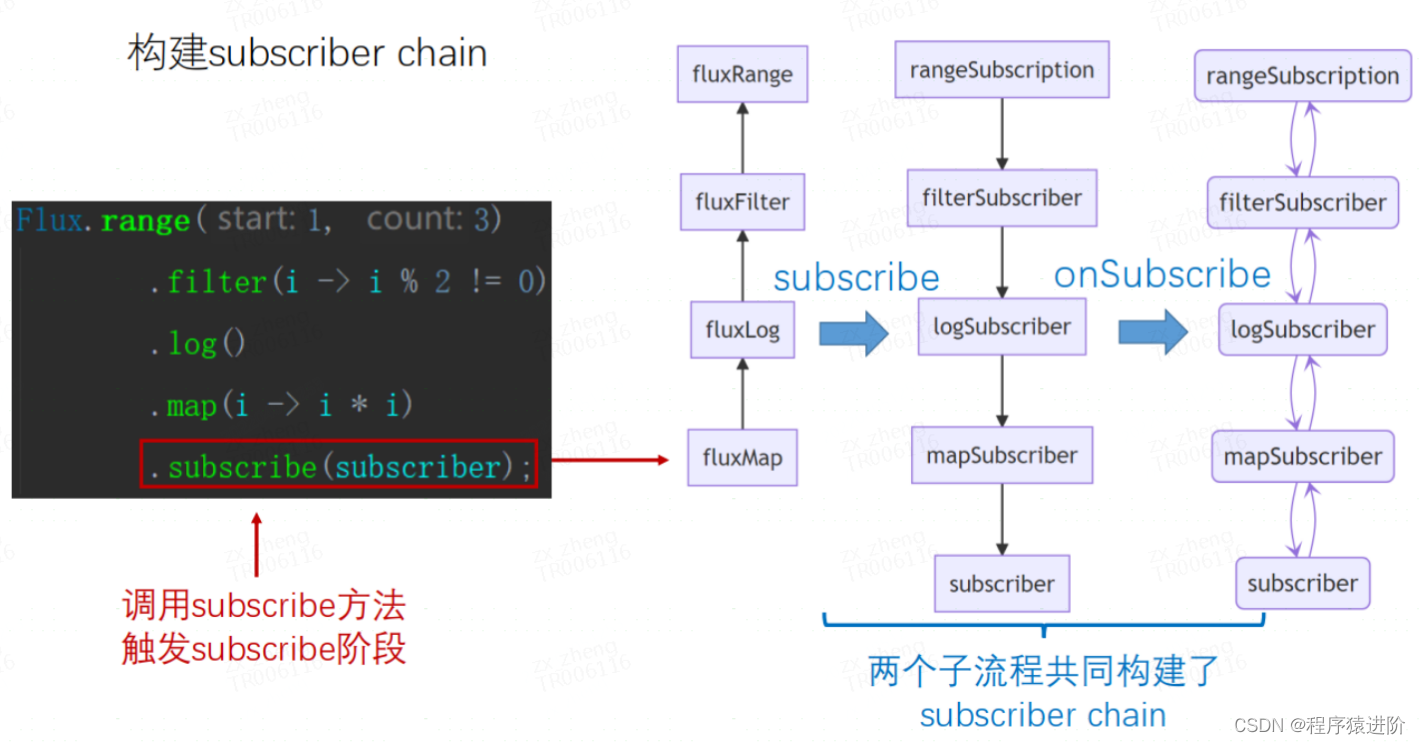
后续执行流程,通过如下案例分析
Flux.range(1, 3)
.filter(i -> i%2 > 0).log()
.map(i -> i * i)
.subscribe(System.out::println); // 结果: 1 9
2
3
4
# 1、Publisher 实现
Publisher<T> 是一个可以提供 0-N个序列元素的提供者,如下图,它继承自 Flux。
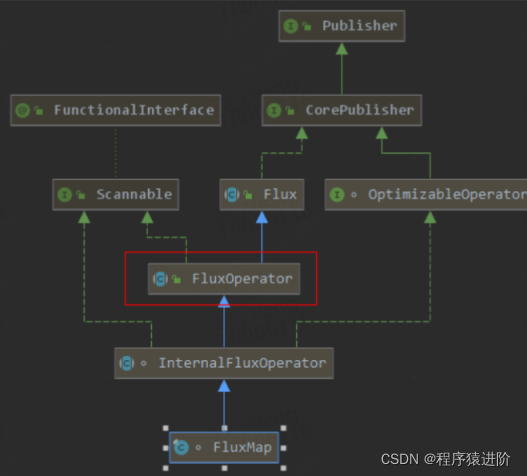
Publisher 根据订阅者的逻辑进行推送序列元素,我们可以生产者看作一个过程,订阅者看作一个结果。这也是响应式的一个重要特点:没有订阅者时发布者什么也不做,因为没有实际意义。
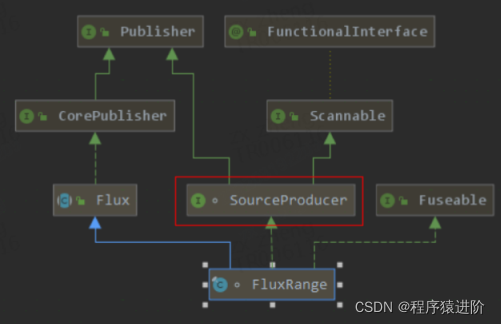
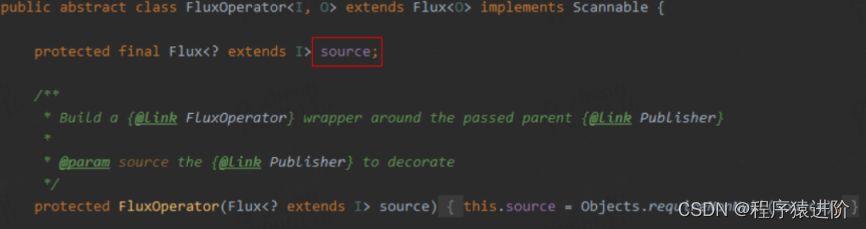
我们可以将整个调用看作职责链模式,fluxRange -> fluxFilter -> fluxLog -> fluxMap 。这里的 source是用来指向上游的 Publisher。
# 2、Subscriber 实现
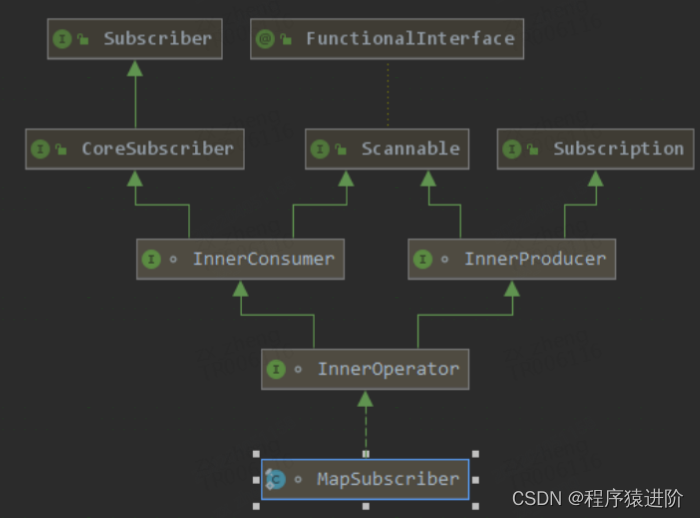
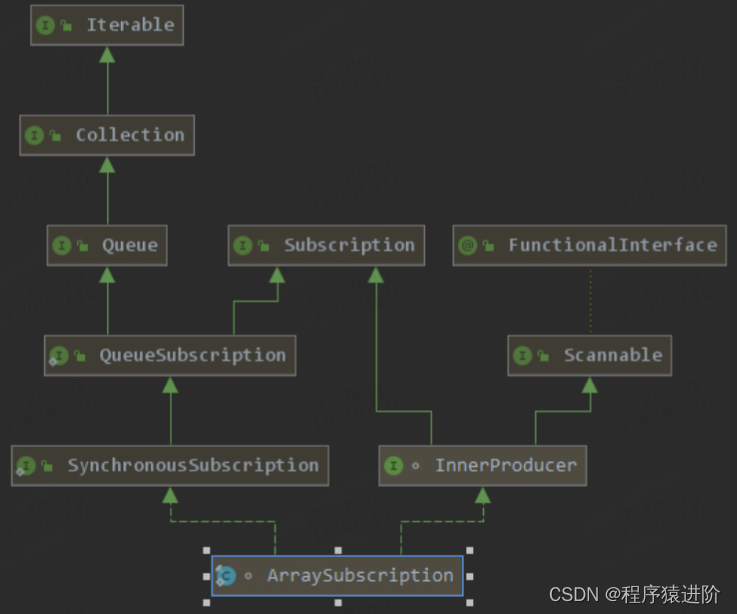
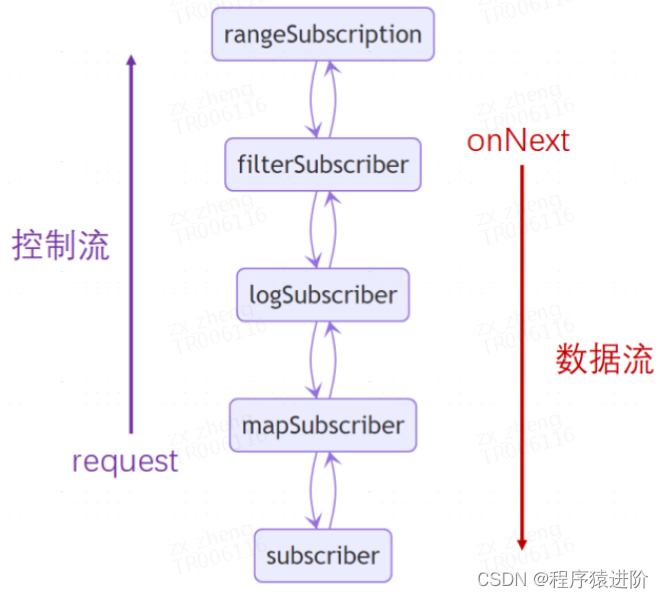
Reactor 基本原理: subscriber chain:rangeSubscription -> filterSubscriber -> logSubscriber -> mapSubscriber 通过 actual指向下游的 Subscriber,通过 s指向上游级联的 Subscription。
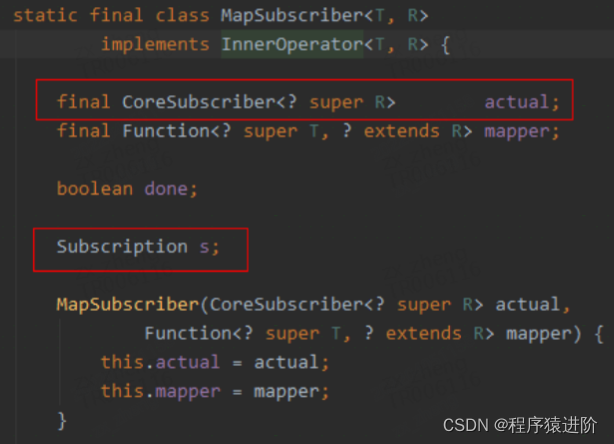
assembly 阶段:

subscribe 阶段
runtime 阶段:以 subscriber chain为骨架的控制流和数据流
# 扩展项【可选】
# 1、为什么会产生 Reactor
【为什么需要这样的异步响应式开发库呢?】
【理由】之前我们使用“异步非阻塞”解决阻塞导致的资源问题。执行过程会切换到另一个使用同样底层资源的活跃任务,然后等异步调用返回结果再去处理。
【Java 提供了两种在 JVM 上编写异步代码方式】:
【1】回调(Callbacks) :异步方法没有返回值,而是采用一个 callback 作为参数(lambda 或匿名类),当结果出来后回调这个 callback。常见的例子比如 Swings 的 EventListener。
【2】Futures :异步方法 立即 返回一个 Future<T>,该异步方法要返回结果的是 T 类型,通过 Future封装。这个结果并不是 立刻 可以拿到,而是等实际处理结束才可用。比如, ExecutorService 执行 Callable<T> 任务时会返回 Future 对象。
【上面两种方式都有局限性】 【理由】回调很难组合起来,因为很快就会导致代码难以理解和维护(即所谓的“回调地狱(callback hell)”)。
