# 一、阻塞队列
【1】首先它是一个队列,而一个阻塞队列在数据结构中所起的作用大致如下图所示:
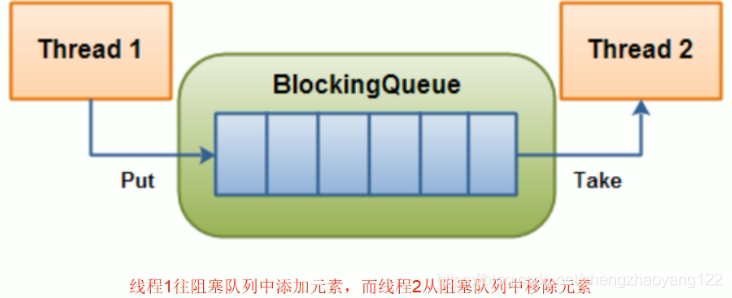
当阻塞队列为空时,从队列中获取元素的操作将会被阻塞。 当阻塞队列是满时,往队列中添加元素的操作将会被阻塞。
【2】在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤醒。
【3】为什么需要 BlockingQueue:好处在于我们不需要关心什么时候阻塞线程,什么时候需要唤醒线程,因为这一切 BlockingQueue 都给你一手包办了。
【4】在 concurrent 包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这个细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂性。
# 二、架构分析
【1】阻塞队列的架构图:阻塞队列与 List 具有很多类似之处,对比着学习会更加容易一些。
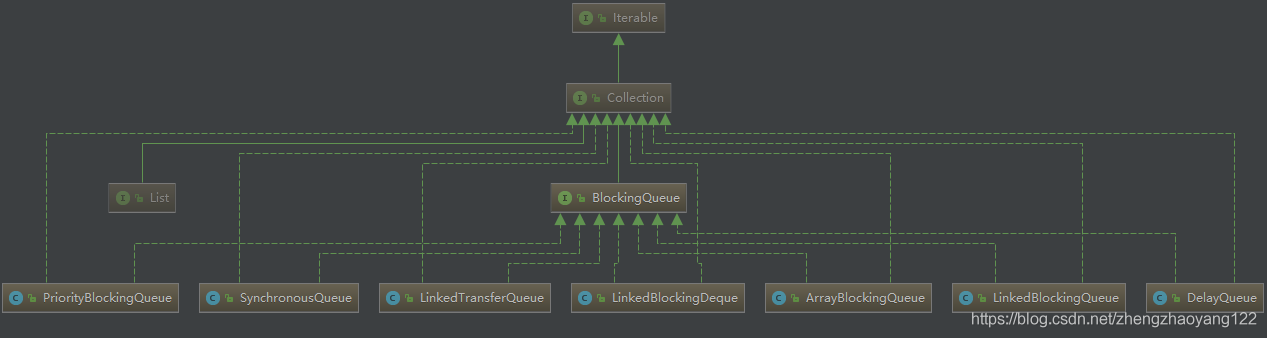
【2】阻塞队列重点子类说明:
■ ArrayBlockingQueue:由数组结构组成的有界阻塞队列。
■ LinkedBlockingQueue:由链表结构组成的有界(大小默认值为 Integer.MAX_VALUE <21亿左右,相当于无界>)阻塞队列。
■ PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
■ DelayQueue:使用优先级队列实现的延迟无界阻塞队列。
■ SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列。
■ LinkedTransferQueue:由链表结构组成的无界阻塞队列。
■ LinkedBlockingQeque:有链表组成的双向阻塞队列。
# 三、BlockingQueue 的核心方法
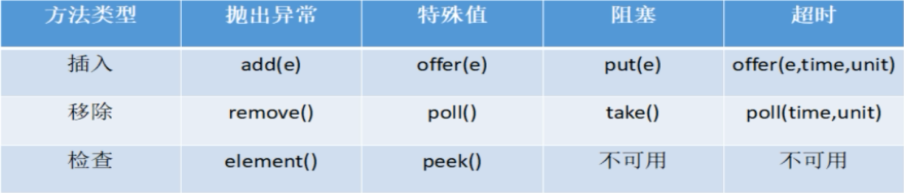
【1】 抛出异常:当阻塞队列满时,再往队列中 add 插入元素会抛出 IllegalStateException:Queuefull。当队列为空时,再从队列中 remove 移除元素会抛出 NoSuchElementException。实例如下:
public class BlockingQueueDemo {
public static void main(String[] args) {
//必须制定默认的大小,arrayList 不用指定是因为默认值为 10
ArrayBlockingQueue<String> blocking = new ArrayBlockingQueue<>(2);
//正常插入2个
blocking.add("a");
blocking.add("b");
//add 第三个是出现如下错误 java.lang.IllegalStateException: Queue full
//blocking.add("c");
//该方法会获取阻塞队列中,将要出队列的值。这里的 a
blocking.element();
//正常删除插入的两个值
blocking.remove();
blocking.remove();
//当阻塞队列中为空时,使用remove,出现如下错误 java.util.NoSuchElementException
//blocking.remove();
//如果为空值,则抛出 java.util.NoSuchElementException
blocking.element();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
【2】特殊值:使用插入方法 offer() 向阻塞队列中插入值时,阻塞队列未满,插入成功后返回 true。如果阻塞队列已满,则插入失败返回 false。使用移除方法 poll(),如果阻塞队列中有值,则移除成功返回队列的元素第一个元素,如果队列为空则返回 null 。
public class BlockingQueueDemo {
public static void main(String[] args) {
//必须制定默认的大小,arrayList 不用指定是因为默认值为 10
ArrayBlockingQueue<String> blocking = new ArrayBlockingQueue<>(2);
//正常插入2个返回 true
System.out.println(blocking.offer("a"));
System.out.println(blocking.offer("b"));
//offer 第三个是返回 false
System.out.println(blocking.offer("c"));
//该方法会获取阻塞队列中,将要出队列的值。这里的 a
System.out.println(blocking.peek());
//正常取出插入的两个值 a b
System.out.println(blocking.poll());
System.out.println(blocking.poll());
//当阻塞队列中为空时,poll 的到 null
System.out.println(blocking.poll());
//如果为空值,则为 null
System.out.println(blocking.peek());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
【3】一直阻塞:当阻塞队列满时,生产者继续向队列中 put 元素,队列会一直阻塞生产线程直到 put 数据或者响应中断。当阻塞队列为空时,消费者线程试图从队列中 take 元素,队列会一直阻塞消费者线程直到队列可用。
public class BlockingQueueDemo1 {
public static void main(String[] args) throws InterruptedException {
//必须制定默认的大小,arrayList 不用指定是因为默认值为 10
ArrayBlockingQueue<String> blocking = new ArrayBlockingQueue<>(2);
//正常插入2个返回 true
