在了解 Kafka的事务之前,先说一下 Kafka中幂等和事务(Kafka 0.11.0.0版本引入的两个特性)以此来实现 Exactly once(精确一次)。
# 一、Kafka 消息送达语义
消息送达语义是消息系统中一个常见的问题,主要包含三种语义:
【1】At most once:消息发送或消费至多一次;
【2】At least once:消息发送或消费至少一次;
【3】Exactly once:消息恰好只发送一次或只消费一次;
下面分别从生产者和消费者的角度来阐述这三种消息送达语义。
# 生产者 Producer
从 Producer的角度来看,At most once意味着 Producer发送完一条消息后,不会确认消息是否成功送达。这样从 Producer的角度来看,消息仅仅被发送一次,也就存在者丢失的可能性。
从 Producer的角度来看,At least once意味着 Producer发送完一条消息后,会确认消息是否发送成功。如果 Producer没有收到 Broker的 ack确认消息,那么会不断重试发送消息。 这样就意味着消息可能被发送不止一次,也就存在这消息重复的可能性。
从 Producer的角度来看,Exactly once意味着 Producer消息的发送是幂等的。 这意味着不论消息重发多少遍,最终 Broker上记录的只有一条不重复的数据。
# Producer At least once配置
Kafka默认的 Producer消息送达语义就是 At least once,这意味着我们不用做任何配置就能够实现 At least once消息语义。原因是 Kafka中默认 acks=1并且 retries=2147483647。
TIP
acks 机制:broker 表示发来的数据已确认接收无误,表示数据已经保存到磁盘。 0:不等待 broker 返回确认消息 1:等待 topic 中某个 partition leader 保存成功的状态反馈 -1/all:等待 topic 中某个 partition 所有副本都保存成功的状态反馈
# Producer At most once配置
我们可以通过配置 Producer的以下配置项来实现 At most once语义:acks=0 && retries=0
当配置了retires的值后,如果没有将 max.in.flight.requests.per.connection配置的值设置为1,有可能造成消息乱序的结果。max.in.flight.requests.per.connection配置代表着一个 Producer同时可以发送的未收到确认的消息数量。如果max.in.flight.requests.per.connection数量大于1,那么可能发送了message1后,在没有收到确认前就发送了message2,此时 message1发送失败后触发重试,而 message2直接发送成功,就造成了Broker上消息的乱序。max.in.flight.requests.per.connection的默认值为5。
# Producer Exactly once配置
Exactly once是 Kafka从版本0.11之后提供的高级特性。我们可以通过配置 Producer的以下配置项来实现 Exactly once语义:
【1】enable.idempotence=true。enable.idempotence配置项表示是否使用幂等性。当 enable.idempotence配置为 true时,acks必须配置为all。并且建议 max.in.flight.requests.per.connection的值小于5。
【2】acks=all。enable.idempotence 配置项表示是否使用幂等性。当 enable.idempotence配置为 true时,acks必须配置为all。并且建议max.in.flight.requests.per.connection 的值小于 5。
# Kafka如何实现消息发送幂等性
Kafka本身支持 At least once消息送达语义,因此实现消息发送的幂等关键是要实现 Broker端消息的去重。为了实现消息发送的幂等性,Kafka引入了两个新的概念:
【1】PID:每个新的 Producer在初始化的时候会被分配一个唯一的PID,这个 PID对用户是不可见的;
【2】Sequence Numbler:对于每个PID,该 Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number;