【情景一】:在用户界面上显示用户的5个收藏,或者如果没有任何收藏提供5个建议。这需要3个 服务(一个提供收藏的ID列表,第二个服务获取收藏内容,第三个提供建议内容):回调地狱(Callback Hell)的例子
userService.getFavorites(userId, new Callback<List<String>>() { //基于回调的服务使用一个匿名 Callback 作为参数。后者的两个方法分别在异步执行成功 或异常时被调用。
public void onSuccess(List<String> list) { //获取到收藏ID的list后调用第一个服务的回调方法 onSuccess。
if (list.isEmpty()) { //如果 list 为空, 调用 suggestionService。
suggestionService.getSuggestions(new Callback<List<Favorite>>() {
public void onSuccess(List<Favorite> list) { // 服务 suggestionService 传递 List<Favorite> 给第二个回调
UiUtils.submitOnUiThread(() -> { // 既然是处理 UI,我们需要确保消费代码运行在 UI 线程。
list.stream()
.limit(5)
.forEach(uiList::show);
});
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
} else {
list.stream()
.limit(5)// 使用 Java 8 Stream 来限制建议数量为5,然后在 UI 中显示。
.forEach(favId -> favoriteService.getDetails(favId, //再一次回调。这次对每个ID,获取 Favorite 对象在 UI 线程中推送到前端显示。
new Callback<Favorite>() {
public void onSuccess(Favorite details) {
UiUtils.submitOnUiThread(() -> uiList.show(details));
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
}
));
}
}
public void onError(Throwable error) {
UiUtils.errorPopup(error);
}
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
我们看一下用 Reactor 实现同样功能:
userService.getFavorites(userId) // 我们获取到收藏ID的流
.flatMap(favoriteService::getDetails) //我们 异步地转换 它们(ID) 为 Favorite 对象(使用 flatMap),现在我们有了 `Favorite`流。