blocking.put("a");
blocking.put("b");
//put 第三时,线程会被阻塞,直到有人消费掉阻塞队列中的元素。
blocking.put("c");
//正常取出插入的两个值 a b
blocking.take();
blocking.take();
//当阻塞队列中为空时,take 会阻塞线程,直到队列中有元素
blocking.take();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
【4】超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,超过指定时间生产者线程会退出,并返回 false。当阻塞队列为空时,通过 poll 指定获取时间,超过时间后,消费者线程会退出,并返回 null。
public class BlockingQueueDemo1 {
public static void main(String[] args) throws InterruptedException {
//必须制定默认的大小,arrayList 不用指定是因为默认值为 10
ArrayBlockingQueue<String> blocking = new ArrayBlockingQueue<>(2);
//正常插入2个返回 true
blocking.offer("a");
blocking.offer("b");
//put 第三时,线程会被阻塞,直到有人消费掉阻塞队列中的元素。
System.out.println("开始第3 个元素插入==开始");
blocking.offer("c",3, TimeUnit.SECONDS);
System.out.println("开始第3 个元素插入==结束");
//正常取出插入的两个值 a b
blocking.poll();
blocking.poll();
//当阻塞队列中为空时,take 会阻塞线程,直到队列中有元素
System.out.println("开始第3 个元素获取==开始");
blocking.poll(3,TimeUnit.SECONDS);
System.out.println("开始第3 个元素获取==结束");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 四、SynchronousQueue
SynchronousQueue 没有容量,与其他 BlockingQueue 不同,SynchronousQueue 是一个不存储元素的阻塞队列。每一个put 操作必须要等待一个 take 操作,否则不能续集添加元素,反之亦然。
public class SynchronousQueueDemo {
public static void main(String[] args) {
SynchronousQueue<String> queue = new SynchronousQueue<>();
//创建两个线程对数据进行操作
//生产者线程,生产三个数据
new Thread(()->{
try {
System.out.println("插入第一个数据 A 线程名:"+Thread.currentThread().getName());
queue.put("a");
System.out.println("插入第二个数据 B 线程名:"+Thread.currentThread().getName());
queue.put("b");
System.out.println("插入第二个数据 C 线程名:"+Thread.currentThread().getName());
queue.put("c");
} catch (InterruptedException e) {
e.printStackTrace();
}
},String.valueOf("Product")).start();
//消费者线程,消费三个数据
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(3);
System.out.println("3秒后消费第一个数据 A 线程名:"+Thread.currentThread().getName());
queue.take();
TimeUnit.SECONDS.sleep(3);
System.out.println("3秒后消费第二个数据 B 线程名:"+Thread.currentThread().getName());
queue.take();
TimeUnit.SECONDS.sleep(3);
System.out.println("3秒后消费第二个数据 C 线程名:"+Thread.currentThread().getName());
queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},String.valueOf("Consumer")).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
输出结果展示:
插入第一个数据 A 线程名: Product
3秒后消费第一个数据 A 线程名:Consumer
插入第一个数据 B 线程名: Product
3秒后消费第一个数据 B 线程名:Consumer
插入第一个数据 C 线程名: Product
3秒后消费第一个数据 C 线程名:Consumer
2
3
4
5
6
# 五、ArrayBlockingQueue 与 LinkedBlockingQueue 区别
【1】底层实现:ArrayBlockingQueue : 底层基于数组实现,在对象创建时需要指定数组大小。在构建对象时,已经创建了数组。所以使用Array需要特别注意设定合适的队列大小,如果设置过大会造成内存浪费。如果设置内存太小,就会影响并发的性能。功能上,其内部维护了两个索引指针 putIndex和 takeIndex。putIndex表示下次调用 offer时存放元素的位置,takeIndex表示的时下次调用take时获取的元素。有了这两个索引的支持后,还是无法说明白其底层的实现原理。那么我们来看一段其内部出现最多的代码:
int i = takeIndex;
...
if (++i == items.length)
i = 0;
...