Broker端在内存中保存了这 Sequence Numbler,对于接收的每条消息,如果其序列号的值(SN_new)比 Broker端中维护的对应的序列号的值(SN_old)大1(即SN_new = SN_old + 1)时,Broker才会接收它,否则将其丢弃。这样就可以实现了消息重复提交了。但是,只能保证单个 Producer对于同一个 <Topic, Partition>的 Exactly Once语义。不能保证同一个Producer一个 Topic不同的 Partion幂等。
WARNING
Kafka幂等性配置时要求 max.in.flight.requests.per.connection 小于等于 5 的主要原因是:Server 端的 ProducerStateManager 实例会缓存每个 PID 在每个 Topic-Partition 上发送的最近 5 个 batch 数据(这个 5 是写死的,至于为什么是 5,可能跟经验有关,当不设置幂等性时,当这个设置为 5 时,性能相对来说较高,社区是有一个相关测试文档),如果超过 5,ProducerStateManager 就会将最旧的 batch 数据清除。假设应用将 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 设置为 6,假设发送的请求顺序是 1、2、3、4、5、6,这时候 server 端只能缓存 2、3、4、5、6 请求对应的 batch 数据,这时候假设请求 1 发送失败,需要重试,当重试的请求发送过来后,首先先检查是否为重复的 batch,这时候检查的结果是否,之后会开始 check 其 sequence number 值,这时候只会返回一个 OutOfOrderSequenceException 异常,client 在收到这个异常后,会再次进行重试,直到超过最大重试次数或者超时,这样不但会影响 Producer 性能,还可能给 Server 带来压力(相当于client 狂发错误请求)。
# 消费者 Consumer
从 Consumer的角度来看,At most once 意味着 Consumer对一条消息最多消费一次,因此有可能存在消息消费失败依旧提交offset的情况。 考虑下面的情况:Consumer首先读取消息,然后提交 offset,最后处理这条消息。在处理消息时,Consumer宕机了,此时 offset已经提交,下一次读取消息时读到的是下一条消息了,这就是 At most once消费。
从Consumer的角度来看,At least once意味着 Consumer对一条消息可能消费多次。 考虑下面的情况:Consumer首先读取消息,然后处理这条消息,最后提交offset。在处理消息时成功后,Consumer宕机了,此时 offset还未提交,下一次读取消息时依旧是这条消息,那么处理消息的逻辑又将被执行一遍,这就是 At least once消费。
从Consumer的角度来看,Exactly once意味着消息的消费处理逻辑和offset的提交是原子性的,即消息消费成功后 offset改变,消息消费失败 offset也能回滚。
# Consumer At least once配置
【1】enable.auto.commit=false:禁止后台自动提交offset;
【2】手动调用 consumer.commitSync()来提交offset。手动调用保证了 offset即时更新;
通过手动提交offset,就可以实现 Consumer At least once语义。
# Consumer At most once配置
【1】enable.auto.commit=true:后台定时提交offset;
【2】auto.commit.interval.ms:配置为一个很小的数值。auto.commit.interval.ms表示后台提交 offset的时间间隔。
通过自动提交offset,并且将定时提交时间间隔设置的很小,就可以实现 Consumer At most once语义。
# Consumer Exactly once配置
isolation.level=read_committed:isolation.level表示何种类型的 message对 Consumer可见:一个常见的 Exactly once的的使用场景是:当我们订阅了一个Topic,然后往另一个 Topic里写入数据时,我们希望这两个操作是原子性的,即如果写入消息失败,那么我们希望读取消息的 offset可以回滚。
此时可以通过 Kafka的 Transaction特性来实现。Kafka是在版本0.11之后开始提供事务特性的。我们可以将 Consumer读取数据和Producer写入数据放进一个同一个事务中,在事务没有成功结束前,所有的这个事务中包含的消息都被标记为 uncommitted。只有事务执行成功后,所有的消息才会被标记为 committed。