.switchIfEmpty(suggestionService.getSuggestions()) // 一旦 Favorite 为空,切换到 suggestionService。
.take(5) //我们只关注流中的最多5个元素。
.publishOn(UiUtils.uiThreadScheduler()) //最后,我们希望在 UI 线程中进行处理。
.subscribe(uiList::show, UiUtils::errorPopup); //通过描述对数据的最终处理(在 UI 中显示)和对错误的处理(显示在 popup 中)来触发(subscribe)。
2
3
4
5
6
如果你想确保“收藏的ID”的数据在800ms内获得(如果超时,从缓存中获取)呢?在基于回调的代码中, 会比较复杂。但 Reactor 中就很简单,在处理链中增加一个 timeout 的操作符即可。
userService.getFavorites(userId)
.timeout(Duration.ofMillis(800)) //如果流在超时时限没有发出(emit)任何值,则发出错误(error)
.onErrorResume(cacheService.cachedFavoritesFor(userId)) //一旦收到错误,交由 cacheService 处理。
.flatMap(favoriteService::getDetails) //处理链后边的内容与上例类似。
.switchIfEmpty(suggestionService.getSuggestions())
.take(5)
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(uiList::show, UiUtils::errorPopup);
2
3
4
5
6
7
8
Futures 比回调要好一点,但即使在 Java 8 引入了 CompletableFuture,它对于多个处理的组合仍不够好用。 编排多个 Futures 是可行的,但却不易。此外,Future 还有一个问题:当对 Future 对象最终调用 get() 方法时,仍然会导致阻塞,并且缺乏对多个值以及更进一步对错误的处理。
【情景二】:我们首先得到 ID 的列表,然后通过它进一步获取到“对应的 name 和 statistics” 为元素的列表,整个过程用异步方式来实现。CompletableFuture 处理组合的例子
CompletableFuture<List<String>> ids = ifhIds(); //以一个 Future 开始,其中封装了后续将获取和处理的 ID 的 list。
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> { //获取到 list 后边进一步对其启动异步处理任务。
Stream<CompletableFuture<String>> zip =
l.stream().map(i -> { //对于 list 中的每一个元素:
CompletableFuture<String> nameTask = ifhName(i); //异步地得到相应的 name。
CompletableFuture<Integer> statTask = ifhStat(i); // 异步地得到相应的 statistics。