2
3
4
5
这几行在代码在 Array中几乎每个函数都会用到。意思不管是在读取元素,或者存放元素,如果到达数组的最后一个元素,直接将索引移动到第一个位置。你可能会想,如果我一直往队列中添加元素而不取,添加的元素个数超过了数组长度,会不会覆盖之前添加的元素。在实际使用过程中是不会出现这种情况的,其内部使用了ReentrantLock的Condition链接,这部分在并发支持中介绍。 LinkedBlockingQueue:底层基于单向链表实现。实现了队列的功能,元素到来放到链表头,从链表尾部取数据。这种数据结构没有必要使用双向链表。链表的好处(数组的没有的)是不用提前分配内存。Link也支持在创建对象时指定队列长度,如果没有指定,默认为Integer.MAX_VALUE。
【2】并发支持:最大的区别就是 Array内部只有一把锁,offer 和 take使用同一把锁,而 Link的 offer和 take使用不同的锁。
TIP
ReentrantLock 和 Condition的关系:ReentrantLock内部维护了一个双向链表,链表上的每个节点都会保存一个线程,锁在双向链表的头部自选,取出线程执行。而 Condition内部同样维持着一个双向链表,但是向链表中添加元素(await)和从链表中移除(signal)元素没有像 ReentrantLock那样,保证线程安全,所以在调用 Condition的 await()和 signal()方法时,需要在 lock.lock()和 lock.unlock()之间以保证线程的安全。在调用 Condition的 signal时,它从自己的双向链表中取出一个节点放到了 ReentrantLock的双向链表中,所以在具体的运行过程中不管 ReentrantLock new 了几个 Condition其实内部公用的一把锁。介绍完这个之后,我么来分析 ArrayBlockingQueue和 LinkedBlockingQueue的内部实现不同。
ArrayBlockingQueue:先看其内部锁的定义:
int count;
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
2
3
4
lock 是其内部锁,当调用阻塞队列的 offer时,会调用 notEmpty.signal() 通知之前因为队列空而被阻塞的线程。同时在 take后,如果内部计数器 count=0时,会调用 notEmpty.await() 阻塞调用 take的线程。当调用阻塞队列的 offer时,如果现在 count=内部数组的长度时,会调用 notFull.await()阻塞现在添加元素的所有线程;当调用 take时,总会调用 notFull.signal()唤醒之前因为队列满而阻塞的线程。根据上面分析 ReentrantLock和其 Condition的关系,可以看到放元素和取元素用的同一把锁,无法使放元素和取元素同时进行,只能先后相继执行。
LinkedBlockingQueue:内部锁定义:
/** Current number of elements */
private final AtomicInteger count = new AtomicInteger();
/** Lock held by take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
2
3
4
5
6
7
8
9
10
11
12
13
14
count 内部元素计数器使用的原子类型的计数器,使的元素个数的更新支持并发,为下面取和放元素并发提供了支持。takeLock 取元素单独的锁,和放元素分开,这样即使有 Condition也可以使的取和放元素在不同的节点上自选。notEmpty 取元素的Condition锁,和放元素锁分开。putLock notFull 和上面介绍的 takeLock notEmpty一致。通过这种设置,可以将在链表头上放元素和在链表尾部取元素不再竞争锁,在一定程度上可以加快数据处理。
为什么要这么设计呢?因为 ArrayBlockingQueue使用更简单的数据结构来保存队列项。ArrayBlockingQueue将其数据存储在一个私有的final E []items;array中。对于多个线程来处理相同的存储空间,无论是添加还是出列,它们都必须使用相同的锁。这不仅是因为内存障碍,还因为互斥体保护,因为它们正在修改同一个数组。 另一方面,LinkedBlockingQueue是一个队列元素的链接列表,它完全不同,允许有双重锁。队列中元素的内部存储启用了不同的锁配置。 我觉得还是因为**数组的入队和出队时间复杂度低,不像列表需要额外维护节点对象。**所以当入队和出队并发执行时,阻塞时间很短。如果使用双锁的话,会带来额外的设计复杂性,如 count应被 volatile修饰,并且赋值需要 CAS操作等。而且ArrayBlockingQueue是定长的,当putIndex==length时,putIndex会重置为0,这样入队和出队的 index可能是同一个,在这种情况下还需要考虑锁之间的通讯,参考读写锁。