我们知道,offset信息是以消息的方式存储在 Broker的 __consumer_offsets topic中的。因此在事务开始后,Consumer读取消息后,所有的 offset消息都是uncommitted状态。所有的 Producer写入的消息也都是 uncommitted状态。
而 Consumer可以通过配置 isolation.level来决定 uncommitted状态的 message是否对 Consumer可见。isolation.level拥有两个可选值:read_committed和 read_uncommitted。默认值为 read_uncommitted。当我们将 isolation.level配置为 read_committed后,那么所有事务未提交的数据就都对 Consumer不可见了,也就实现了 Kafka的事务语义。
# 二、事务
幂等:生产者在进行重试的时候有可能会重复写入消息,而使用 Kafka的幂等性功能之后就可以避免这种情况。
# 生产者事务相关配置
开启幂等性功能的方式很简单,只需显式地将生产者客户端参数enable.idempotence=true(默认值为false)Kafka的幂等只能保证单个生产者会话(session)中单分区的幂等。幂等性不能跨多个分区运作,而事务可以弥补这个缺陷。 事务可以保证对多个分区写入操作的原子性。操作的原子性是指多个操作要么全部成功,要么全部失败,不存在部分成功、部分失败的可能。
为了使用事务,Producer 必须显式设置唯一的transactionalId。事务要求生产者开启幂等性,因此通过将 transactional.id参数设置为非空从而开启事务特性的同时需要将 enable.idempotence设置为true(设置 transactional.id后,enable.idempotence会自动设置为true),如果用户显式地将enable.idempotence设置为false,则会报出 ConfigException的异常。
transactionalId 与 PID一一对应,两者不同的是 transactionalId由用户显式设置,而 PID是由 Kafka内部分配的。
拒绝僵尸实例(Zombie fencing): 为了保证新的生产者启动后具有相同 transactionalId的旧生产者能够立即失效,每个生产者通过 transactionalId获取 PID的同时,还会获取一个单调递增的 producer epoch。如果使用同一个 transactionalId开启两个生产者,Kafka收到事务提交请求时检查当前事务提交者的 epoch不是最新的,那么就会拒绝该 Producer的请求。从而达成拒绝僵尸实例的目标。
Kafka中的事务特性主要用于以下两种场景:
【1】生产者发送多条消息可以封装在一个事务中,形成一个原子操作。 多条消息要么都发送成功,要么都发送失败。
【2】read-process-write模式: 将消息消费和生产封装在一个事务中,形成一个原子操作。在一个流式处理的应用中,常常一个服务需要从上游接收消息,然后经过处理后送达到下游,这就对应着消息的消费和生成。
从生产者的角度分析,通过事务,Kafka可以保证跨生产者会话的消息幂等发送,以及跨生产者会话的事务恢复。前者表示具有相同transactionalId的新生产者实例被创建且工作的时候,旧的且拥有相同 transactionalId的生产者实例将不再工作。后者指当某个生产者实例宕机后,新的生产者实例可以保证任何未完成的旧事务要么被提交(Commit),要么被中止(Abort),如此可以使新的生产者实例从一个正常的状态开始工作。KafkaProducer提供了5个与事务相关的方法,详细如下:
/**
* 初始化事务
*/
public void initTransactions();
/**
* 开启事务
*/
public void beginTransaction() throws ProducerFencedException ;
/**
* 在事务内提交已经消费的偏移量
*/
public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException ;
/**
* 提交事务
*/
public void commitTransaction() throws ProducerFencedException;
/**
* 丢弃事务
*/
public void abortTransaction() throws ProducerFencedException ;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
initTransactions()方法用来初始化事务;
beginTransaction()方法用来开启事务;