return nameTask.thenCombineAsync(statTask, (name, stat) -> "Name " + name + " has stats " + stat); // 将两个结果一一组合。
});
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList()); //我们现在有了一个 list,元素是 Future(表示组合的任务,类型是 CompletableFuture),为了执行这些任务, 我们需要将这个 list(元素构成的流) 转换为数组(List)。
CompletableFuture<String>[] combinationArray = combinationList.toArray(new CompletableFuture[combinationList.size()]);
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray); //将这个数组传递给 CompletableFuture.allOf,返回一个 Future ,当所以任务都完成了,那么这个 Future 也就完成了。
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join) //有点麻烦的地方在于 allOf 返回的是 CompletableFuture<Void>,所以我们遍历这个 Future 的`List`, ,然后使用 join() 来手动它们的结果(不会导致阻塞,因为 AllOf 确保这些 Future 全部完成)
.collect(Collectors.toList()));
});
List<String> results = result.join(); //一旦整个异步流水线被触发,我们等它完成处理,然后返回结果列表。
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
回调或 Future 遇到的窘境是类似的,这也是响应式编程要通过 Publisher-Suscriber 方式来解决的。
# 2、响应式编程的优点
类型 Reactor 这样的响应式库的目的就是弥补命令式编程所带来的不足,例如上述“经典”的JVM异步方式所带来的不足,具体如下:
【1】可编排性(Composability) 以及 可读性(Readability):编排任务与代码的可读性是紧密相关的。例如上面的“回调地狱”代码示难以阅读和分析的。Reactor 提供了丰富的编排操作,从而代码直观反映了处理流程,并且所有的操作在同一层次,避免了嵌套。
【2】就像装配流水线:你可以想象数据在响应式应用中的处理,就像流过一条装配流水线。Reactor 既是传送带, 又是一个个的装配工或机器人。原材料从源头(最初的 Publisher)流出,最终被加工为成品, 等待被推送到消费者(或者说 Subscriber)。原材料会经过不同的中间处理过程,或者作为半成品与其他半成品进行组装。如果某处有齿轮卡住, 或者某件产品的包装过程花费了太久时间,相应的工位就可以向上游发出信号来限制或停止发出原材料。
