# 一、HW AND LEO
HW(High Watermark):俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。分区 ISR 集合中的每个副本都会维护自身的 LEO(Log End Offset):俗称日志末端位移,而 ISR 集合中最小的 LEO 即为分区的 HW,对消费者而言只能消费 HW 之前的消息。
TIP
LEO: 该副本底层 log文件下一条要写入的消息的位移,例如 LEO=10则当前文件已经写了了10条消息,位移是[0,10)。
HW: 所有分区已提交的的位移,一般HW<=LEO。
# 多副本下,各个副本中的 HW和 LEO的演变过程
某个分区有3个副本分别位于 broker0、broker1 和 broker2 节点中,假设 broker0 上的副本1为当前分区的 Leader 副本,那么副本2和副本3就是 Follower 副本,整个消息追加的过程可以概括如下:
【1】生产者客户端发送消息至 Leader 副本(副本1)中。
【2】消息被追加到 Leader 副本的本地日志,并且会更新日志的偏移量。
【3】Follower 副本(副本2和副本3)向 Leader 副本请求同步数据。
【4】Leader 副本所在的服务器读取本地日志,并更新对应拉取的 Follower 副本的信息。
【5】Leader 副本所在的服务器将拉取结果返回给 Follower 副本。
【6】Follower 副本收到 Leader 副本返回的拉取结果,将消息追加到本地日志中,并更新日志的偏移量信息。
某一时刻,Leader 副本的 LEO 增加至5,并且所有副本的 HW 还都为0。
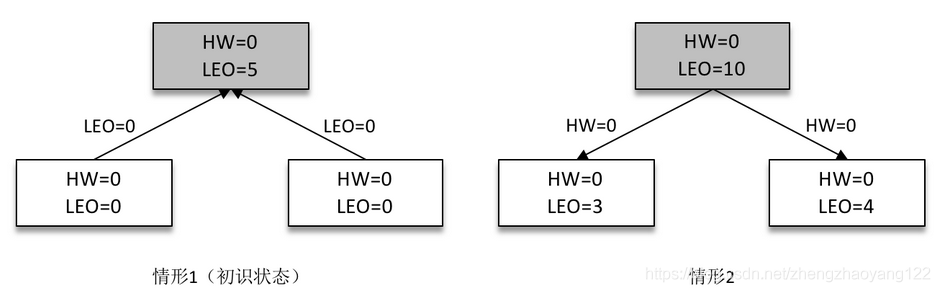
之后 Follower 副本(不带阴影的方框)向 Leader 副本拉取消息,在拉取的请求中会带有自身的 LEO 信息,这个 LEO 信息对应的是 FetchRequest 请求中的 fetch_offset。Leader 副本返回给 Follower 副本相应的消息,并且还带有自身的 HW 信息,如上图(右)所示,这个 HW 信息对应的是 FetchResponse 中的 high_watermark。
此时两个 Follower 副本各自拉取到了消息,并更新各自的 LEO 为3和4。与此同时,Follower 副本还会更新自己的 HW,更新 HW 的算法是比较当前 LEO 和 Leader 副本中传送过来的 HW的值,取较小值作为自己的 HW 值。当前两个 Follower 副本的 HW 都等于0(min(0,0) = 0)。
接下来 Follower 副本再次请求拉取 Leader 副本中的消息,如下图(左)所示。
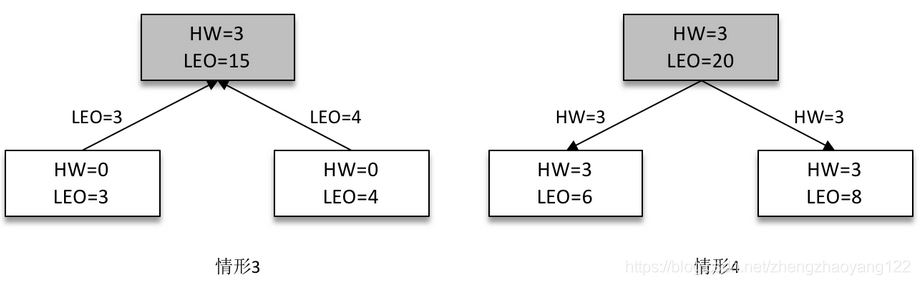
此时 Leader 副本收到来自 Follower 副本的 FetchRequest 请求,其中带有 LEO 的相关信息,选取其中的最小值作为新的 HW,即 min(15,3,4)=3。然后连同消息和 HW 一起返回 FetchResponse 给 Follower 副本,如上图(右)所示。注意 Leader 副本的 HW 是一个很重要的东西,因为它直接影响了分区数据对消费者的可见性。两个 Follower 副本在收到新的消息之后更新 LEO 并且更新自己的 HW 为3(min(LEO,3)=3)。