sendOffsetsToTransaction()方法为消费者提供在事务内的位移提交的操作;
commitTransaction()方法用来提交事务;
abortTransaction()方法用来中止事务,类似于事务回滚;
下面是使用 Kafka事务特性的例子,这段代码 Producer开启了一个事务,然后在这个事务中发送了两条消息。这两条消息要么都发送成功,要么都失败。
KafkaProducer producer = createKafkaProducer( "bootstrap.servers", "localhost:9092", "transactional.id”, “my-transactional-id");
producer.initTransactions();
producer.beginTransaction();
producer.send("outputTopic", "message1");
producer.send("outputTopic", "message2");
producer.commitTransaction();
2
3
4
5
6
下面这段代码即为 read-process-write模式,在一个 Kafka事务中,同时涉及到了生产消息和消费消息。
KafkaProducer producer = createKafkaProducer(
"bootstrap.servers", "localhost:9092",
"transactional.id", "my-transactional-id");
KafkaConsumer consumer = createKafkaConsumer(
"bootstrap.servers", "localhost:9092",
"group.id", "my-group-id",
"isolation.level", "read_committed");
consumer.subscribe(singleton("inputTopic"));
producer.initTransactions();
while (true) {
ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
producer.beginTransaction();
for (ConsumerRecord record : records)
producer.send(producerRecord(“outputTopic”, record));
producer.sendOffsetsToTransaction(currentOffsets(consumer), group);
producer.commitTransaction();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
注意:在理解消息的事务时,一直处于一个错误理解是,把操作 db的业务逻辑跟操作消息当成是一个事务,如下所示:
void kakfa_in_tranction(){
// 1.kafa的操作:读取消息或生产消息
kafkaOperation();
// 2.db操作
dbOperation();
}
2
3
4
5
6
其实这个是有问题的。操作 DB数据库的数据源是DB,消息数据源是kfaka,这是完全不同两个数据。一种数据源(如mysql,kafka)对应一个事务,所以它们是两个独立的事务。kafka事务指 kafka一系列生产、消费消息等操作组成一个原子操作,db事务是指操作数据库的一系列增删改操作组成一个原子操作。
# 消费者事务相关配置
在消费端有一个参数isolation.level,与事务有关,这个参数的默认值为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。另外,需要设置enable.auto.commit = false来关闭自动提交Offset功能。
举个例子,如果生产者开启事务并向某个分区值发送3条消息msg1、msg2和msg3,在执行 commitTransaction()或abortTransaction()方法前,设置为 “read_committed”的消费端应用是消费不到这些消息的,不过在 KafkaConsumer内部会缓存这些消息,直到生产者执行 commitTransaction()方法之后它才能将这些消息推送给消费端应用。反之,如果生产者执行了abortTransaction()方法,那么 KafkaConsumer会将这些缓存的消息丢弃而不推送给消费端应用。
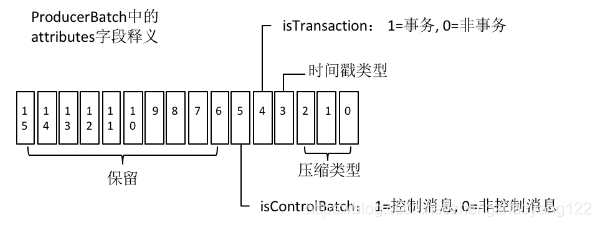