【3】操作符(Operators):在 Reactor 中,操作符(operator)就像装配线中的工位(操作员或装配机器人)。每一个操作符对 Publisher 进行相应的处理,然后将 Publisher 包装为一个新的 Publisher。就像一个链条, 数据源自第一个 Publisher,然后顺链条而下,在每个环节进行相应的处理。最终,一个订阅者 (Subscriber)终结这个过程。请记住,在订阅者(Subscriber)订阅(subscribe)到一个 发布者(Publisher)之前,什么都不会发生。Reactor 这样的响应式库所带来的最大附加价值之一就是提供丰富的操作符。包括基础的转换操作, 到过滤操作,甚至复杂的编排和错误处理操作。
【4】subscribe() 之前什么都不会发生:在 Reactor 中,当创建了一条 Publisher 处理链,数据还不会开始生成。事实上,你是创建了 一种抽象的对于异步处理流程的描述(从而方便重用和组装)。当真正“订阅(subscrib)”的时候,你需要将 Publisher 关联到一个 Subscriber 上,然后才会触发整个链的流动。这时候,Subscriber 会向上游发送一个 request 信号,一直到达源头的Publisher。
【5】背压:订阅者可以无限接受数据并让它的源头 “满负荷”推送所有的数据,也可以通过使用 request 机制来告知源头它一次最多能够处理 n 个元素。中间环节的操作也可以影响 request。想象一个能够将每10个元素分批打包的缓存(buffer)操作。 如果订阅者请求一个元素,那么对于源头来说可以生成10个元素。此外预取策略也可以使用了, 比如在订阅前预先生成元素。这样能够将“推送”模式转换为“推送+拉取”混合的模式,如果下游准备好了,可以从上游拉取 n 个元素;但是如果上游元素还没有准备好,下游还是要等待上游的推送。
【6】热(Hot) vs 冷(Cold):到目前为止,我们一直认为 Flux 和 Mono 都是这样的:它们都代表了一种异步的数据序列, 在订阅(subscribe)之前什么都不会发生。但是实际上,广义上有两种发布者:“热”与“冷”(hot and cold)。区别主要在于响应式流如何 对订阅者进行响应:
■ 一个“冷”的序列,指对于每一个 Subscriber,都会收到从头开始所有的数据。如果源头 生成了一个 HTTP 请求,对于每一个订阅都会创建一个新的 HTTP 请求。
Flux<String> source = Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.filter(s -> s.startsWith("o"))
.map(String::toUpperCase);
source.subscribe(d -> System.out.println("Subscriber 1: "+d));
source.subscribe(d -> System.out.println("Subscriber 2: "+d));
/** 输出
blue
green
orange
Subscriber 1: ORANGE
purple
blue
green
orange