# 二、leader epoch
leader epoch 代表 Leader 的纪元信息(epoch),初始值为0。每当 Leader 变更一次,leader epoch 的值就会加1,相当于为 Leader 增设了一个版本号。每个副本中还会增设一个矢量 <LeaderEpoch >= StartOffset>,其中 StartOffset 表示当前 LeaderEpoch 下写入的第一条消息的偏移量。
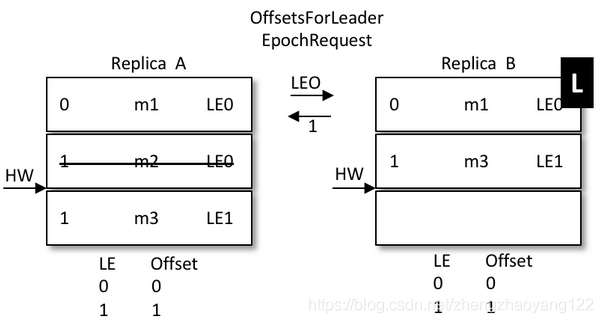
假设有两个节点A 和 B,B是 leader节点,里面的数据如图:
A发生重启之后,A不是先忙着截断日志而是先发送 OffsetsForLeaderEpochRequest请求给B,B作为目前的 Leader在收到请求之后会返回当前的 LEO(LogEndOffset,注意图中 LE0和 LEO的不同),与请求对应的响应为OffsetsForLeaderEpochResponse。如果 A 中的 LeaderEpoch(假设为 LE_A)和 B 中的不相同,那么 B 此时会查找 LeaderEpoch 为 LE_A+1 对应的 StartOffset 并返回给 A
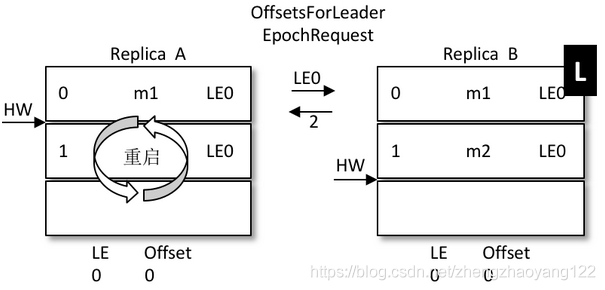
如上图所示,A 在收到2之后发现和目前的 LEO 相同,也就不需要截断日志了,以此来保护数据的完整性。
再如,之后 B 发生了宕机,A 成为新的 leader,那么对应的 LE=0 也变成了 LE=1,对应的消息 m2 此时就得到了保留。后续的消息都可以以 LE1 为 LeaderEpoch 陆续追加到 A 中。这个时候A就会有两个LE,第二 LE所记录的 Offset从2开始。如果B恢复了,那么就会从 A中获取到 LE+1的 Offset为 2的值返回给B。
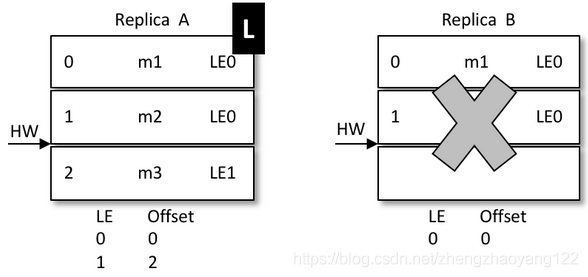
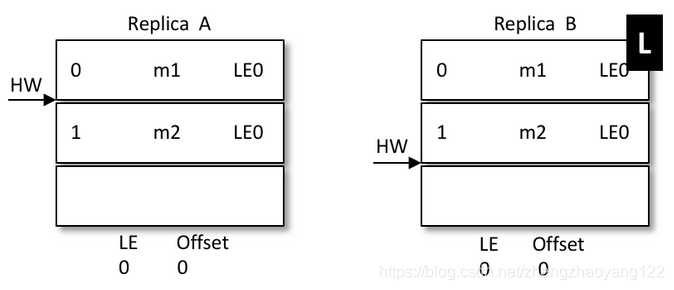
再来看看 LE如何解决数据不一致的问题:当前 A 为 Leader,B 为 Follower,A 中有2条消息 m1 和 m2,而 B 中有1条消息 m1。假设 A 和 B 同时“挂掉”,然后 B 第一个恢复过来并成为新的 leader。
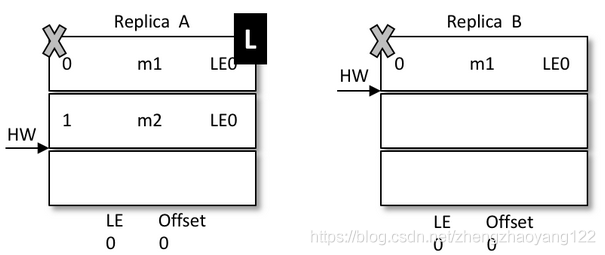
之后 B 写入消息 m3,并将 LEO 和 HW 更新至2,如下图所示。注意此时的 LeaderEpoch 已经从 LE0 增至 LE1 了。
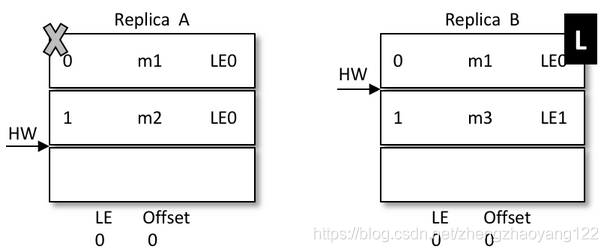
紧接着 A 也恢复过来成为 Follower 并向 B 发送 OffsetsForLeaderEpochRequest 请求,此时 A 的 LeaderEpoch 为 LE0。B 根据 LE0 查询到对应的 offset 为1并返回给 A,A 就截断日志并删除了消息 m2,如下图所示。之后 A 发送 FetchRequest 至 B 请求来同步数据,最终A和B中都有两条消息 m1 和 m3,HW 和 LEO都为2,并且 LeaderEpoch 都为 LE1,如此便解决了数据不一致的问题。