日志文件中除了普通的消息,还有一种消息专门用来标志一个事务的结束,它就是控制消息(ControlBatch)。控制消息一共有两种类型:COMMIT 和 ABORT,分别用来表征事务已经成功提交或已经被成功中止。RecordBatch 中 attributes字段的第6位用来标识当前消息是否是控制消息。如果是控制消息,那么这一位会置为1,否则会置为0,如上图所示。attributes字段中的第5位用来标识当前消息是否处于事务中,如果是事务中的消息,那么这一位置为1,否则置为0。由于控制消息也处于事务中,所以attributes字段的第5位和第6位都被置为1。
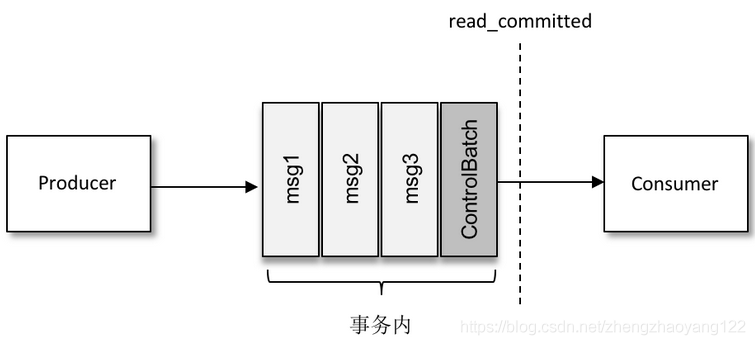
KafkaConsumer可以通过这个控制消息来判断对应的事务是被提交了还是被中止了,然后结合参数 isolation.level配置的隔离级别来决定是否将相应的消息返回给消费端应用,如上图所示。注意 ControlBatch对消费端应用不可见。
# 三、Kafka 事务原理
Kafka为了支持事务特性,引入一个新的组件:Transaction Coordinator。主要负责分配pid,记录事务状态等操作。下面时Kafka开启一个事务到提交一个事务的流程图:
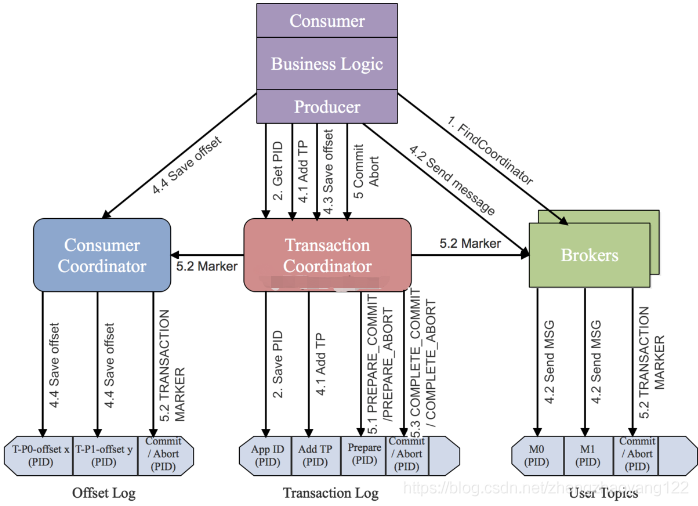
主要分为以下步骤:
【1】查找 Tranaction Corordinator: Producer向任意一个 Brokers发送 FindCoordinatorRequest请求来获取 Transaction Coordinator的地址。
【2】初始化事务 initTransaction: Producer发送 InitpidRequest 给 Transaction Coordinator,获取pid。Transaction Coordinator 在 Transaciton Log中记录这<TransactionId,pid>的映射关系。另外,它还会做两件事:
● 恢复(Commit 或 Abort)之前的 Producer未完成的事务
● 对 PID对应的 epoch进行递增,这样可以保证同一个 app的不同实例对应的 PID是一样,而 epoch是不同的。
只要开启了幂等性即必须执行 InitpidRequest,而无须考虑该 Producer是否开启了事务特性。
【3】开始事务beginTransaction: 执行 Producer的 beginTransacion(),它的作用是 Producer在本地记录下这个 transaction的状态为开始状态。这个操作并没有通知 Transaction Coordinator,因为 Transaction Coordinator只有在 Producer发送第一条消息后才认为事务已经开启。
【4】read-process-write流程: 一旦 Producer开始发送消息,Transaction Coordinator会将该<Transaction, Topic, Partition>存于 Transaction Log内,并将其状态置为 BEGIN。另外,如果该 <Topic, Partition>为该事务中第一个 <Topic, Partition>,Transaction Coordinator还会启动对该事务的计时(每个事务都有自己的超时时间)。
在注册<Transaction, Topic, Partition> 到 Transaction Log后,生产者发送数据,虽然没有还没有执行 commit或者 abort,但是此时消息已经保存到 Broker上了。即使后面执行 abort,消息也不会删除,只是更改状态字段标识消息为 abort状态。
【5】事务提交或终结 commitTransaction/abortTransaction: 在 Producer执行 commitTransaction/abortTransaction时,Transaction Coordinator会执行一个两阶段提交:
TIP
第一阶段,将 Transaction Log内的该事务状态设置为 PREPARE_COMMIT或 PREPARE_ABORT
第二阶段,将 Transaction Marker写入该事务涉及到的所有消息(即将消息标记为committed 或 aborted)。这一步骤Transaction Coordinator会发送给当前事务涉及到的每个<Topic, Partition>的 Leader,Broker收到该请求后,会将对应的Transaction Marker控制信息写入日志。
一旦Transaction Marker写入完成,Transaction Coordinator会将最终的COMPLETE_COMMIT或COMPLETE_ABORT状态写入Transaction Log中以标明该事务结束。