Subscriber 2: ORANGE
purple
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
■ 一个“热”的序列,指对于一个 Subscriber,只能获取从它开始订阅之后 发出的数据。不过注意,有些“热”的响应式流可以缓存部分或全部历史数据。 通常意义上来说,一个“热”的响应式流,甚至在即使没有订阅者接收数据的情况下,也可以发出数据(这一点同 “Subscribe() 之前什么都不会发生”的规则有冲突)。
UnicastProcessor<String> hotSource = UnicastProcessor.create();
Flux<String> hotFlux = hotSource.publish()
.autoConnect()
.map(String::toUpperCase);
hotFlux.subscribe(d -> System.out.println("Subscriber 1 to Hot Source: "+d));
hotSource.onNext("blue");
hotSource.onNext("green");
hotFlux.subscribe(d -> System.out.println("Subscriber 2 to Hot Source: "+d));
hotSource.onNext("orange");
hotSource.onNext("purple");
hotSource.onComplete();
/**输出
Subscriber 1 to Hot Source: BLUE
Subscriber 1 to Hot Source: GREEN
Subscriber 1 to Hot Source: ORANGE
Subscriber 2 to Hot Source: ORANGE
Subscriber 1 to Hot Source: PURPLE
Subscriber 2 to Hot Source: PURPLE
结论:第一个订阅者收到了所有的四个颜色,第二个订阅者由于是在前两个颜色发出之后订阅的, 故而收到了之后的两个颜色,在输出中有两次 "ORANGE" 和 "PURPLE"。从这个例子可见, 无论是否有订阅者接入进来,这个 Flux 都会运行。
**/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
just 是 Reactor 中少数几个“热”操作符的例子之一:它直接在组装期(assembly time) 就拿到数据,如果之后有谁订阅它,就重新发送数据给订阅者。再拿 HTTP 调用举例,如果给 just 传入的数据是一个 HTTP 调用的结果,那么之后在初始化 just 的时候才会进行唯一的一次网络调用。
如果想将 just 转化为一种 冷 的发布者,你可以使用 defer。它能够将刚才例子中对 HTTP 的请求延迟到订阅时(这样的话,对于每一个新的订阅来说,都会发生一次网络调用)。
# 参考文档
Reactor3 参考文档 GitHub (opens new window)
Reactor JavaDoc API (opens new window)